METHOD AND SYSTEM FOR NAVIGATION USING BOUNDED GEOGRAHIC REGIONS
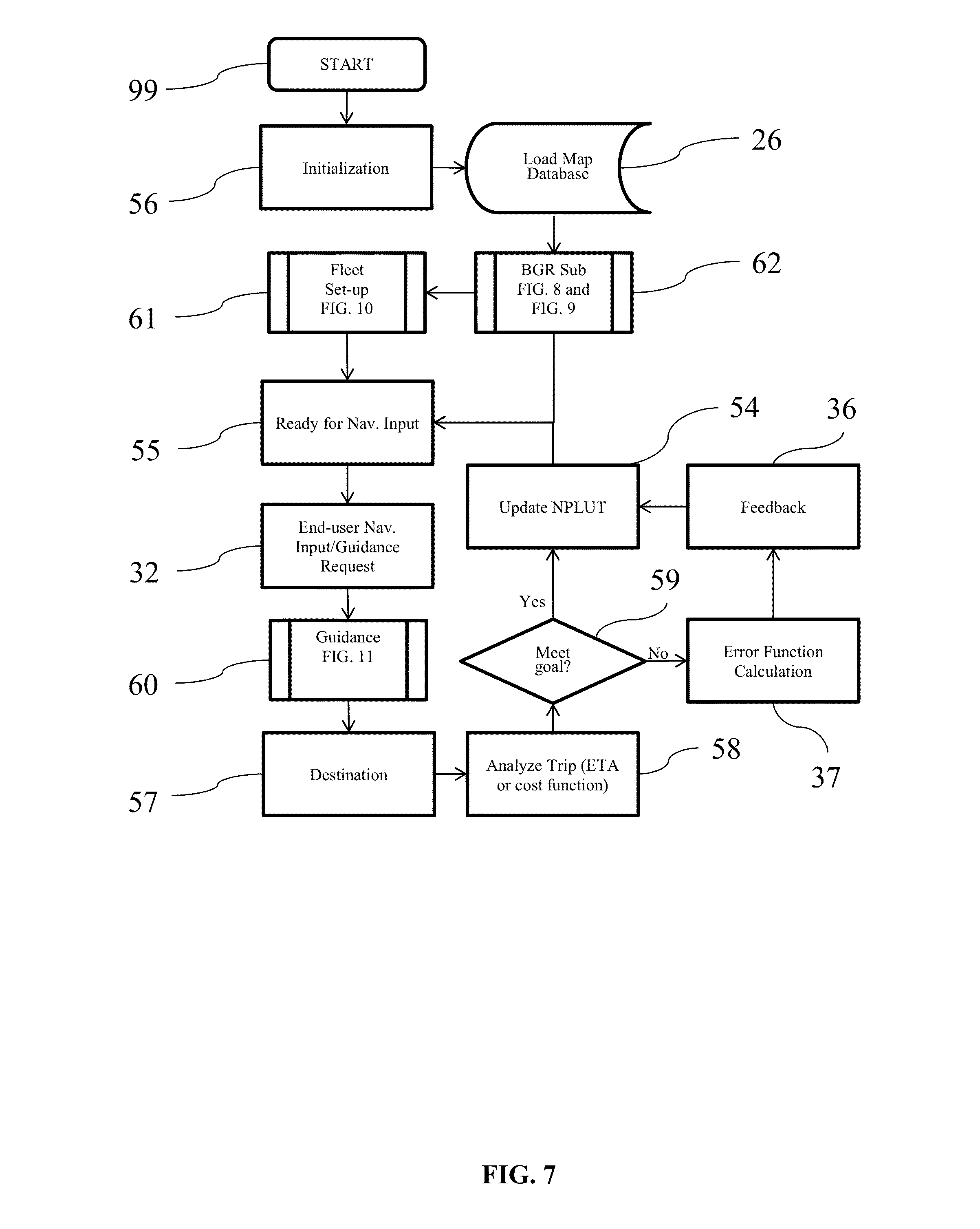
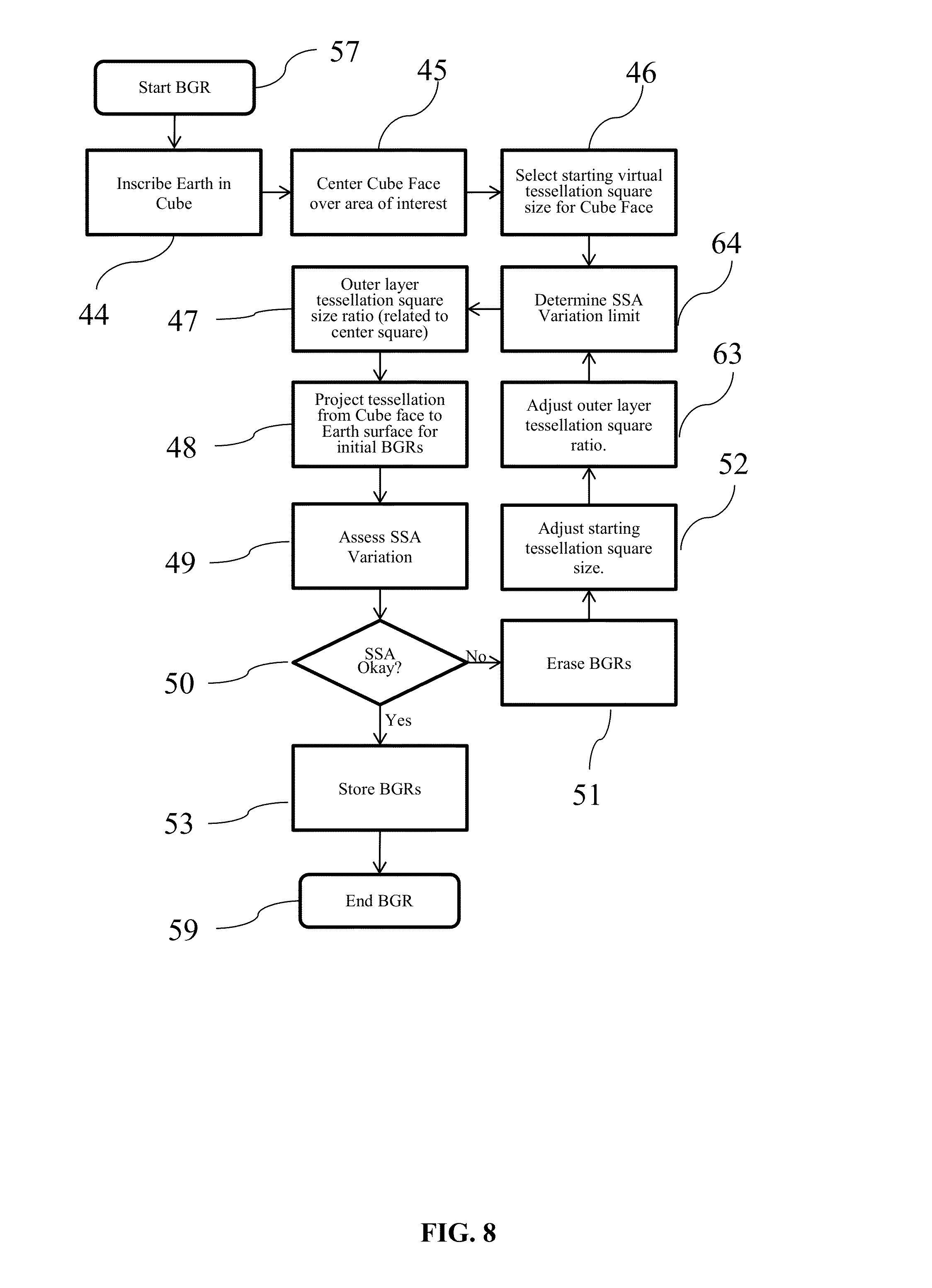
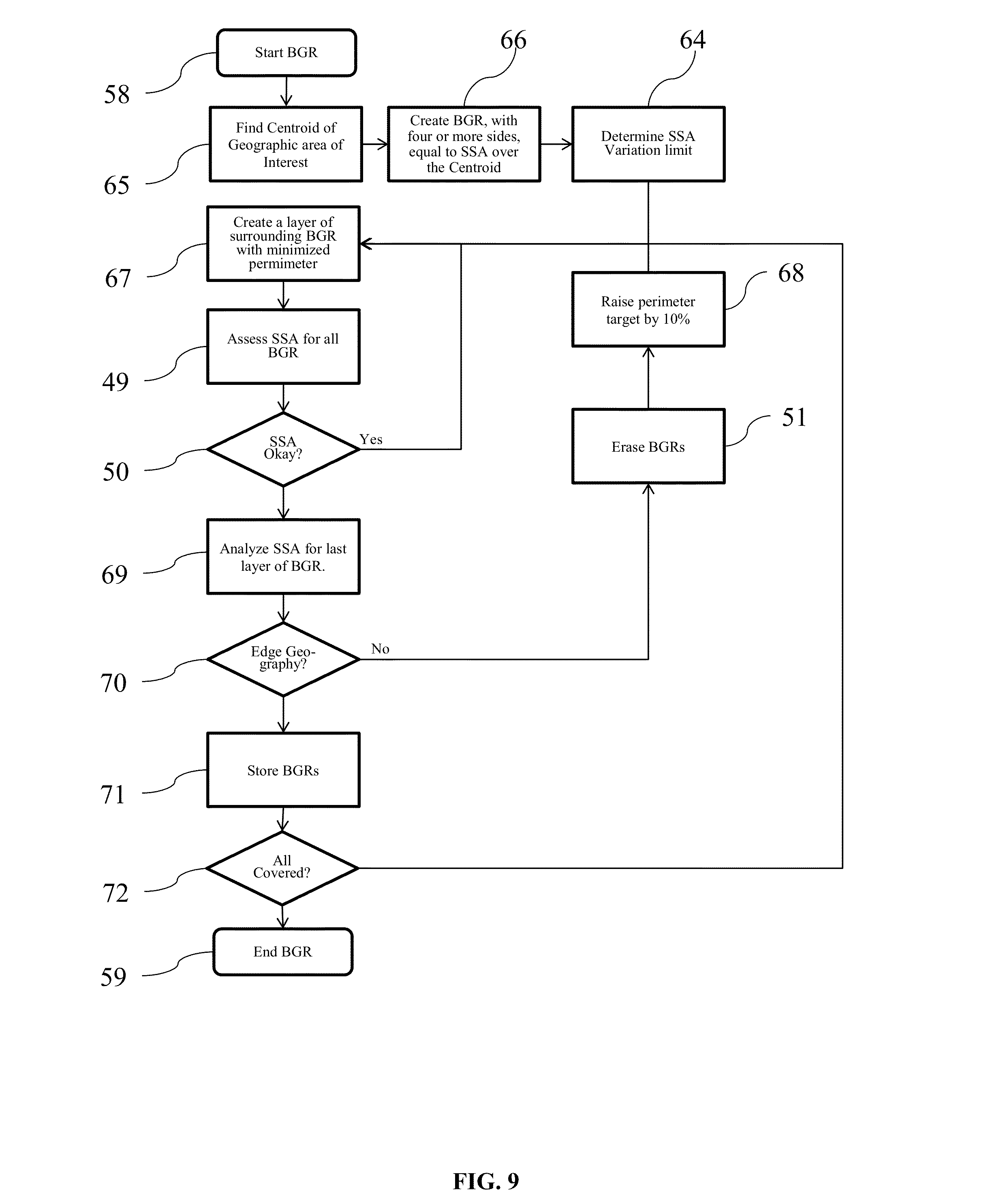
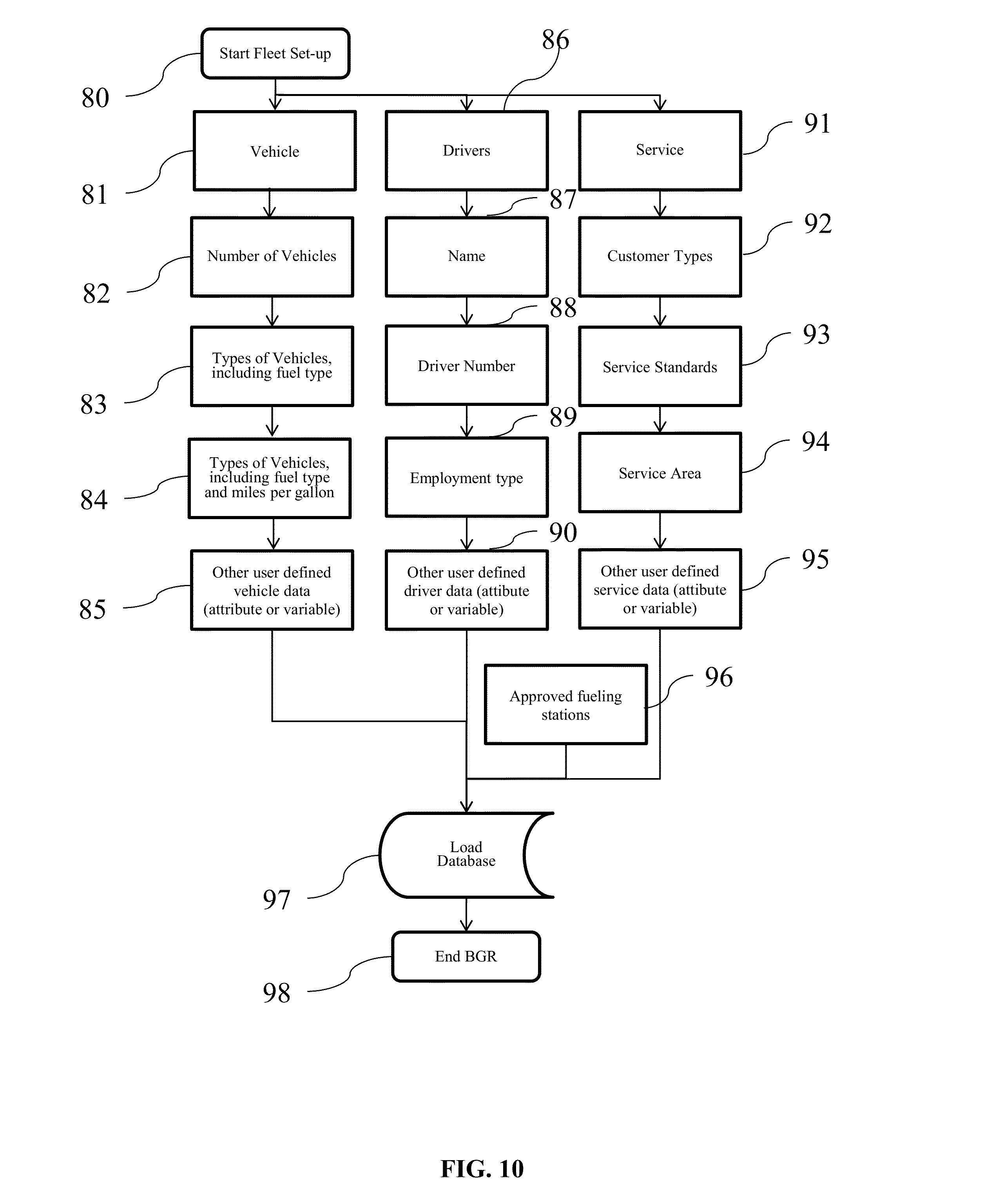
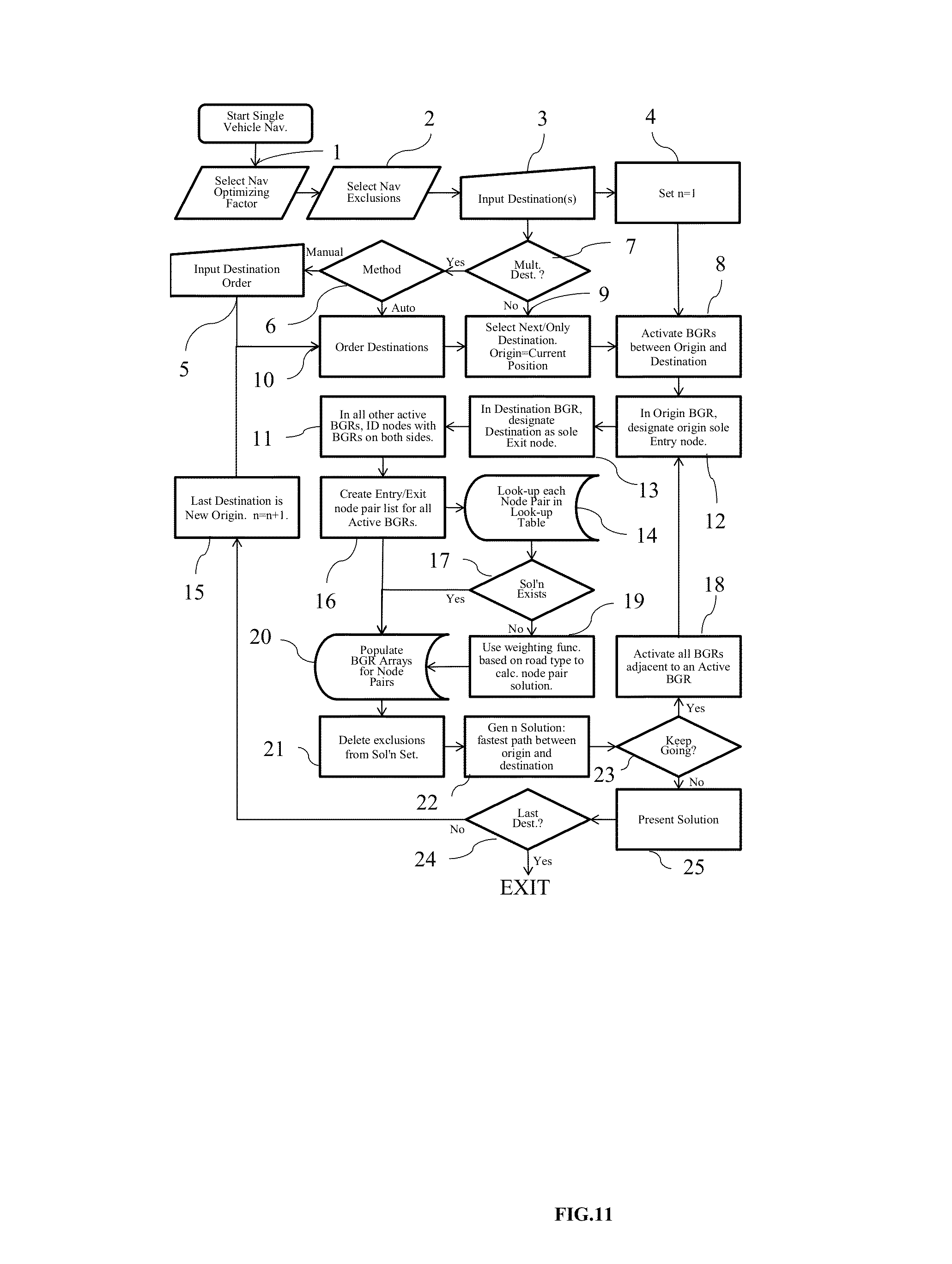
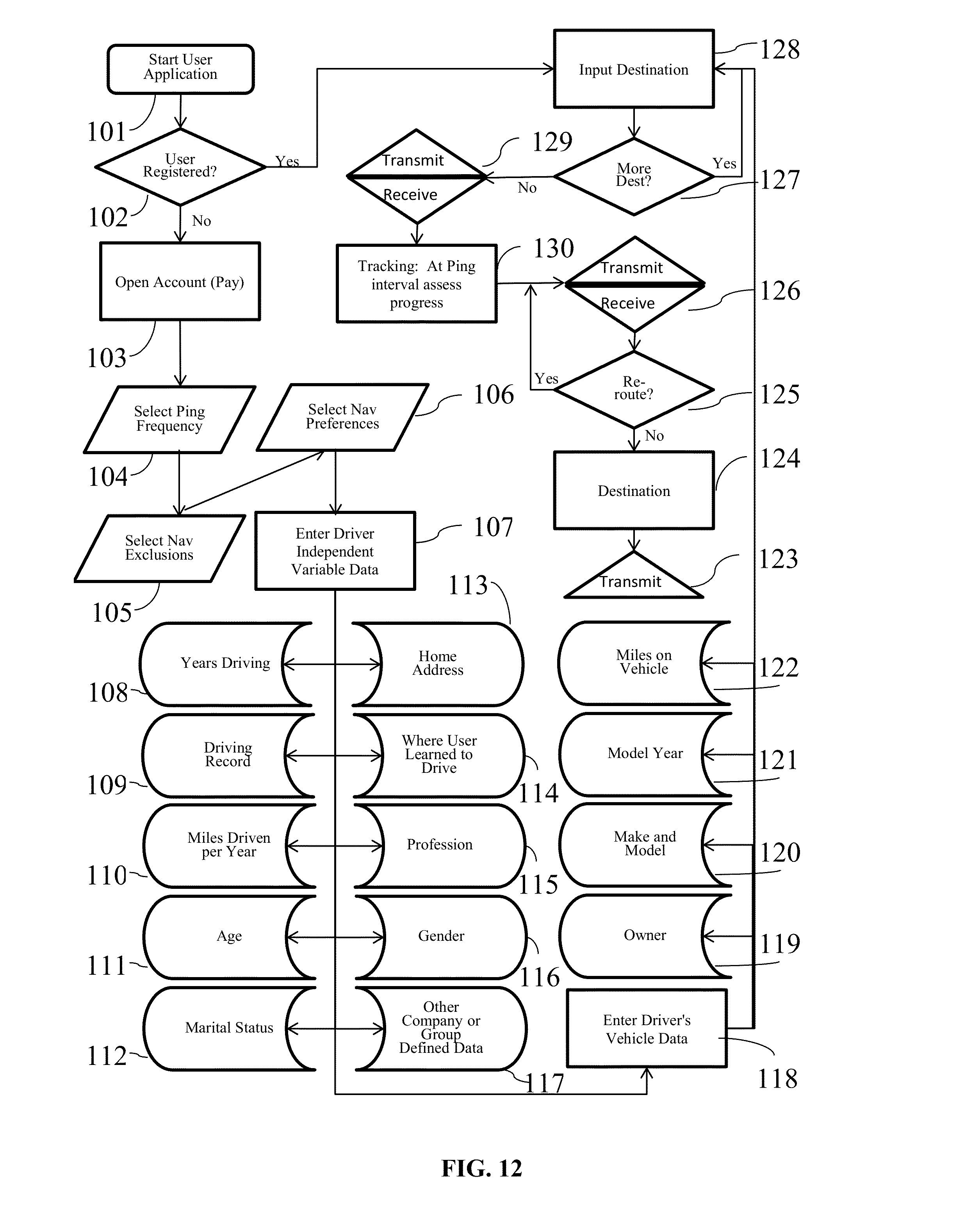
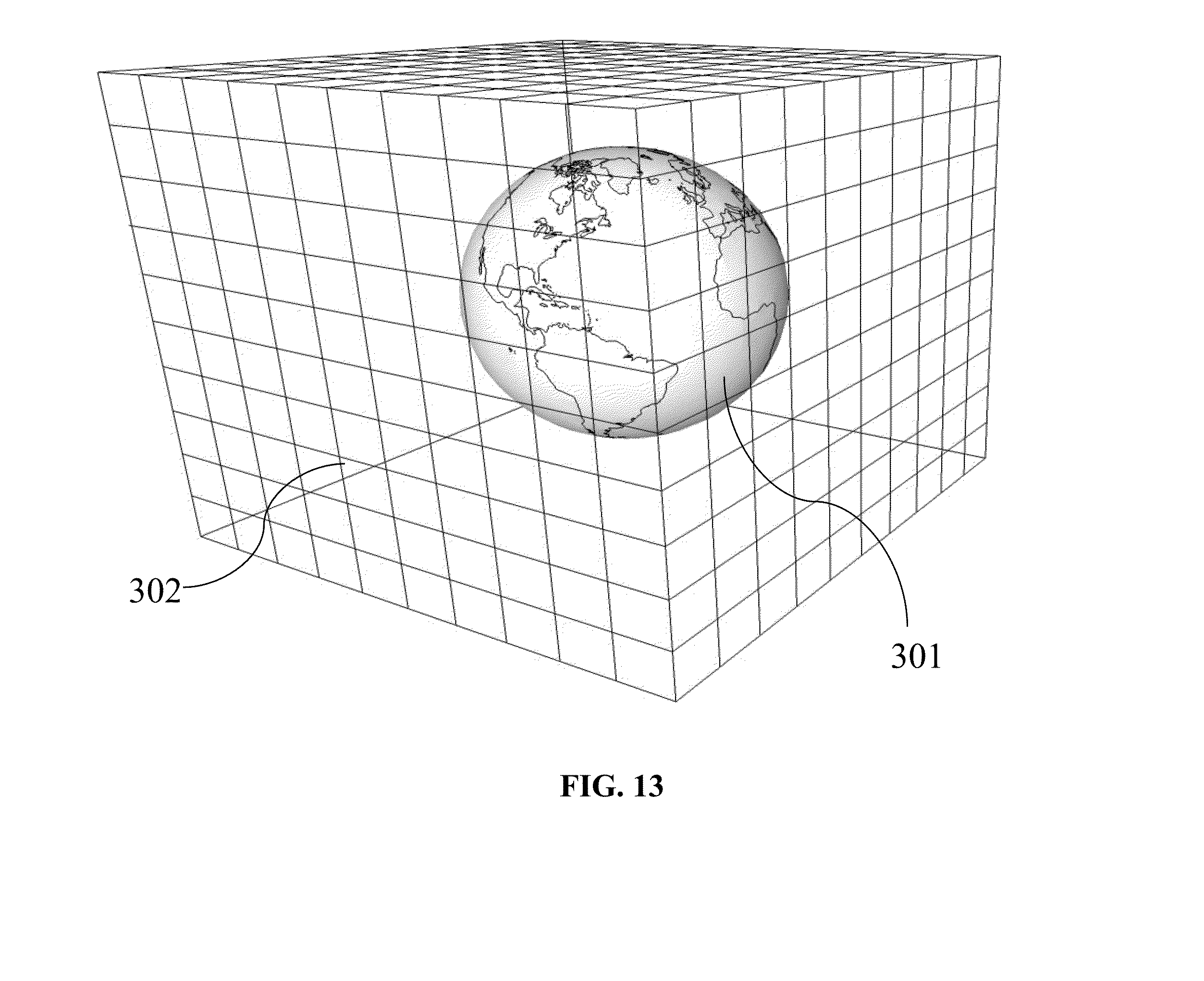
This invention relates to the field of navigation route calculation and guidance, including hand-held navigation, in-vehicle navigation, server-based navigation, and cell-phone application-related navigation. Navigation systems contain certain required basics: input/output device(s); a processing unit, a navigation calculation core; geographic database usually including streets and Points of Interest (“POIs”); and a Global Positioning System chip-set to determine position; inter alia. For automotive systems, there is additionally a gyroscopic chip that provides heading and speed information. Significant disadvantages exist with current systems. Navigation systems built into vehicles by the OEMS require expensive hardware and software, which becomes obsolete far sooner than the car in which it is installed. Additionally, the on-board geographic database requires a storage medium, such as a hard-drive, which, relatively, are more prone to failure than other electronics components, and the database must be updated periodically. Server-based navigation systems are those in which guidance algorithm is resident on a central processing unit or server. End users input navigation destinations using a variety of devices, including mobile phones, computers, portable navigation devices, embedded vehicle systems and mobile data terminals (“MDT”). The end user request is communicated to the server wirelessly, either via a mobile phone network, a satellite network, a Wi-Fi network, or mixed network containing both wireless and wired connections. The wireless link can be interrupted in a number of circumstances (e.g., tunnels, concrete canyons in the centers of major cities, in unpopulated areas, and at times of heavy wireless usage). Depending on how the system was configured, the amount of data that needs to be transmitted often overwhelms the wireless resource. Cellphone and personal navigation are similarly limited. In any geographic region, there are a small number of sources for the navigation database information, itself. A navigation database will provide coordinates and names for streets, as well as defining a street-type for each road (e.g., residential, commercial, highway, interstate, etc.). Often, the navigation database will also include points of interest (“POIs”), which are local business, places of civic or historic significance, schools, churches, and other places frequented by the public. In the United States, the U.S. Census Bureau offers Topologically Integrated Geographic Encoding and Referencing system data (“TIGER data”). TIGER data does not contain a complete set of navigatable streets in the U.S., nor does it provide POIs. There are multiple commercial providers of navigation databases, who provide POIs and a substantially complete set of navigatable streets. The two largest, in the United States, are Navteq® and Tele Atlas®. Unless the text is specifically contrary, the use of POIs in this patent means the general idea of points of interests, rather than any specific, discrete collection of points of interests. In Korea and Japan, the navigation databases are government controlled. Other jurisdictions range from government-owned to private services providing the navigation databases. Additional navigation and navigation database competitors are rapidly entering the market, including Apple and Google. Additionally, the crowdsourcing revolution is impacting map databases. For example, MapBox is working on an open-source collaborative map database called OpenStreetMap. In