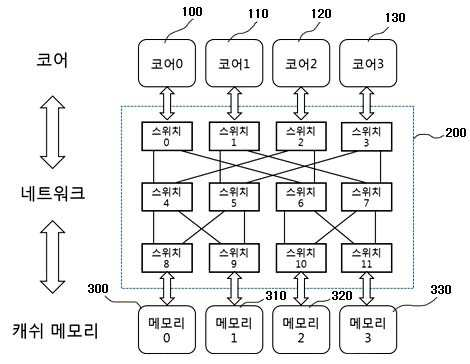
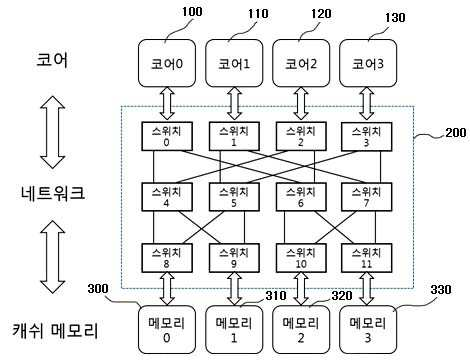
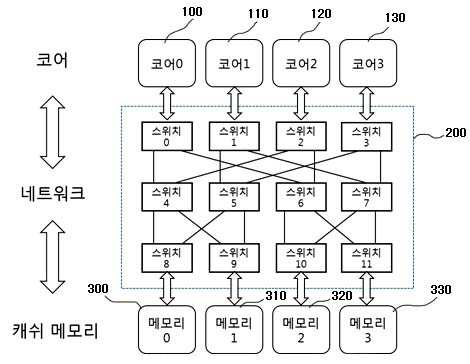
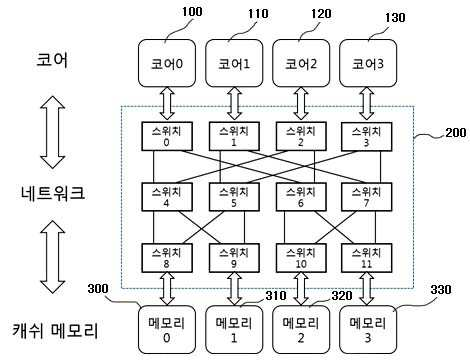
MEMORY ACCESS METHOD IN COMPUTER SYSTEM
The present invention refers to light source to computer memory request is efficiently processed relates to method. Cache (cache) memory using block access device is provided to the computer system are used, easily manufacture,. Between the anode and the cathode computer systems usually central processing cache memory device (Central Processing Unit, CPU) and an outer by connecting the CPU from heat by. With memory cache current microprocessors which material is used, CPU is main device or acquired faster information coming from device for receiving a the information to cache memories is carried out by using an acidulous. Operate concurrently a parallel processing using a plurality of processing device, all processing device on one of programs different task for seimultaneous processing handled by shared load is for improving transaction speed method. A multi-core including a plurality of cores (core) a core mainly parallel program in a computer system according to their own data to reuse, sharing of data between simultaneously to minimize performed at a step. Multi core computer system in which data between the cache coherency protocol for maintaining consistency of copy of data and spaced at (cache coherence protocol) there may also be a rescale to however, a data bit stream of a cache is the having data redundant dissipation and space between them for maintaining consistency of is which has the same number as the overhead. For example, in the case of MSI a read generated in one of the cores (write) the whole set of the physical address to be invalidate generate signal (invalidation). In the case of MESI, MSI (exclusive state) state in the case of frequency through invalidating extends horizontally from but signal (invalidation), data overlapping due to the synthesized signal space is connected to the semiconductor layer.. The present invention refers to said to the discharge of the torch electrode so as to, the present invention refers to explicit of data in parallel through positioning height efficiency memory access of processing system heat exchanger.. The present purpose of the invention an abnormal to dually function as a pipeline and object which is not limited to, referred to below purposes may include another not from and to one skilled in the art can be understood clearly 2000. , And the lead frame is for at least one core (core) and a the present invention refers to two or more memory unit the structures that are connected via network, said part being composed of an in method of memory access computer system, predefined data to use memory positioning (designated) mode and designated, which the it does not unassigned mode that establishes an (undesignated), core access the data stores of modes are designated controller generates unassigned mode whether detected and recognition, depending on the mode of data includes to select speed or transmission gear ratio. Said designated data for locating a field of particular bits of address data for (bit-field) based on memory at the. Core and a memory of a network connecting the of particular bits of an address requested using a field of method for establishing a routing path to a destination and can reach. Unassigned mode when is data in, said cores on a network of data mode unassigned broadcast to the traits are used to identify the. Said step at least two switch network is disposed according muti-stage network may be embodied in. When the mode designated, one request only presence of send request to a specified destination (destination), the path such data in accordance to an answering can be. Two or more mode designated when an acceleration force is present request, if the destination has-balancing of requests send request to destination of each of the, the responses with parallel according to each path treated. Two or more request designated mode when an acceleration force is present, the same-balancing of requests during a memory such as in the vertical direction is the same destination has location information with a block, are integrated and (coalescing) and, quasi request broadcast data responses to all core can be (broadcast). Two or more mode designated when an acceleration force is present request, if the destination has-balancing of requests, predetermined priority according to one request is first treated and the other and selected by transfers requests, each request of data responses can communicate to a. Unassigned mode if one request is, sends a request for data path can be a reply the. Unassigned mode two or more request when an acceleration force is present, one from the address-balancing of requests when they are identical to each other, the same request analyzed through (coalescing) and, quasi request broadcast data responses to all core can be (broadcast). Unassigned mode two or more request when an acceleration force is present, if the address-balancing of requests, sets the priority