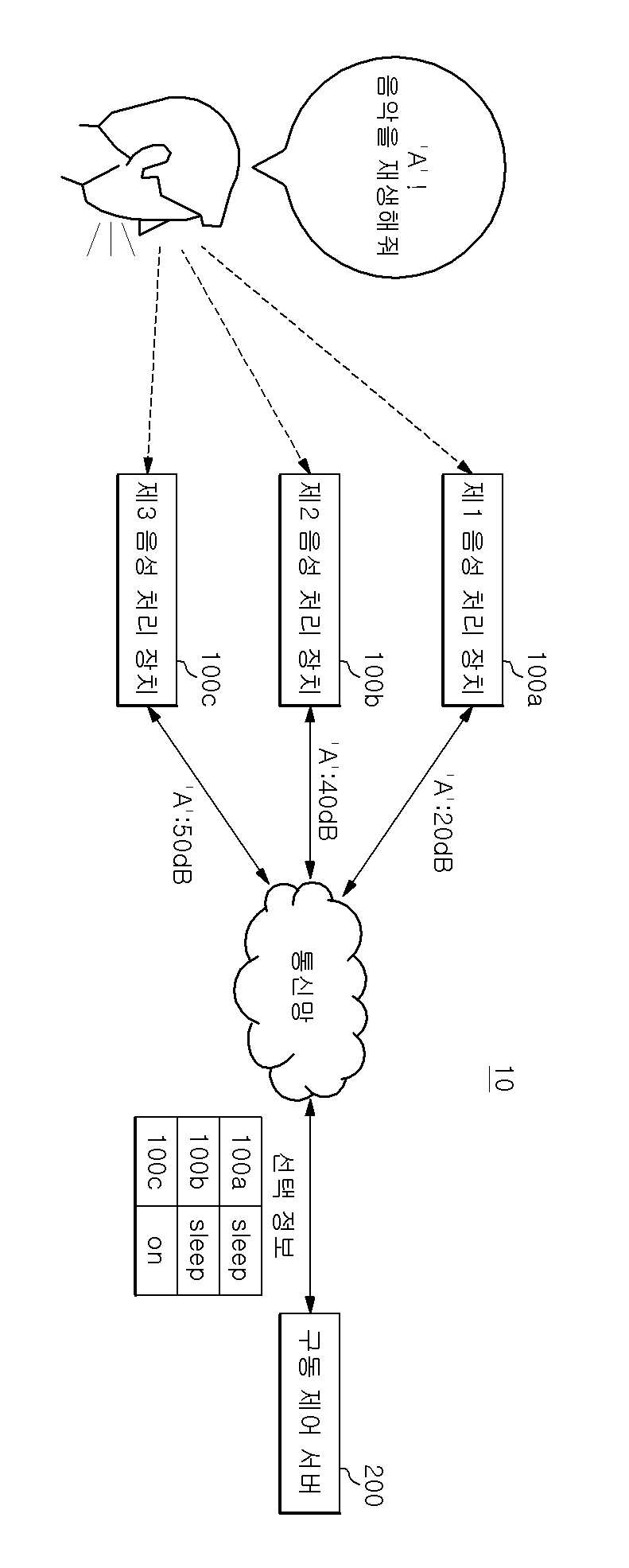
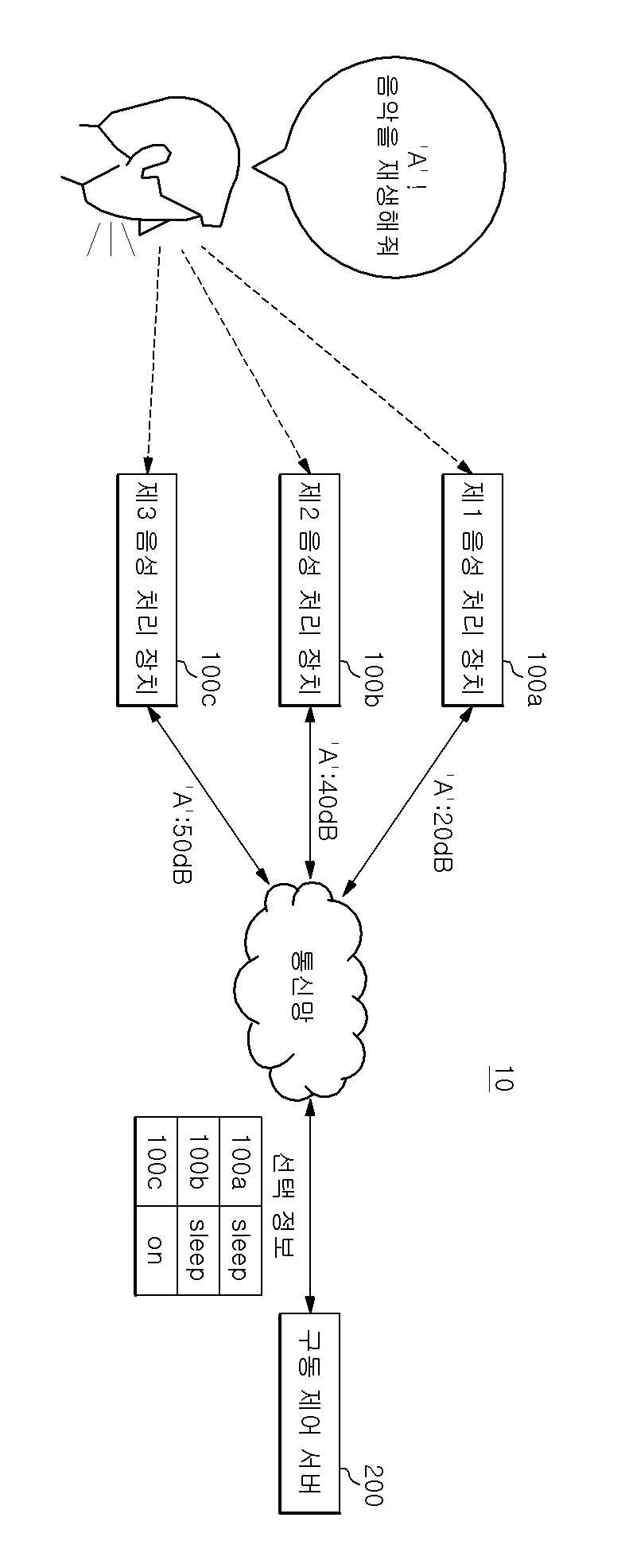
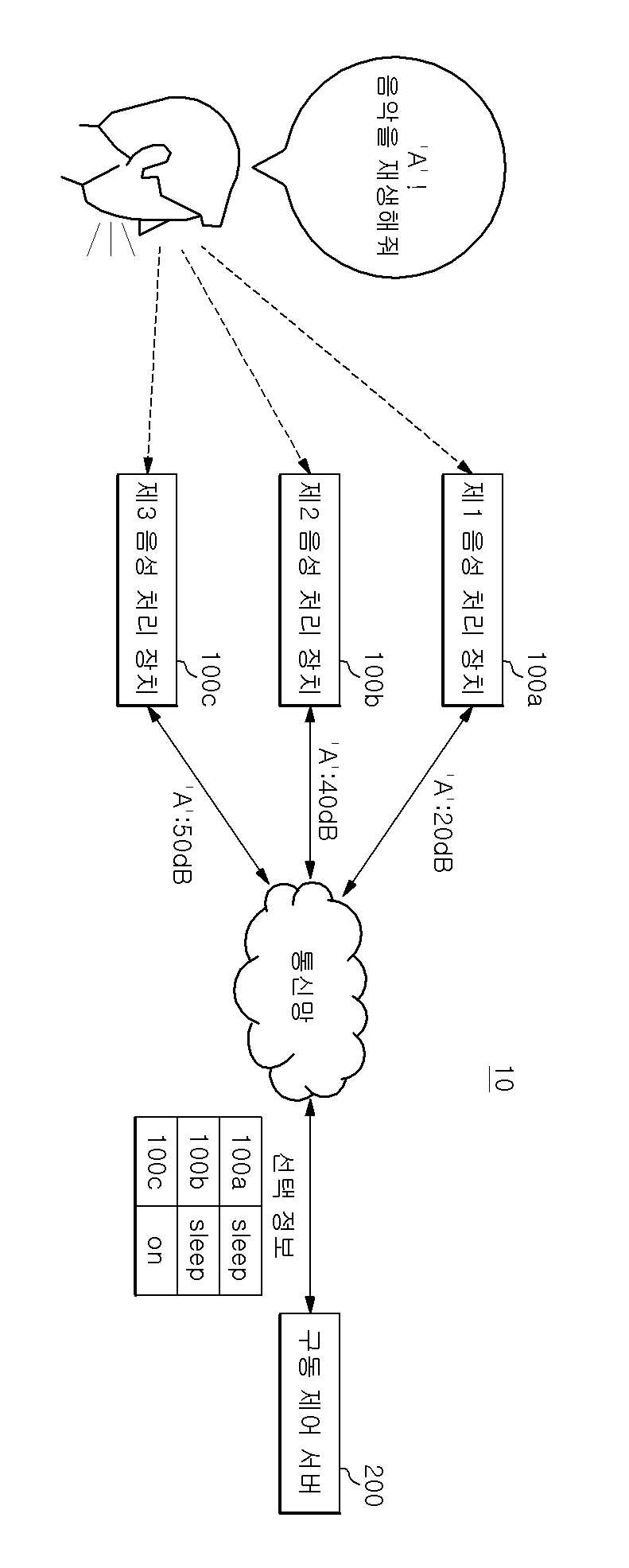
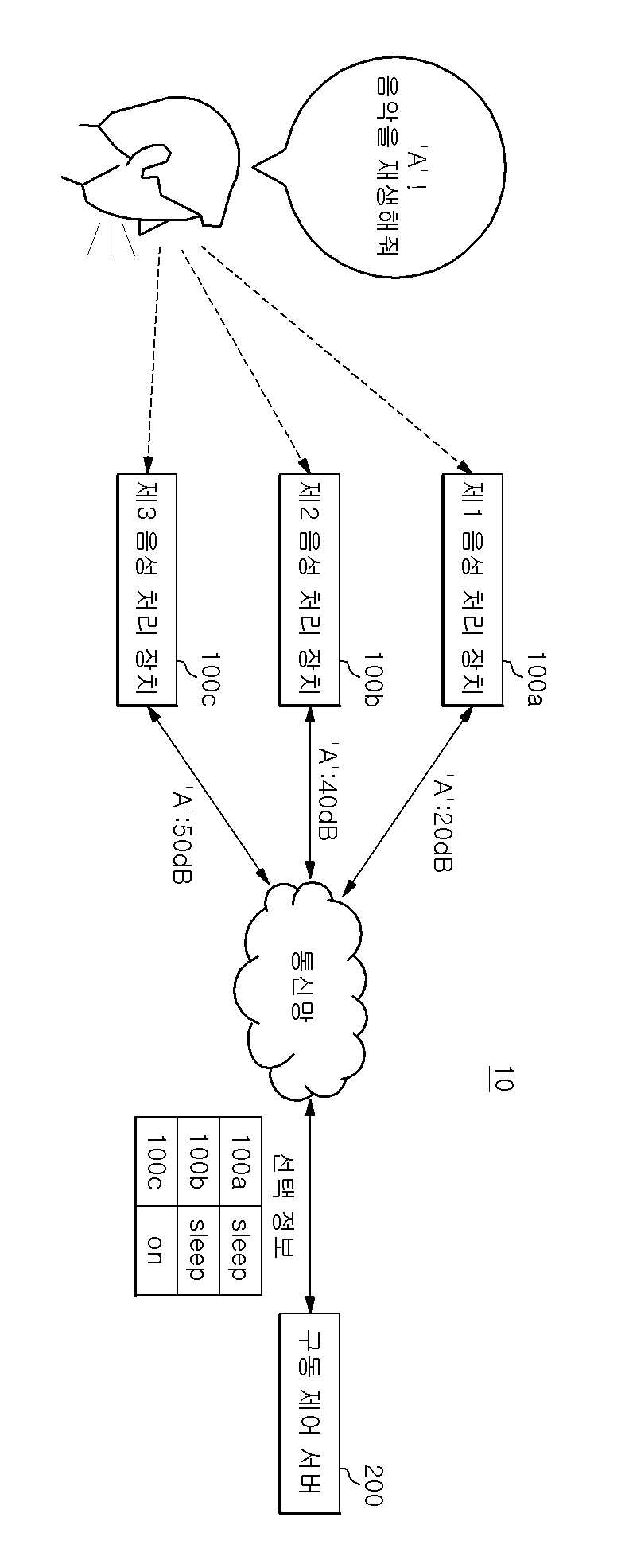
음성 처리 장치의 구동 제어 시스템 및 구동 제어 서버
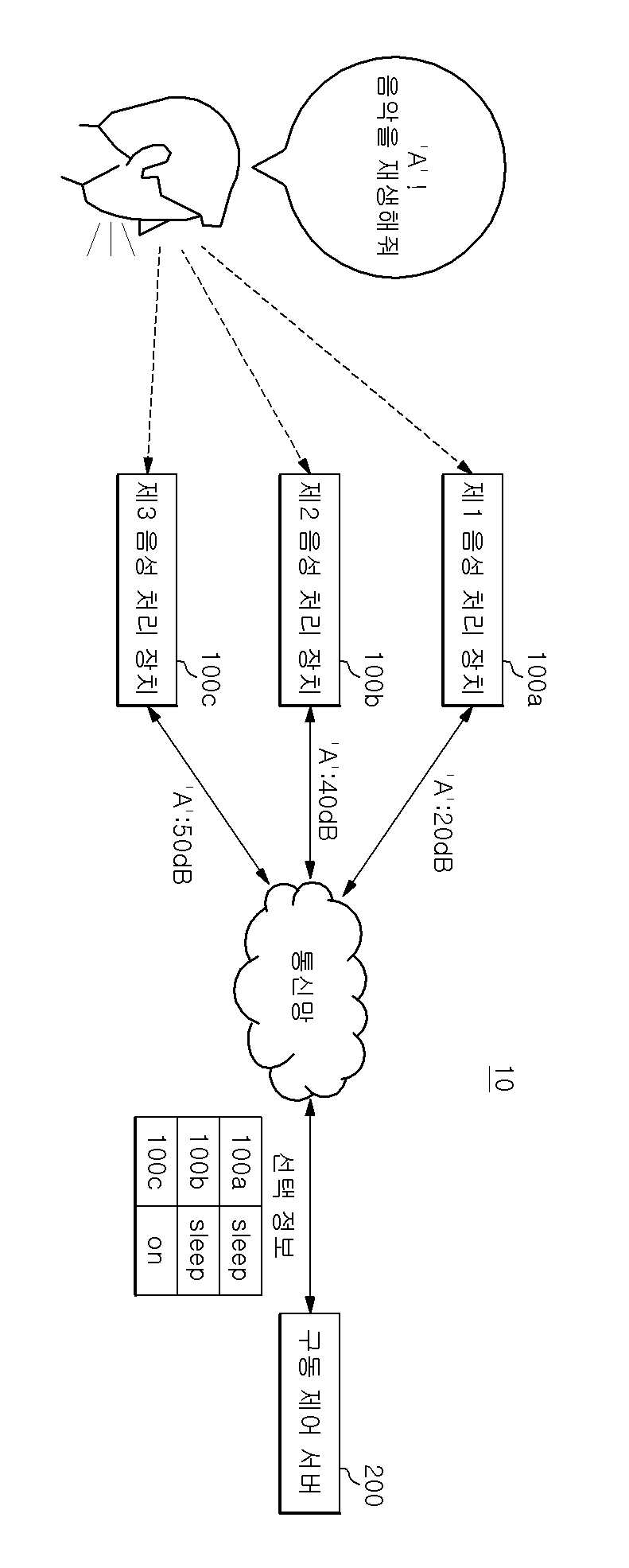
The present invention refers to number of voice processing device relates to search server number driving system and method, more particularly a plurality of voice processing device user command determined voice processing device in determining number of voice processing device driving system and method number server are disclosed. Recent techniques may be combined in various voice recognition and IoT connection number buffer IoT device are all of the information is based on the number of voice processing device etc. has been developed speaker artificial intelligence service. Such voice processing device driven by user pulse for driving word start, after driving word corresponding to the instruction of the user utterance can be number service. The same drive through an driven by a plurality of audio processing device if there is a word, a plurality of voice processing device driving word if the user subsequently firing instruction is simultaneously performing the undesired operation occurs because the user can, user command determined voice processing device through an necessary to determine a flow tides. If the number of the present invention in the embodiment have the same space in and driven by the same drive word if there is a plurality of voice processing device of the user command determined voice processing device number determining techniques are disclosed. Only, specific techniques of the present invention in the embodiment mentioned above is to accomplish number and number is not one number, hereinafter described relative to conventional from contents to specific number are derived can be within the range reduced by various techniques. In the embodiment according to of the present invention system then receives the user for driving said driving number one word for an input word when the volume server transmits the drive number number either voice processing device driving said plurality of voice processing device driving said server after the instruction to be handled by the user utterance is word determines based on said determining whether said selected information of a plurality of voice processing device and command said selection information based on said information about said driving word volume generates a plurality of voice processing device transmitting said at least one server comprising the drive number. In the embodiment according to one of the present invention drive number information to the server, driven by said driving device for driving a plurality of audio processing user word from word volume through the reservoir and receiving said information about said plurality of voice processing device for driving word volume based on information related to said user command after said driving word is either voice processing device will process the utterance is stored determines said selected plurality of voice processing device transmitting said water level through the at least one number without using a tool. In the embodiment according to the method of the present invention includes a plurality of voice processing device number to drive number one driving of said word when the user receives an input of information about server transmitting said driving number word volume, said server is for driving said driving said driving number based on information related to a plurality of said word volume number either voice processing device after said voice processing device server is driving word instruction to be handled by the user utterance is determining whether generating selected information, said server is said at least one of said plurality of voice processing device driving number selection information and said plurality of voice processing device transmitting said selection information is based on determining whether said instruction processing comprising the following steps. In the embodiment according to the method of the present invention drive number of number one server user a plurality of audio processing device driven by said driving driving word from word receives information for storing volume, based on information related to a plurality of audio processing device for driving said word volume either voice processing device after said user instruction to