general, at this point, almost all vehicular and mobile phone navigation relies on navigation software from one source, and a complimentary navigation database from another source. Almost always, a single entity bundles and sells the navigations components as a complete solution. Despite its limitations, the last two decades have seen a proliferation of advanced electronics aimed at navigation. Two decades ago, most vehicles had very little electronic content, and cellphone or mobile phones were in their infancy. Today, the revolution in vehicle and wireless electronics has made global-positioning based navigation ubiquitous. However, the proliferation of options for consumers has not presented an optimized overall solution, yet. Most navigation solutions rely on computational cores which are more than a decade old. All current navigation algorithms rely on one-dimensional optimization. All streets are represented by vectors of varying length and shape. Fundamentally there are two ways the current methods represent streets. In the first, all vectors are straight line vectors. Curves are decomposed into a number of straight line segments. In the second, curves and splines of one form or another are used to mimic the natural curvature of the roads. In order to find a route, current algorithms piece-wise optimize in one dimension. Many individual algorithms exist to perform one-dimensional piece-wise navigation optimization, including, but not limited to, single-sided decision tree, double-sided decision tree, single-sided decision tree with gates, double-sided decision tree with gates, buckets, and leaky buckets. Multiple route segments are grown from either the origin or both the origin and the destination. The routes are compared with one another during the process, and a single or multiple rejection criteria are established to discard divergent solutions. Ultimately, a single route is grown between the origin and the destination, either meeting in the middle (in the case of piece-wise solutions growing from both the origin and the destination) or at the destination (in the case of piece-wise solutions growing only from the origin). Strangely enough, if the process was truly piece-wise optimizing a solution, it would be irrelevant for calculation purposes whether the algorithm started at the origin or the destination. In many algorithms, the calculation will pick different routes in a single-sided decision when the origin and destination are reversed. Some algorithms correct for this by calculating both routes and then presenting the more efficient or optimized route to the end user. The process is facilitated by road weighting. Essentially, interstates and other highways are more highly weighted than major surface thoroughfares. Major surface roads are weighted more heavily than paved secondary roads, which, in turn, are weighted more heavily than residential streets. The weighting combines with the piece-wise, one-dimensional optimization to select a route between any origin and destination. Unfortunately, such weighting often ends up with “interstate bias.” Many users of navigation systems have noted that the systems tend to prefer interstate or highway routes, even when they are significantly detour from the straight line between the origin and destination. The major characterization to take away about today's technology is that it creates routes using piece-wise optimization and weighting. It does not create explicit solutions, even in the relatively local area, even though modern processors and algorithms would easily allow explicit local solutions. Piece-wise optimization and weighting creates a bias towards interstate or highway travel. Such antiquated computational cores create legacy artifacts, which substantially affects the performance of today's navigation systems. These cores were written for slow processors, such as the