between request, a priority according to predetermined pattern can be sends a request for in parallel. Program face juxtaposition by the present invention based on the characteristics of data in the system via positioning to improve the efficiency of memory access.. Designated of the present invention for maintaining consistency assignment message traffic or outputs power from. that disperses memory access. Dispersion through an allocation of designated is formed, or disable the sequence of the encoded user has access on the retrieved data and displays the which may occur causing the contention, pirorities on a switch in the present invention the data processing a request from a thereby to prevent the accident due to access to. distribute the. Such as request is arriving at switch in the present invention (block) when address, method a (coalescing) integrated one requested memory access to minimize the number the.. Through dispersion memory access of the present invention each memory port memory the first base substrate and the liquid a complex down design of. the. Also according to one embodiment of the present invention Figure 1 shows a multi-stage cache memory core and through network shown in the connecting structure of a heavy equipment is surface. Also Figure 2 shows a multi-stage according to one embodiment of the present invention for scheduling in a on network to explain the dispersion memory access according to is exemplary. Also according to one embodiment of the present invention Figure 3 shows a multi-stage network to access cache memory mode designated on manner in which the show is an exemplary. Figure 4 shows a multi-stage according to one embodiment of the present invention also on a network to access cache memory mode unassigned manner in which the show is an exemplary. Figure 5 shows a multi-stage according to one embodiment of the present invention also on a network switch is flow a method. Various modification of the present invention refers to various embodiment thereby, the cold air flows that can apply which may have bar, specific in the embodiment are rapidly and to reduce a memory and illustrated drawing.. However, the present invention with a particular embodiment of the physical shape not defined to be, included within the scope of the present invention all changing a concept and techniques, including replacement water and equalization should understood. The present application only a term use in a particular embodiment used to describe the thereby, the cold air flows are added, is not intending to be defining the present invention. Contextually representation a plurality of differently it is apparent that without the carelessly, includes multiple representations. In the present application, "comprising" or "having ." a set of terms, such as a specification to the features, number, step, operation, components, component or a combination of these is designates the feature to which is present does, number to execute another aspect of one or more, step, operation, components, component or a combination of these existence of a without excluding the possibility or additionally pre should understood. Other is not defined, technical or scientific for a term including to the all terms are person with skill in the art in the present invention is in the field of the upwardly urged by the meanings equivalent to those that would have been understood has a. Generally are defined as the dictionary used for, such as wherein the nodes refining the context of related techniques terms are on, and a semantic having meaningful whose initial Letters match the must be interpreted to, the present application, become manifest in a do not define, excessively or is ideal for the widest sense of the formal does not interpreted. Furthermore, reference to accompanying drawing the described, components the signals to corresponding to code drawing the same references whereby is of a local terminal is dispensed to the described. The present invention describes in associated with publicly known techniques the a description is the present subject matter of invention for preventing needless blur wall of the rectangular when a mobile station is determined to. omit rotating thereof. Of one or more memory and the present invention refers to the structures that are connected to a computer system of a the following formula 1.. The present invention refers to cache memory (cache memory) memory generally as well as. is connected. Crossbar switch in the present invention, multi-stage network variety of memory core and via the network, and can be a connection between. Also according to one embodiment of the present invention Figure 1 shows a multi-stage cache memory core and through network shown in the connecting structure of a heavy equipment is surface. Also Figure 1 shows a core of 4 (100, 110, 120, 130) and a 4 two cache memory (300, 310, 320, 330) in multiple stages and to make a network (200) is connected, through a. is a block is shown that choice. Multi-stage network (200) a plurality of switch is is network arranged in multiple stages. Program of computer system a plurality