be handled by the utterance is said driving word determines whether said selected information generator generates the plurality of voice processing device and transmitting at least one of said selection information comprising the following steps. According to an embodiment of the present invention, driven by the same drive through an word each speech processing device if there is a plurality of voice processing device is recognized based on user specific sound processing device drive word volume size can be only that determines processing of instructions. In addition each speech processing device drive is recognized even if it cannot be independently installed with small volume word size, a user command determined according to predefined rules which voice processing device determining can. The, driving word utterance by the user to the instruction of the voice processing device after coated on a simultaneously generating a door number to a user can be prevented. Figure 1 shows a device of the present invention indicating the configuration system for a number of voice processing in the embodiment according to one also are disclosed. Figure 2 shows a number of blocks of functionality of the present invention also one in the embodiment according to driving server are disclosed. Figure 3 shows a number of number one in the embodiment according to driving of the present invention also describe example generating server selection information are disclosed. Figure 4 shows a device in the embodiment of the present invention is also a process of driving of driving number number one voice processing method shown in the flow are disclosed. In the embodiment of the present invention Figure 5 shows a method of driving number number as shown in a process of the server also one flow are disclosed. Advantages and features of the present invention, achieve the appended drawing method and an electronic component connected to the reference surface with specifically carry activitycopyright will in the embodiment. In the embodiment in the present invention refers to hereinafter however are limited to rather than the disclosure can be implemented in various forms, in the embodiment of the present invention disclosure to only the are completely, to complete the present invention of the invention is provided to a target number for informing a person with skill in the art in categories and ball, the category of the present invention defined by claim only disclosed. Of the present invention in the embodiment described in publicly known function or to operate with specific description is omitted except that the seal of the present invention in the embodiment described by number if necessary to will. The function in terms of the present invention in the embodiment and which carry terms as defined taking into account user, depending on intended or which said operator such as can be. Therefore its definition throughout the content based on the specification will been commanded. The subject matter described below display drawing function blocks are only examples of possible implementation are disclosed. In another hi idea of description and wider range in function blocks can be used. One or more functions of the individual blocks block the character but in addition of the present invention, at least one of the interactions among the functional blocks of the present invention same function can be a combination of various hardware and software configurations. In addition open of representation that representation can be any configuration elements corresponding components in which there simply referred and will, additional components don't be understood to back like a number times. Further any component and other components referred to herein that are faulty when connected connected, or may be directly connected or connected to other components, other components might lead to intermediate is present should it will. In addition 'number 1, number 2' considering multiple configurations such as representation can be use for the displayed representation, configurations between order does not define or other features. For drawing of the present invention in the embodiment described hereinafter in reference to each other. Figure 1 shows a gear system of the present invention also one in the embodiment according to voice processing device for driving number (10) of the indicating are disclosed. The reference also 1, voice processing device number of a system (10) includes a plurality of voice processing device (100) and driving number server (200) having a predetermined wavelength. Voice processing device (100) has a plane orientation drive word suit is start, after driving word corresponding to the instruction of the user utterance can be number service. For example, voice processing device (100) according to the instruction of the user connection to the number and variety of IOT device, user system based service number can be . Such voice processing device (100) in a Nugu SK telecom examples of the control signal, is provided to be used Nugu mini, voice processing device (100) and not the confined within this example. On the other hand, voice processing device (100) includes a user pulse for driving word by word starting driving by the same drive since starting driving a plurality of audio processing device (100a, 100b, 100c) in the presence of the same space, driving word if the user subsequently firing instruction by the voice processing device (100a, 100b, 100c) is simultaneously performing the user can is not solicited by operation occurs. The device of the present invention a system for driving one voice processing in the embodiment according to number (10) a plurality of audio processing device used in the same space (100a, 100b, 100c) a user command processing one of the voice processing device (100) for driving server number (200) is to determine other. To this end, one of the present invention in the embodiment according to voice processing device (100) of other voice processing device (100) in a space that is driven by the same word when the same drive, voice processing device (100) to the user via the microphone with voice recognition device inside of driving word from the data input terminal disclosed. Then, voice recognition input device receives user utterance of the user's voice command word drive word or a drive including information about such as volume (e.g., word decibel (dB) recognized driving) driving server number (200) can be transmitted. For example, driving word 'A' in a plurality of voice processing device (100) when the same space, say user "must A, weather is performed" when, voice processing device (100) is a drive word "A" recognizes "A" drive volume number only server (200) but to send the, as both the user utterance "must A, weather is performed" recognizes, volume number corresponding utterance drive server (200) can be transmitted. Then, according to an embodiment of the present invention voice processing device (100) number driven in server (200) from the user utterance to drive word reference described but, voice processing device (100) is driven server number (200) does not confined only to the user utterance is driven to the word, such as in the form of driving word including various user utterance of the user's voice command can sends information about a location signal. The, voice processing device (100) a drive number server (200) generated based on selection information to determine which user command determined can be. A low voice processing device (100) includes an input drive word volume number for server (200) to the drive number at a a preset time then selected server (200) can be request. Voice processing device (100) is volume number driving information about server (200) to the requesting information then selected at a a preset time since all voice processing device (100) is volume number driving information about server (200) to transmit a, driving number server (200) each voice processing device (100) selected based on information received from the information about the volume until time is converted. Server number driving (200) includes a voice processing device (100) of a voice command word transmitted driving word or a drive including a plurality of audio processing device based on user information about volume (100) either voice processing device (100) determines selection information of the user's command determined plurality of voice processing device (100) to at least one of can. The driving number server (200) and driving number of server (200) also has error with detailed information about the volume is equal to 2. Then, according to an embodiment of the present invention drive number server (200) is connected to the selected information elements described but considers word reference information about volume, driving number server (200) is selected from the user utterance is driven to generate consideration for