first generation of RTOS processors. These cores assumed a much smaller volume of data than what can currently be handled (e.g., petabyte systems). These cores assumed that wireless data transfer, if any, would be at substantially slower speeds than what is currently capable. This is not to say that companies have not been updating their software over the past twenty years. What it means is that, when a piece of core software is initially written, many limitations are inherently built-in, either through commission or omission, which makes it difficult to create an update which is truly up-to-date. Additionally, when re-envisioning their software, most software teams have unstated (often unconscious) pre-conceptions about what is possible, because they are starting from a knowledge-base that includes their legacy code. The legacy artifacts caused by antiquated navigational cores include inaccurate estimated-time-of-arrival (“ETA”) calculations, lack of learning, inability to handle multi-vehicle/multi-destination problems with the same software that is used for normal navigation, inability to optimize the solution for multi-vehicle/multi-destination problems, the inability to reasonably assess when the user has substantially diverted from the calculated route, and the inability to pass navigation back-and-forth between devices (e.g., between an in-car unit and a cellphone). Most navigation systems are capable of giving an ETA with a 10% error rate, or less, 80-90% of the time. Most consumers are satisfied with this because (1) they don't rely on the ETA information as their only estimate of their arrival time; (2) the ETA information is better information than what they have from other sources; and/or (3) end-users have normalized their expectations to the system performance level available. However, there are categories of users for whom the error rate is strictly unacceptable. For example, commercial vehicle drivers, commercial fleet operators, people on a tight deadline, and people living in congested areas (where current technology under-performs). Poor ETAs are partially related to the inability of current navigation cores to learn in any meaningful sense. For example, most people know that on Monday morning (excluding holidays), Interstate 405 in Los Angeles is going to be congested at 8:00 a.m. Current navigation cores do not. Likewise, I-696 in metropolitan Detroit, I-90/94 in Chicago, I-95 in Boston, and many other major interstates in major cities are routinely congested. Travel speeds at rush hour on these roads can vary between 60 m.p.h. and 10 m.p.h., on average. Much of the variation is entirely predictable: particular times, days, and conditions are particularly bad, such as Friday afternoons and rain. Unfortunately, current navigation solutions are unable to assess this situation a priori. Current systems attempt to mask this problem with “dynamic navigation.” Dynamic navigation usually entails using “real-time” traffic data, at an additional cost to the user, to re-route the user if there is congestion. Realistically speaking, there is nothing dynamic about dynamic navigation. Most “real-time” traffic reports have a latency of 20 minutes or more, and come from a single source. With little or no motivation to improve performance in a monopolized field, traffic data fed into dynamic navigation systems is atrophying. Moreover, routinely starting a route towards traffic congestion, only to be re-routed when the navigation system's weighting function finally calculates an actionable event from real-time traffic messaging system, creates a big issue, costs the end-user time, money, and tranquility. Most people have learned preferred routes near their homes and businesses. These preferred routes offer the user a quicker and/or more convenient route. If a user continually traverses a preferred route, current navigation cores