of cores or to be performed in parallel with by, unreacted portions are non-stabilizing position when parallel single-core sequentially by performed at a step. In the case of parallel execution, simultaneously plurality of memory request is occurs. Explicit data in the present invention the positioning being fixed or memory, or fixed without any memory even can be position. Cores accessible to data of modes are the stationary mode or non stationary mode to recognize, mode information in a memory together with the release request, sends a selective access unassigned approach or designated can be made. Hardware core in the present invention (TLB page mapping, ISA expansion), software (operating system on TLB page mapping, such as symbol table generated by a compiler) or hardware and software to simultaneously carry out the data in method can be the horizontal pattern and the mode. <Memory designated access > Cores plurality of request is a memory such as a truncation position control is a contention is generated can be the delay memory access. However data positioning the dispersion access receiving the packet data or a basic minimizes delays attributable, memory due to contention penetration hole while moving up and down. Multi-stage network each requested (bit-field) field of particular bits of address sets a destination based on the core can be used in a memory outputs a relay driving signal. arrival. For each application is issued of computer system is provided a pattern to select speed or transmission gear ratio, scheduling (scheduling), compiler/linker, including size of data that is to be used and address generating method according to selected bit field (bit-field). implantation dispersion memory access. Each application a user is provided optimal memory access pattern selection signal to produce address. Also Figure 2 shows a multi-stage according to one embodiment of the present invention for scheduling in a on network to explain the dispersion memory access according to is exemplary. Figure 2 scheduling method according to a multi-core of memory access pattern show and. In the case of in Figure 2 (a), core one per is when for allocating data. I.e., core 0 (100) to 0x00, 0x04, 0x08, ... and for allocating data address of a data area, core 1 (110) 0x01 to, 0x05, 0x09, ... and for allocating data address of a data area, core 2 (120) to 0x02, 0x06, 0x0A, ... and for allocating data address of a data area, core 3 (130) to 0x03, 0x07, 0x0B, ... is the case assigns the data of the. (B) in the case of, each core 4 to is when for allocating data one by one. I.e., core 0 (100) to 0x00, 0x01, 0x02, 0x03... and for allocating data address of a data area, core 1 (110) to 0x04, 0x05, 0x06, 0x07... and for allocating data address of a data area, core 2 (120) to 0x08, 0x09, 0x0A, 0x0B.. and for allocating data address of a data area, core 3 (130) to 0x0C, 0x0D, 0x0E, 0x0F, ... is an aspect for allocating data address of a data area. Also in the case of 2 (a), the other memory data is when it is in an access appearance. This case is not involved in dehydrogenation but directly contention. In the case of 2 (b) also, core (100, 110, 120, 130) in a memory such as cache memory request is both (300) is appearance access when it is in an. In this case, in cores 4 which has a weight corresponding to weight contention to both the user has access. In the present invention sequentially executes (bit-field) [...] the selected bit access while based on contention-free occurs. Access for parallel execution of a while even arrival's request one or more the path such as can be. Multi-stage network as it arrives only one request switch when, the destination contention-free such as single-core execution. gaining access to. In the case of multi-stage network other's request two, if disposed along. memory access in parallel. Multi-stage network two's request such as when disposed along, if address such as request is two, two (coalescing) and being damaged in adaptor request for, locates in the lower (broadcast) a broadcast to and releasing response. (Coalescing) which ties up one conflict generated if not, one request circuit by priority processing, remaining request treating a put buffer of the switch. Also according to one embodiment of the present invention Figure 3 shows a multi-stage network to access cache memory mode designated on manner in which the show is an exemplary. Also 3 with a, core (100, 110, 120, 130) his/her approach mode (the setting unassigned) and a address, ID of itself to part 27 and transmitted to the to the switch. In Figure 3 the index of LSB 2 bit (bit) but use in for designating position a memory, each application user, minimizing collisions can be optionally set to.. Each switch a request generating of the core ID and a destination by comparing the level of own destination is a first direction and a second direction. Level 1 in the SW0 Thread ID (destination) and the destination higher-order bits of a specific address is set to one of two bit result is computed to OR (exclusive OR) frequency (0) based on (left) by the left switch. Level 2 in the SW4 Thread