VOICE PROCESSING APPARATUS
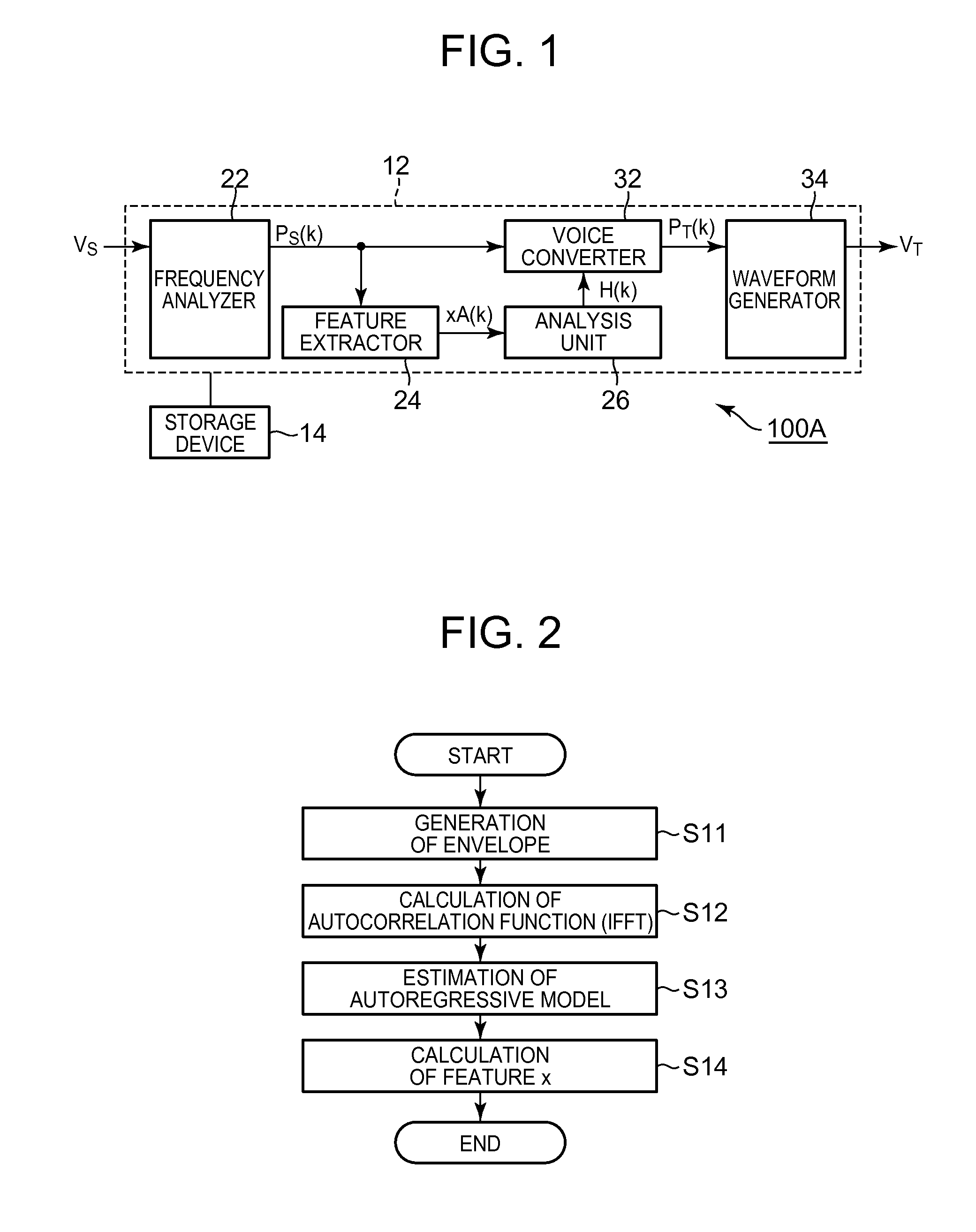
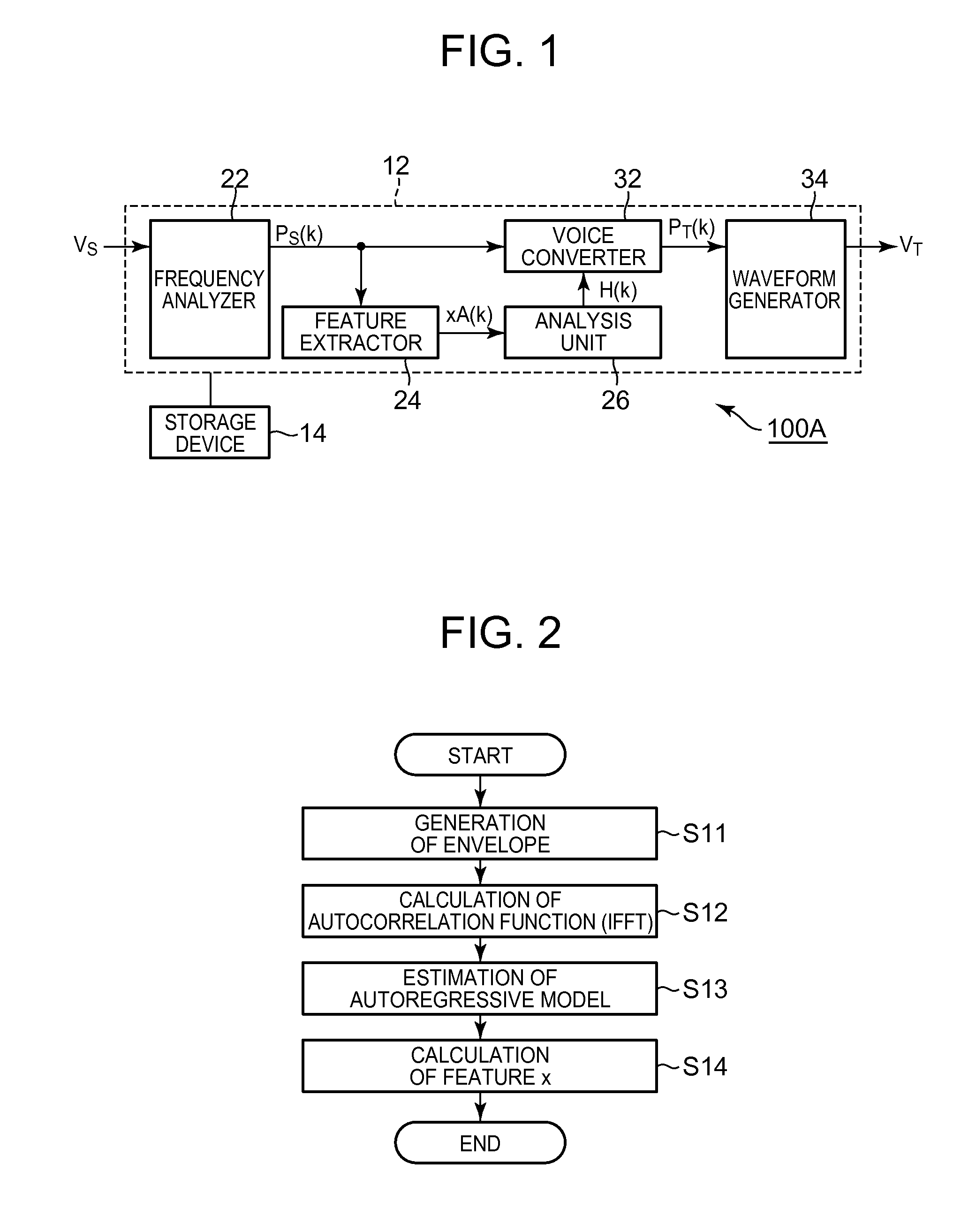
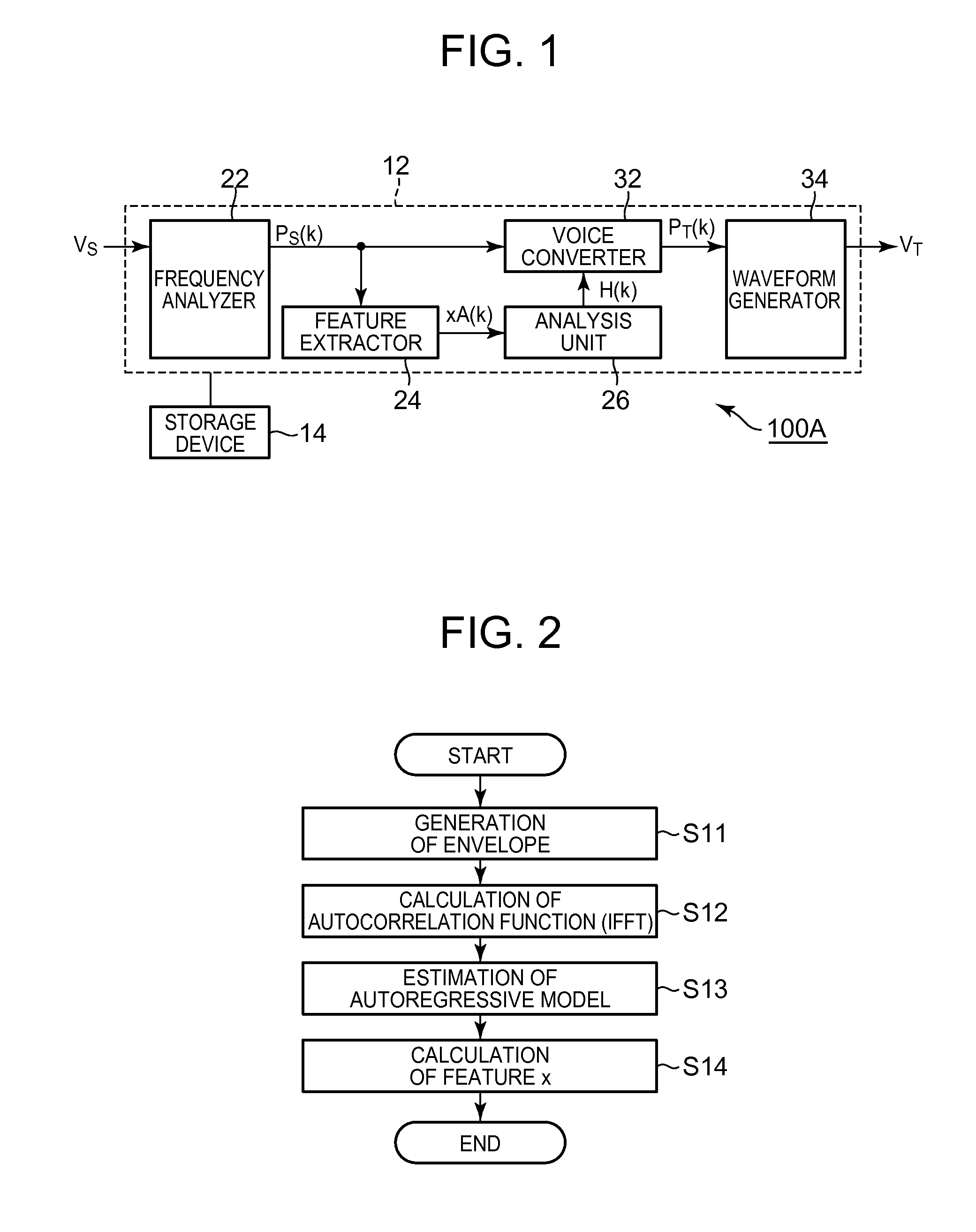
1. Technical Field of the Invention The present invention relates to technology for processing voice. 2. Description of the Related Art Technology for converting characteristics of voice has been proposed, for example, by F. Villacivencio and J Bonada, “Applying Voice Conversion to Concatenative Singing-Voice Synthesis”, in Proc. Of INTERSPEECH 10, vil. 1, 2010. This reference discloses technology for applying, to target voice, a conversion function based on a normal mixture distribution model that approximates probability distributions of the feature of voice of a first speaker and the feature of voice of a second speaker to thereby generate a voice corresponding to characteristics of the voice of the second speaker. However, in the above mentioned technology, when voice having a feature different from that of the voice applied to generation of the conversion function (machine learning) is target voice to be processed, voice that does not correspond to the characteristics of the voice of the second speaker may be generated. Accordingly, characteristics of converted voice are unstably changed according to characteristics of the target voice (difference from voice for learning), and thus the quality of the converted voice may be deteriorated. In view of this, an object of the present invention is to generate voice with high quality by converting voice characteristics. Means employed by the present invention to solve the above-described problem will be described. To facilitate understanding of the present invention, correspondence between components of the present invention and components of embodiments which will be described later is indicated by parentheses in the following description. However, the present invention is not limited to the embodiments. A voice processing apparatus according to a first aspect of the present invention comprises a processor configured to perform: generating a converted feature (e.g. converted feature F(xA(k)) by applying a source feature (e.g. source feature xA(k)) of source voice to a conversion function (e.g. conversion function F(x)) for voice characteristic conversion, which includes a probability term representing a probability that a feature of voice belongs to each element distribution (e.g. element distribution N) of a mixture distribution model (e.g. mixture distribution model λ(z)) that approximates distribution of features of voices (e.g. source voice VS0 and target voice VT0) having different characteristics (refer to conversion