are incapable of incorporating the data in a meaningful way. There are some solutions on the market that attempt to mask this inadequacy, by “learning” a preferred route. However, the way these systems work, the user has to travel between point A and point B. With repetition, the system will learn preferred sub-routes on which to guide the user between point A and point B. However, the systems are unable to generalize this information in a way which is useful to the end user. Most users would find dubious value in a system that will tell them the route they should take, after they have taken that route three or four times. What users desire is a way to take information, such as the avoidance of traffic control devices, particular ways into or out of business parks, shopping centers and residential sub-divisions, and generalize the information to all other route guidance performed by the unit. The commercially available navigation software cores all have issues when it comes to reasonably re-routing people. In most systems, any divergence from the calculated route will cause the system to re-calculate a solution, which will essentially get the user back onto the originally calculated route. These re-calculations usually entail back-tracking, zigzagging, or returning the user, immediately, to the original route. There is no provision possible for small divergences from the proposed route, seamlessly re-introducing the user into the originally propose route at a reasonable distance. Current navigation systems also lack interoperability. An end-user may have one system in their car, one on their laptop, and one on their cellphone. However, with few exceptions, little data can be passed from one to another. Additionally, it is impossible to start a navigation on a cellphone, enter into a vehicle, and have the vehicle's navigation system provide the navigation calculated on the cellphone. Like most navigation systems, this one includes input/output devices with user interfaces, a method for geo-locating (e.g., a GPS antennae and chip-set), a server-based navigation database, end-user processor(s) and memory, server-based processor(s) and memory, a wireless method for communicating between the end-user and server, and a navigation software core. Like many systems, the user will input a destination, using either POIs, an address, or memory. The origin is assumed to be the current location of the user, unless some other point is specified. The user may specify shortest time, shortest distance, user defined cost functions (such as least gas), or exclusions (e.g., no interstates or no toll roads). To get from the origin to the destination, the invention will calculate a navigation solution. It is possible, on the surface of the Earth, or on any abstraction representing a portion of the surface of the Earth, to create bounded geographic regions (“BGRs”) in any localized area in which a user wants the assistance of a navigation device. Within each BGR there will be a plurality of streets and points of interest (“POIs”). On the periphery of the BGR, there will be nodes, representing the intersection of streets with the boundaries of the BGR. When navigating within a BGR, there are only four possibilities: (1) the user enters the BGR at one node, and exits the BGR through another node; (2) the user originates a trip within the BGR and exits the BGR through a node; (3) the user enters the BGR through a node and the destination resides within the BGR; or (4) the origin and destination both reside within the BGR. In case 2, the origin will be treated as a node for calculation purposes. In case 3, the destination will be treated as a node for calculation purposes. In case 4, both the origin and destination will be treated as a node for calculation purposes. Therefore, in every BGR, it is possible to identify a finite number of Node Pairs, representing