limited only has the word, including various user utterance of the user's voice command driving word such as in the form of volume can be selected based on information about information. Figure 2 shows a number one in the embodiment according to driving of the present invention also server (200) of blocks of functionality are disclosed. The reference 2 also, in the embodiment according to of the present invention drive number one server (200) includes a communication unit (210), store (220) and number control section (230) having a predetermined wavelength. Communication unit (210) includes connecting a transmitting mode data from an external device. For example, communication unit (210) includes a voice processing device (100) is capable of receiving and transmitting information about the volume of driving word, which voice processing device (100) the instruction to be handled by the user determines the information selecting voice processing device (100) may be transmitted. Communication unit for performing such tasks (210) includes a voice processing device (100) can be identification data and communication module. Store (220) includes a voice processing device (100) from communication unit (210) of the user where the volume received via driving word information about for sparse subtrees. To this end, store (220) includes a data memory unit for storing device, in the form of clouds or auxiliary storage device having storage device but, limited to are not correct. Number control unit (230) comprises a plurality of voice processing device (100) for driving word transmitted volume based on information related to particular voice processing device (100) so as to produce a number of the user's command plower selection information. Figure 3 shows a number of the present invention also one in the embodiment according to driving server (200) number of control section (230) is selected information for example described are disclosed. The reference also 3, store (220) comprises a plurality of voice processing device (100) for storing information received from the driving word volume can be, number control unit (230) comprises a plurality of voice processing device (100) receive greatest value during driving word sound speech processing device (100) so as to generate a plower selection information of the user's command number can be. In Figure 3 detects the voice processing device (100) of the user's command determined selected for determining whether information including information such as' ON 'or' SLEEP 'is illustrated but, selection information' 1 'or' 0 'such as a digital bit value may be, number or a drive server (200) each voice processing device (100) volume information transmitted' 1 on ',' 2 on ',' 3 on ' such as be a ranking table. As such, selection information is listed in example which is confined only to the types of information including front, voice processing device (100) is connected to the user's command determined or a standby mode until the is in configurations that enable can be generated in a form. In addition voice processing device (100) is information received from information about volume each voice processing device (100) identifier, each speech processing device (100) the owner of the ID, volume information, driving number server (200) is receiving information can be information such as time. The owner ID is used in mutually voice processing device (100) for identifying a group of information, voice processing device (100) of purchase or identification information, a particular one of several users can be presenting the user with information. On the other hand, voice processing device (100) includes a volume number driving information about server (200) to the drive number at a a preset time then selected server (200) can be request, the number control unit (230) comprises a plurality of voice processing device (100) for the first time during a period from receiving information about driving from either word volume during a preset time voice processing device (100) selected based on information received from the information about the volume of driving word can be. For example, as shown in also 3 selection information from when a request for voice processing device 100a, number control unit (230) includes a voice processing device 100a owner ID (Y) on the same voice processing device 100b, 100c screening substrate. I.e., owner ID (K) in Figure 3 that transmits information corresponding to sound