unit 42); generating an estimated feature (e.g. estimated feature xB(k)) based on a probability that the source feature belongs to each element distribution of the mixture distribution model by applying the source feature to the probability term (refer to feature estimator 44); generating a first conversion filter (e.g. first conversion filter H1( In the voice processing apparatus according to the first aspect of the present invention, the first conversion filter is generated based on the difference between the estimated feature obtained by applying the source feature to the probability term of the conversion function and the converted feature obtained by applying the source feature to the conversion function, and the second conversion filter is generated based on the difference between the first spectrum represented by the converted feature and the second spectrum obtained by applying the first conversion filter to the source spectrum of the source feature. The target voice is generated by applying the first conversion filter and the second conversion filter to the spectrum of the source voice VS. The second conversion filter operates such that the difference between the source feature and the estimated feature is compensated, and thus high-quality voice can be generated even when the source feature is different from the feature of voice for setting the conversion function. According to a preferred aspect of the present invention, the processor performs: smoothing the first spectrum and the second spectrum in a frequency domain thereof (refer to smoothing unit 562); and calculating a difference between the smoothed first spectrum (e.g. first smoothed spectral envelope LS1( In this configuration, since the difference between the smoothed first spectrum and the smoothed second spectrum is calculated as the second conversion filter, it is possible to accurately compensate for the difference between the source feature and the estimated feature. In a second aspect of the present invention, the processor further performs: sequentially selecting a plurality of phonemes as the source voice, so that each phoneme selected as the source voice is processed by the processor to sequentially generate a plurality of phonemes as the target voice; and connecting the plurality of the phonemes each generated as the target voice to synthesize an audio signal. According to this configuration, the same effect as the voice processing apparatus according to the first aspect of the invention can be achieved. The voice processing apparatuses according to the first and second aspects of the present invention are implemented by not only an