the total possible solution set for traversing the BGR. Additionally, BGRs are sized so that a quick, explicit solution is possible for every Node Pair. This invention will optimize some user-defined dependent variable for the end user: (1) time; (2) distance; (3) fuel; (4) cost; or (5) other commercially-valuable, user-defined dependent variable. The invention will do this by creating an estimating function, which can be used to provide a value for each Node Pair. The estimating function will use weighting factors, based on the road-type from the navigation database, as well as historical data, to create the value for each Node Pair. The navigation software core will identify a finite numbers of BGRs, which will be in reasonable geographic proximity between the origin and destination, in which to calculate solutions. By determining the value for each Node Pair for each BGR, it is possible to solve for the optimizing solution, explicitly. By creating BGRs which are small enough to that an explicit solution is possible, this system and method will allow a two-dimensional optimization for routing. Once a solution is calculated for a Node Pair, the solution is saved in a Node Pair Look-Up Table (“NPLUT”). The NPLUT is sorted by BGR, so that at any given time, only the most local solutions are presented to the processing unit, improving speed and efficiency. The unit can compare actual performance to the calculated value for each Node Pair. Using an error function, the unit can adjust the stored solution for the Node Pair. Furthermore, the NPLUT can store both variable and attribute (digital event or flag) data, allowing for full-factorial ANOVA or MANOVA calculations, depending on the number of dependent variables of interest. The NPLUT can use factors, including, but not limited to, time of day, day of week, date, driver, driver age, location where driver learned to drive (Boston drivers always drive fast), special event occurrence (e.g., football game in proximity), construction, precipitation, temperature, etc. Within the NPLUT, each BGR and Node Pair has a unique designator or name. Many numbering schemes are possible for both. BGRs can be ordered with an ordinal numbering scheme, a cardinal numbering scheme, an alphanumeric numbering scheme (with or without significance), or an identification scheme based on the BGR latitude and longitude. The internal numbering scheme should be focused at database and computational efficiency. The values used for the BGR ordering scheme do not need to be presented to the end user. In the event that it is advantageous to present BGR numbering or ordering to the end-user, a transform can be created to show the end-user BGRs with easy to reference designators (e.g., 1, 2, 3, etc.) This might be useful for certain fleet applications, such as vehicle for hire, where, currently, zones are used to distribute vehicles and orders. For each node for each BGR, a unique designator needs to be assigned. A Node Pair designator would then be the unique designator for both nodes, as well as the designator for the associated BGR. To fully describe a Node Pair, one would need to identify both the BGR and the Node Pair. The node part of the Node Pair designator would be commutative to the system. In the real world, each node represents a point on a road as it passes through the boundary of a BGR. Therefore, a Node Pair designator will give two locations, either on the same road, or on different roads, which are both on the boundary of a particular BGR. In the NPLUT, each Node Pair reference will have a value for each dependent variable (e.g., time, distance, fuel consumption, surface roads navigation, etc.). With each navigation traversing the Node Pair, the actual value will be measured or estimated. The actual value will then be stored in the NPLUT, along with independent variables related to the trip, such as