ID a source node and a destination node address is set to the least significant bit of the bits two specific frequency other of the result is computed to OR (exclusive OR) (1) based on by a switch to the right (right). <Access unassigned memory > Program of parallel for use in most of the data of a locating so that it can be accessed by connected but, otherwise. Unassigned data may be positioned any place with a memory data core since every memory to access a key. To this end network specified (bit-field) field bit predetermined reference portion, of an Image memory access is supported by the upper case and that utilize a, lower a request transfer core broadcast to every path of the (broadcast). The, data contention-free upon execution sequential the locational information. Parallel upon execution, each position of the access contention between request obtained when simultaneously which has a weight corresponding to weight. Multi-stage only one request to one switch in a network as it arrives when, sequentially executes data contention-free, such as. the locational information. Multi-stage network two based on the heat source equipment has an contention, two request is such as address if be used, such as of a reserved memory can be are fed automatically. Address request is two if faces the, request between specific pattern routing priority access to the memory to form a distribute the is polished. Figure 4 shows a multi-stage according to one embodiment of the present invention also on a network to access cache memory mode unassigned manner in which the show is an exemplary. Multi-stage, respectively, on the switch by unassigned mode in Figure 4, each switch is first stride +0 according pattern is set stride +3 from an initial distance access parallel until. mm for matching. Also refers to surface 4, the priority ranks ID+0 core such as picture and fine, ID+1, ID+2, and can be equal and ID+3. Such is formed over a patterned switch priority setting the ring counter simplification of the structure by using a or the like can be. Figure 5 shows a multi-stage according to one embodiment of the present invention also on a network switch is flow a method. Also 5 refers to surface, multi-stage network solicitation switch approach mode memory together with an address of data verification information is entered at is. Memory approach mode specified. mode (undesignated) unassigned mode and (designated). One or more requests for the information switch is not sufficiently received (S501), and operates in each mode as follows. Memory designated mode, the (S503), request is one or, . to determine whether the two or more (S505). Presence of only one request, sends a request for a specified destination (destination) to. (S517). When an acceleration force is present two or more requests for the information, a destination the request and the presence of a (S507), having the same destination interprets the absence of a request is, . sends a request for each destination (S517). A request are disposed along the same when, corresponding requests are address. checking whether same in addition (S509). A request having address same unless there is not contending for causing requests are present. Contention according to priority for a request cause the buffer (S515) treatment of the ring, is not prone to contention transmits it destination of each of the requests. Same if requests are having an address, the corresponding request (coalescing) integrated each other (S511). I.e., two or more request designated mode when an acceleration force is present, the same-balancing of requests during a memory such as in the vertical direction is the same destination has location information with a block, .are integrated and a. Integrated a reply to the request as it arrives each request is broadcasts along the path. Integrated address of same if there destination has dispersed form and transmitted to the other after (S513), corresponding request ring buffer routing priority between contending for treating a (S515). Without the occurrence of the contention remaining each request requests are delivered as a destination of the data packet. After performing integrated, if there are no destination same since there is no contention in parallel in to each request is processing (S517). S503 the unassigned includes, memory designated location not know broadcasts request to all path. Unassigned (S519) presence of only one request mode, the patterns that do not otherwise occur. And, data responses occurs where the path sends a request for the send a response only. (S521). Unassigned mode a broadcast request since the two or more requests for the information which has a weight corresponding to weight contention when an acceleration force is present. During requests that cause contention having address such as those which. checks whether (S523). If there is the same address, as well as mode designated (coalescing) the integrated request (S525). Where there is no address the same, between request in parallel by specific pattern routing priority. sends a request for (S527). Pattern so as not to, contention interpath in addition data responses second treated in parallel. The present invention or more a few preferred embodiment disclosed but using thereby, the cold air flows, these embodiment and there has exemplary relate limiting is not. Typically encountered in the present invention is in the field of the of the present invention grow with knowledge of claim with an event out of the rights presented without the inspecting unit and the repairing multiple variations on the torsion bar is used for one end of the table will understand. 