electronic circuit such as a DSP (Digital Signal Processor) dedicated for voice processing but also cooperation of a general-use processing unit such as a CPU (Central Processing Unit) and a program. For example, a program according to the first aspect of the present invention executes, on a computer, a conversion process (S21) for generating a converted feature by applying a source feature of source voice to a conversion function for voice characteristic conversion, which includes a probability term representing a probability that a feature of voice belongs to each element distribution of a mixture distribution model that approximates distribution of features of voices having different characteristics, a feature estimation process (S22) for generating an estimated feature based on a probability that the source feature belongs to each element distribution of the mixture distribution model by applying the source feature to the probability term, a first difference calculating process (S23) for generating a first conversion filter based on a difference between a first spectrum corresponding to the converted feature generated through the conversion process and an estimated spectrum corresponding to the estimated feature generated through the feature estimation process, a synthesizing process (S24) for generating a second spectrum by applying the first conversion filter generated through the first difference calculating process to a source spectrum corresponding to the source feature, a second difference calculating process (S25) for generating a second conversion filter based on a difference between the first spectrum and the second spectrum, and a voice conversion process (S26) for generating target voice by applying the first conversion filter and the second conversion filter to the source spectrum. According to the program, the same operation and effect as those of the voice processing apparatus according to the first aspect of the present invention can be implemented. A program according to the second aspect of the present invention executes, on a computer, a phoneme selection process for sequentially selecting a plurality of phonemes, a voice process for converting the phonemes selected by the phoneme selection process into phonemes of target voice through the same process as the program according to the first aspect of the invention, and a voice synthesis process for generating an audio voice signal by connecting the phonemes converted through the voice process. According to the program, the same operation and effect as those of the voice processing apparatus according to the second aspect of the present invention can