age of driver, gender of driver, profession of driver, type of vehicle, age of vehicle, time of day, day of week, date, weather, etc. After each navigation, intermediate ANOVA and MANOVA values (i.e., sum, sum of squares, etc.) can be stored and associated with the Node Pair trip. In this way, when a particular user navigates, an adjusted value for each Node Pair can be presented. The feedback used to adjust the values given for each Node Pair can be a simple least squared error calculation, an error function that more heavily favors recent events, or other commonly used control system error correction methods. Truly predictive traffic is no more than correctly identifying the dependent variable of interest, and capturing the independent variables of interest. If one does that the system will predict traffic with as much accuracy as the data and math allow. The BGRs, Node Pairs, and independent variables can be used in ways not currently available, due to the navigation being server based. For example, if weather starts affecting traffic in Chicago, it will typically reach Detroit within a given amount of time. A simple auxiliary process can be appended to the system, which, based off of the independent variables, estimates the latency period between weather in Chicago, for example, and Detroit, and the time-dependent probability of the weather from Chicago becoming weather that affects traffic in Detroit. The system can then create ETAs for future trips based off of impending weather, or other predictable future events. The ETAs for future trips can then be periodically updated, as the correlation of the data becomes more certain. There are thirteen relevant drawings. The following description represents the inventors' current preferred embodiment. The description is not meant to limit the invention, but rather to illustrate its general principles of operation. Examples are illustrated with the accompanying drawings. In From In When starting the end user application 101, if the user is not registered, the unit can allow registration by opening an account 103. After opening the account 103, the user selects ping frequency 104, navigation preferences 106, and navigation exclusions 105. The user then has to complete independent variables concerning him- or herself, and his or her vehicle. Driver information 107 includes years driving 108, driving record 109, miles driven per year 110, age 111, marital status 112, home address 113, where the user learned to drive 114, the user's profession 115, the user's gender 116, and other company- or group-defined data 117. The vehicle information 118 includes vehicle owner 119, make and model 120, model year 121 and miles on the vehicle 122. The independent variable data should be of very high quality, because the user will be aware that their accuracy in answering the questions may directly relate to how well the system can navigate for them. To calculate between an origin and destination, the invention will identify the BGRs that lie, linearly, between the origin and destination 8, and designates them as Active. These BGRs are termed Gen 1. In the BGR containing the origin, the origin is designated the sole entry node 12. In the BGR containing the current destination 9, the current destination is designated as the sole exit node 13. In all other BGRs, Node Pairs are created by selecting only those nodes which have a BGR on both sides 11. The navigation core than creates a Node Pairs list for all Active BGRs 16. In multi-processor systems, the navigation core will simultaneously create a temporary BGR array for all Node Pairs under consideration 20, and survey the NPLUT 14 to see if solutions exist for any Node Pairs under consideration 17. If the Node Pairs solution exists in the NPLUT, it is placed in the temporary BGR array 20. If not, using weighting functions for each street classification, the