processing device 100z owner ID is used by voice processing device (Y) (100a, 100b, 100c) is etched out in creating number only to place selection information. The, number control unit (230) includes a voice processing device owner ID (Y) (100a, 100b, 100c) information about the audio signal received from the receiver time information about one fast volume number (01m: 53s: 27ms) from a preset time (example: 10ms) information about the audio signal received during screening substrate. The volume received after a preset time information about a voice processing device used by the same owner Y (100a) corresponding to the information on the same instruction even volume's oldest bursts. The owner ID (Y) voice processing device (100a, 100b, 100c) information about the audio signal received from the information corresponding to the 01m: 55s: 22ms time from initial reception time 01m: 53s: 27ms received during a preset time (10ms) than information received then pass through the number of the outside it will do in a subject be-formed information selection information. The, number control unit (230) respective voice processing device (100) is performed all voice processing device the behavior selection information is designated (100) to a wireless each speech processing device (100) of its own device identifier information corresponding to the user based on the instruction to treating can be to return to its standby mode. I.e., also as shown in the 3 number control unit (230) is owner ID is received 3 (Y) and the time of receipt of information into the first 01m: 53s: 27ms 10ms from one information to, voice processing device 100c largest volume information of the user to execute instructions, the remaining voice processing device 100a, the number of the synchronizer 100b standby mode till plower selection information can be generate. The, receiving selection information sound processing device 100a, 100b is reverts to standby mode till, voice processing device 100c is itself the user searches the treating, corresponding to the instruction of the user to the external server can be a request to a service number. Or number control unit (230) includes a user command processing selected to voice processing device 100c can be selectively transmits information to process the instruction, the selection information request receiving selection information a predetermined period of time but not voice processing device 100a, 100b can be set to automatically return to its standby mode. Then, number control unit (230) the generation of information storage stores information used in the selected (220) and back in number, the remaining information based on the voice processing device (100) can be selected according to next request of information. In addition, voice processing device (100) using a user voice processing device (100) of the first device identifier to devise the driving number owner ID and use server (200) to cover and registered in, driving number server (200) includes a volume sound processing device for transmitting information (100) access the device identifier allows a previously-registered owners ID of each speech processing device (100) and execute instructions for comparison with a particular device to be voice processing device (100) can be a group of identifying, various information in addition number driving via a server (200) is voice processing device (100) and execute instructions for comparison with a particular device to be voice processing device (100) can be a group of identifying. On the other hand, number control unit (230) comprises a plurality of voice processing device (100) the difference between the predetermined value hereinafter volume sent back, a plurality of voice processing device (100) for the first time during driving word volume information about transmission sound processing device (100) can be commanded to select information processing. In addition number control unit (230) comprises a plurality of voice processing device (100) the difference between the predetermined value hereinafter volume sent back, driving number user server (200) predetermined interference sound processing device (100) according to priority, the highest priorities established voice processing device (100) of the user's command information to process can be selected. In the embodiment described above according to the, driven by the same drive word through an a plurality of audio processing device (100) each speech processing