be implemented. The programs according to the first and second aspects of the present invention can be stored in a computer readable non-transitory recording medium and installed in a computer, or distributed through a communication network and installed in a computer. As shown in The frequency analyzer 22 sequentially calculates a spectrum (referred to as “source spectrum” hereinafter) PS(k) of the source voice VS for each unit period (frame) in the time domain. Here, k denotes a unit period in the time domain. The spectrum PS(k) is an amplitude spectrum or power spectrum, for example. A known frequency analysis method such as fast Fourier transform can be used to calculate the spectrum PS(k). Furthermore, it is possible to employ a filter bank composed of a plurality of bandpass filters having different passbands as the frequency analyzer 22. The feature extractor 24 sequentially generates a feature (referred to as “source feature” hereinafter) xA(k) of the source voice VS for each unit period. Specifically, the feature extractor 24 according to the first embodiment of the invention executes a process shown in The feature extractor 24 calculates an autocorrelation function by performing inverse Fourier transform on the source spectral envelope EA(k) (S12) and estimates an autoregressive model (all-pole transfer function) that approximates the source spectral envelope EA(k) from the autocorrelation function calculated by step S12 (S13). Yule-Walker equation is preferably used to estimate the autoregressive model. The feature extractor 24 calculates a vector having, as components, a plurality of coefficients (line spectrum frequency) corresponding to coefficients (autoregressive coefficients) of the autoregressive model estimated in step S13, as the source feature xA(k) (S14). As described above, the source feature xA(k) represents the source spectral envelope EA(k). Specifically, each coefficient (each line spectrum frequency) of the source feature xA(k) is set such that spacing (coarse and dense) of line spectra is changed according to the height of each peak of the source spectral envelope EA(k). The analysis unit 26 shown in The voice converter 32 converts the source voice VS into the target voice VT using the conversion filter H(k) generated by the analysis unit 26. Specifically, the voice converter 32 generates a spectrum PT(k) of the target voice VT in each unit period by applying the conversion filter H(k) corresponding to a unit period to the spectrum PS(k) corresponding to a unit period, generated by the frequency analyzer 22. For example, the voice converter 32 generates the spectrum PT(k) (PT(k)=PS(k)+H(k)) by