invention makes dependent variable calculations for each Node Pair of each BGR 19, capturing route information for each potential solution. The invention will delete any exclusions from the potential solution set 21. Since only a limited set of BGRs are used for the initial calculation, not all nodes of each BGR is a potential entry and/or exit. The data generated from the nodes of interest can be stored in an array, in a temporary database format, or in any other data-handling format that allows quick access 20. This temporary data can be stored in cache storage, on the hard-drive, or in any other type of suitable memory element. In a multi-core processor environment, such calculations are speedy, because each BGRs can be independently calculated. The invention then creates an initial trial route by finding the initial minimum solution from the origin to the destination, travelling only through BGRs that lie, linearly, between the origin and destination 22. As a boundary condition for the initial route calculation, the exit node of one BGR is the entry node of the adjoining BGR. By creating a matrix of possible solutions, the invention yields an explicit solution. Once the initial trial route is identified, the solution engine adds all BGRs that were adjacent to Gen 1 BGRs 23, 18, and largely repeats the above process. The new BGRs are termed Gen 2. Gen 1 BGRs now use all nodes in the calculation. Gen 2 BGRs use a reduced set of nodes, because not all nodes have an adjoining BGR associated with them. To calculate the Gen 2 trial route, the potential solutions calculated in the Gen 1 calculation are excluded, because they are found in the temporary array 20. The invention, again, applies the boundary condition that the exit node of one BGR is the entry node of the adjoining BGR. By creating a matrix of possible unique solutions (excluding Gen 1 solutions), the invention yields an explicit solution, the Gen 2 trial route 22. The process is repeated for Gen 3, in much the same way as for Gen 2 23, 18. All BGRs adjoining Gen 2 BGRs are added to the calculation. All previously considered trial solutions are excluded from the potential solution set. An explicit solution for the Gen 3 trial route is calculated. Call Gen A the optimum solution. The exit criteria is selected so that C generations are completed, where C=A+B, where C is the total number of generations, A is the optimum generation, and B is the number of desired divergent solutions calculated after the optimum solution. For example, if the Gen 1 trial route is preferable to the Gen 2 or Gen 3 trial route, and the calculations stop, presenting the Gen 1 trial route to the user as the preferred route, C=3, A=1, and B=2. In practice, B is related to the distance between the origin and destination 23. Additionally, selection of B can be optimized through a simple error feedback function, where the error is related to the distance. The upper limit of B is set by the maximum speed limit. In other words, the process ends when the vehicle would have to exceed the maximum allowable speed limit around the periphery in order to offer a more preferable solution to the dependent variable than the currently available solution. A navigation system containing a software core, which uses bounded geographic regions (“BGRs”) and Node Pairs to explicitly optimize, in two dimensions, for user desired dependent variables, by analyzing variance due to standard and user-defined independent variables. The invention stores Node Pair data, and can use error function, feedback, and ANOVA/MANOVA to create a tightly convergent navigation solution. 