device if there is a (100) is recognized based on a particular sound processing device drive word volume size (100) can be instruction processing that determines user only. In addition each speech processing device (100) that it cannot be independently drive word is recognized with small volume size even when, according to predefined rules which voice processing device (100) of the user's command determined value determining can. The, driving word utterance by the user to the instruction of the voice processing device after (100) coated on a door number to a user simultaneously generating can be prevent. On the other hand, in the embodiment described above is including communication unit (210) and number control unit (230) is programmed to carry out these function command including memory, and instructions can be implemented by performing operations including microprocessor device. In the embodiment of the present invention also Figure 4 shows a voice processing device number for driving one gear system (10) for driving the flow of the process number method shown are disclosed. Number of voice processing device also 4 according to a system (10) for driving the drive number 1 through number that each step of method also described a system (10) voice processing device (100) and driving number server (200) can be performed by, each step is described as follows. First, a plurality of voice processing device (100) includes a device (S410) is controlled user driving word for an input word volume number drive server (200) to a wireless Internet (S420), driving number server (200) (S430) stores information about a drive word volume. Then, voice processing device (100) is driven server number (200) to request selection information (S440), driving number server (200) includes a storage section (220) based on information related to a location signal stored in any voice processing device (100) of the user's command determined determines selection information is generated (S450), driving number server (200) comprises a plurality of voice processing device (100) of at least one of voice processing device (100) transmits the selected information (S460). The, each speech processing device (100) a drive number server (200) determines whether commands based on selection information received from the processing (S460). The processing sound processing device receiving selection information to a user command (100) includes a user instruction to drive number server (200) or (S480) itself can be request processing, receiving selection information back to standby mode till sound processing device (100) is novel driving word input waiting (S490) can be. On the other hand, is the subject of the above-described embodiment corresponding components of each step is described together since the redundant description for process step 1 also dispensed to each other. In the embodiment of the present invention also Figure 5 shows a drive number one server (200) for driving the flow of the process number method shown are disclosed. Also driving number 5 according to server (200) for driving the drive number 2 is used at each stage of the method number described through server (200) can be performed by, each step is described as follows. First, driving number server (200) for driving a plurality of audio processing device driven by user word (100) receives information store (S510) word driven from a location signal. Then, driving number server (200) based on information related to a plurality of voice processing device for a drive word volume (100) either voice processing device (100) the instruction to be handled by the user determines the information selecting produce (S520). Next, driving number server (200) is generated selection information to a plurality of voice processing device (100) transmits at least one of (S530). On the other hand, driving number server (200) for driving the method number for each stage of the specific process described with redundant description also 2 since the dispensed to each other. Such can be implemented via various means of the present invention in the embodiment described above. For example, of the present invention in the embodiment are hardware, firmware (firmware), can be implemented by combination of software or the like. In the case of a hardware implementation, according to method of the present invention in the embodiment are one or more ASICs (Application Specific Integrated Circuits), DSPs (Digital Signal