summing the spectrum PS(k) of the source voice VS and the conversion filter H(k) generated by the analysis unit 26. The temporal relationship between the spectrum PS(k) of the source voice VS and the conversion filter H(K) may be appropriately changed. For example, the conversion filter H(k) corresponding to a unit period can be applied to a spectrum PS(k+1) corresponding to the next unit period. The waveform generator 34 generates an audio vocal signal corresponding to the target voice VT from the spectrum PT(k) generated by the voice converter 32 in each unit period. Specifically, the waveform generator 34 generates the voice signal corresponding to the target voice VT by converting the spectrum PT(k) of the frequency domain into a waveform signal of the time domain and summing waveform signals of consecutive unit periods in an overlapping state. The voice signal generated by the waveform generator 34 is output as sound, for example. A conversion function F(x) for converting the source voice VS into the target voice VT is used for generation of the conversion filter H(k) by the analysis unit 26. Prior to description of the configuration and operation of the analysis unit 26, the conversion function F(x) will now be described in detail. To set the conversion function F(x), previously stored or provisionally sampled source voice VS0 and target voice VT0 are used as learning information (advance information). The source voice VS0 corresponds to voice generated when the speaker US sequentially speaks a plurality of phonemes, and the target voice VT0 corresponds to voice generated when the speaker UT sequentially speaks the same phonemes as those of the source voice VS0. A feature x(t) of the source voice VS0, corresponding to each unit period, and a feature y(t) of the target voice VT0, corresponding to each unit period, are extracted. The feature x(t) and feature y(t) have the same value (vector representing a spectral envelope) as the source feature xA(k) extracted by the feature extractor 24 and are extracted through the same method as the process shown in A mixture distribution model λ(z) corresponding to distributions of the feature x(t) of the source voice VS0 and the feature y(k) of the target voice VT0 is taken into account. The mixture distribution model λ(z) approximates a distribution of a feature (vector) z, which has the feature x(k) and the feature y(k) corresponding to each other in the time domain as elements, to the weighted sum of Q element distributions N, as represented by Equation (1). For example, a normal mixture distribution model (GMM: Gaussian Mixture Model) having an element distribution