1. A method and system of navigation guidance, containing, at a minimum, an end-user device with means for inputting destinations and receiving guidance or routing; a map database, containing roads and, optionally, POIs; a device and method for determining vehicle position, such as a Global Positioning System; a server or other assemblage of memory and processing elements; a means for communicating between the end-user device and the server; and a navigation software core, resident on the server, having the capability to create bounded geographic regions (“BGRs”), identify Node Pairs for each BGR which might be part of a potential solution, and optimize a navigation solution based on the dependent variable provided by the user and the independent variables which are inherently part of a solution database. 2. The invention in 1, also containing a Node Pair Look-up Table (“NPLUT”) database which is initially, either partially or fully, loaded with explicit solutions for each Node Pair. 3. The invention in 2, in which the software contains an error function calculator and a feedback routine to correct dependent variable values stored in the NPLUT database. 4. The invention in 2, in which each end-user's actual value for each Node Pair solution for dependent variables, such as time, distance, fuel usage, cost, and any user defined dependent variables, as well as independent variables, are communicated to and stored in NPLUT, either while or after the end-user arrives at the destination. 5. The invention in 2, in which for each dependent Node Pair value in the NPLUT, associated independent variable factors are captured and stored, both variable and attribute, such as, but not limited to, time of day, date, day of the week, temperature, construction, precipitation, driver's age, driver's profession, driver's gender, vehicle type, vehicle age, vehicle mileage, and special event, which can be used to create ANOVA and MANOVA calculations of the dependent variables stored in the NPLUT, in order to give more accurate estimates during future navigation. 6. The invention in 5, in which the NPLUT database is compressed by storing only the necessary ANOVA or MANOVA sums and products from prior navigation iterations, and deleting the underlying data off of which the sums and products are calculated. 7. The invention in 1, in which the BGRs are created by Virtual Tessellation, by inscribing the Earth in a tessellated cube or partitioned cube, and projecting the tessellation or partition from the cube onto the surface of the Earth. 8. The invention in 7, in which the tessellation pattern on the cube is comprised of squares and rectangles, the area of which is reduced geometrically as the rectangles vary from the center of the cube face, and the aspect ratio of which increases with distance from the center of the cube face. 9. The invention in 1, in which solutions for each Node Pair are calculated using different processors in a multi-processor configuration. 10. The invention in 1, in which the navigation software core will iteratively calculate routes using more and more BGRs, until the solutions become sufficiently divergent, or until the last BGR layer exceeds, orthogonally to a line from the origin to the destination, the distance that a vehicle can travel at the maximum posted speed limit in the amount of time defined by the current best solution. 11. The invention in 1, in which the end-user's device memory only stores detail from Active BGRs. 12. The invention in 1, in which the communication with the server is made via a wireless or satellite connection to a vehicle, mobile telephone, mobile data terminal, or remote electronic device. 13. The invention in 1, in which the server can also collect data from other data sources, including, but not limited to, NHTSA traffic sensor information, police report, local traffic reports, and construction reports, for inclusion in the NPLUT as either variable or attribute data associated with a Node Pair. FIELD OF INVENTION
BACKGROUND OF INVENTION
SUMMARY OF THE INVENTION
BRIEF DESCRIPTION OF THE DRAWINGS
DETAILED DESCRIPTION OF THE PREFERRED EMBODIMENTS