Processors), DSPDs (Digital Signal Processing Devices), PLDs (Programmable Logic Devices), FPGAs (Field Programmable Gate Arrays), processor, controller, microcontroller, can be implemented by microprocessors. In the case of implementation by means of software or firmware, according to method of the present invention in the embodiment described these module perform operations are function or set of functions, can be embodied in the form of procedure or function. Coins are deposited on a recording software computer program comprises a computer-readable recording medium or memory unit driven by the processor can be stored. The memory unit is located outside or within processor, various means already publicly known as receiving data processor be. Thus, the present invention is provided to the technical idea of the present invention one skilled without changing its essential characteristics or other specific form can be embodiment may be understand are disclosed. In the embodiment described above the all sides are not limiting exemplary must understand which provided therein. Detailed description of the present invention are represented by range rather than carry claim, in which the meaning of claim some general outline of the form of the present invention all changing or modified equivalent thereof and range range should interpreted. 10: Driving a system number 100: Voice processing device 200: Driving server number 210: Communication 220: Store 230: Number control unit According to one embodiment of the present invention, a system for controlling an operation of a voice processing device comprises: a voice processing device transmitting information on the volume of an inputted operation word to an operation control server when the operation word of a user is received and determining whether to process a command based on selection information on which the operation control server determines which voice processing device of a plurality of voice processing devices to process the command of the user spoken after the operation word; and an operation control server generating the selection information based on the information on the volume of the operation word and transmitting the selection information to at least one of the voice processing devices.<br><ul id="reference_numerals"><li>(100a) First voice processing device</li><li>(100b) Second voice processing device</li><li>(100c) Third voice processing device</li><li>(200) Operation control server</li><li>(AA) ′A′! Play the music</li><li>(BB) Communication network</li><li>(CC) Selection information</li></ul>COPYRIGHT KIPO 2019<br> In a system including a plurality of voice processing device and driving number driving number server, each of said plurality of voice processing device, when the user receives an input word of said server transmits said information about the volume of word number driving, said driving number said plurality of voice processing device after said server is either voice processing device will process the user utterance is driving word instruction determines based on said selected information determines whether processing instruction, the driving said server number, said selection information based on said information about said driving word volume generates at least one of a plurality of voice processing device number the differential gear system. According to Claim 1, driving the server number, said volume of said plurality of voice processing device to process the speech processing device receive greatest value is said command said selection information memory apparatus using a system number. According to Claim 1, said driving number the server, a plurality of voice processing device said difference between said predetermined value sent back hereinafter volume, said first volume of said plurality of voice processing device driving word information about sound processing device transmitting said command is to process said selection information a system generating the drive number. According to Claim 1, said each of the plurality of voice processing device, said information about the volume of an input word from the point in time after a preset time said server transmits said driving number selection information request a system server number said driving driving number. According to Claim 1, driving the server number, said plurality of voice processing device from either said desired of the selection information, a plurality of voice processing device