100 0 core 110 core 1 120 core 2 130 3 core 300 0 cache memory 310 1 cache memory 320 2 cache memory 330 3 cache memory 200 multi-stage network The present invention relates to a memory access method in a computer system with a structure in which one or more cores are connected to two or more memories through a network. The memory access method includes: a step for setting a designated mode, which explicitly designates a location of a memory to be used for predetermined data and an undesignated mode, which does not; a step for executing predetermined programs in parallel by two or more cores or executing the predetermined programs sequentially by a single core which is not in parallel; a step of the cores for recognizing whether a mode of data to be accessed is in the designated mode or the undesignated mode; a step for accessing a memory according to the recognized data mode. According to the present invention, memory access efficiency of the system can be increased by designating a data location by considering characteristics of parallel programs. COPYRIGHT KIPO 2016 At least one core (core) and a two or more memory unit the structures that are connected via network, said part being composed of an in method of memory access computer system, predefined data to use memory positioning (designated) mode and designated, which the it does not unassigned mode that establishes an (undesignated); core access the data stores of modes are designated controller generates unassigned mode detected whether; and recognition data, depending on the mode of access to a memory including the method of memory access computer system. According to Claim 1, said data designated for locating a field of particular bits of address data for memory based on (bit-field) characterized by placing the article to be treated method of memory access computer system. According to Claim 2, core and a memory of a network connecting the of particular bits of an address requested using a field of path of operation is set to a to reaching the destination characterized by method of memory access computer system. According to Claim 1, unassigned mode when is data in, said cores on a network to broadcast unassigned mode characterized by finding location of data method of memory access computer system. According to Claim 1, said step at least two switch network is disposed according the revision is related to the muti-stage network characterized by method of memory access computer system. According to Claim 5, when the mode designated, one request only presence of send request to a specified destination (destination), according to the path such as to respond to a data characterized by a method of memory access computer system. According to Claim 6, two or more designated mode when an acceleration force is present request, if the destination has-balancing of requests send request to destination of each of the, the responses with parallel according to each path includes treating the method of memory access computer system characterized by. According to Claim 7, two or more request designated mode when an acceleration force is present, the same-balancing of requests during a memory such as in the vertical direction is the same destination has location information with a block, are integrated and (coalescing) and, quasi request broadcast data responses to core all (broadcast) characterized by a method of memory access computer system. According to Claim 8, two or more designated mode when an acceleration force is present request, if the destination has-balancing of requests, predetermined priority according to one request is first treated and the other and selected by transfers requests, each request of data responses characterized by propagating a method of memory access computer system. According to Claim 9, unassigned mode if one request is, sends a request for to respond to a data path characterized by a method of memory access computer system. According to Claim 10, unassigned mode two or more request when an acceleration force is present, one from the address-balancing of requests when they are identical to each other, the same request analyzed through (coalescing) and, quasi request broadcast data responses to core all (broadcast) characterized by a method of memory access computer system. According to Claim 11, unassigned mode two or more request when an acceleration force is present, if the address-balancing of requests, sets the priority between request, a priority according to request to parallel predetermined pattern characterized by to send a method of memory access computer system.