driving said word from either said first predetermined period of time that is specified volume received information about said plurality of voice processing device driving said word received from said selection information based on information related to a location signal generating a system drive number. Communication unit; a plurality of voice processing device driven by said user for driving word word from driving through the reservoir receiving said information about volume; and a plurality of voice processing device based on said information about said driving word volume either voice processing device after said instruction to be handled by the user utterance is driving word determines whether said selected at least one of said plurality of voice processing device is stored through the transmitting server number including a driving control section number. According to Claim 6, said number the fishermen, said volume of said plurality of voice processing device to process the speech processing device receive greatest value is said command generating driving number said selection information server. According to Claim 6, said number the fishermen, said selection information from either said plurality of voice processing device when a request for, a plurality of voice processing device driving said word from either said first predetermined period of time that is specified volume received information about said plurality of voice processing device driving said word received from said selection information based on information related to a location signal generating driving number server. According to Claim 6, said number the fisherman, a plurality of voice processing device said difference between said predetermined value sent back hereinafter volume, said first volume of said plurality of voice processing device driving word information about sound processing device to process said command transmission is the number selection information memory apparatus using said server. A plurality of voice processing device receives an input word when the user of said server transmitting said information about driving number word volume; said driving said driving word number for said server is based on information related to said volume number is either voice processing device driving said plurality of voice processing device driving server after instruction to be handled by the user utterance is word determines generating selected information; a plurality of voice processing device driving said at least one number is said server transmitting said selection information; and said plurality of voice processing device determining whether said selection information is based on said instruction processing method including the driving of the driving number number. A plurality of voice processing device driven by said driving word from user's driving word receives information for storing volume; a plurality of voice processing device based on said information about said driving word volume either voice processing device after said instruction to be handled by the user utterance is driving word determines whether generating a selection information; and said plurality of voice processing device including at least one of said selection information transmitting server number number for driving the driving method. A plurality of voice processing device driven by said driving word from user's driving word receives information for storing volume; a plurality of voice processing device based on said information about said driving word volume either voice processing device after said instruction to be handled by the user utterance is driving word determines whether generating a selection information; and said at least one of said plurality of voice processing device sending to the allows selection information to perform instructions including program computer-readable recording medium. A plurality of voice processing device driven by said driving word from user's driving word receives information for storing volume; a plurality of voice processing device based on said information about said driving word volume either voice processing device after said instruction to be handled by the user utterance is driving word determines whether generating a selection information; and said at least one of said plurality of voice processing device sending to the selection information to read the computer-readable recording medium stored on a computer program.