N as a normal distribution is preferably employed as the mixture distribution model λ(z). In Equation (1), αq denotes the weighted sum of q-th (q=1 to Q) element distribution N, μqz denotes the average (average vector) of the q-th element distribution N, and Σqz denotes the covariance matrix of the q-th element distribution N. A known maximum likelihood estimation algorithm such as EM (Expectation-Maximization) algorithm is employed to estimate the mixture distribution model λ(z) of Equation (1). When the total number of element distributions N is set to an appropriate value, there is a high possibility that the element distributions N of the mixture distribution model λ(z) correspond to different phonemes. The average μqz of the q-th element distribution N includes the average μqx of the feature x(k) and the average μqy of the feature y(k), as represented by Equation (2). The covariance matrix Σqz of the q-th element distribution n is represented by Equation (3). In Equation (3), Σqxx denotes a covariance matrix (autocovariance matrix) of each feature x(k) in the q-th element distribution N, Σqyy denotes a covariance matrix (autocovariance matrix) of each feature y(k) in the q-th element distribution N, and Σqxy and Σqyx respectively denote covariance matrices (cross-covariance matrices) of features x(k) and y(x) in the q-th element distribution N. The conversion function F(x) applied by the analysis unit 26 to generation of the conversion filter H(k) is represented by Equation (4). In Equation (4), p(cq|x) denotes a probability term representing a probability (posteriori probability) that a feature x belongs to the q-th element distribution N of the mixture distribution model λ(z) when the feature x is observed and is defined by Equation (5). The conversion function F(x) of Equation (4) represents mapping from a space (referred to as “source space” hereinafter) corresponding to the source voice VS of the speaker US to another space (referred to as “target space” hereinafter) corresponding to the target voice VT of the speaker UT. That is, an estimate F(xA(k)) of the feature of the target voice VT, which corresponds to the source feature xA(k), is calculated by applying the source feature xA(k) extracted by the feature extractor 24 to the conversion function F(x). The source feature xA(k) extracted by the feature extractor 24 may be different from the feature x(k) of the source voice VS0 used to set the conversion function F(x). Mapping of the source feature xA(k) according to the conversion function F(x) corresponds to a process of converting (mapping) a feature (estimated feature) xB(k) (xB(k)=p(cq|xA(k))xA(k)), obtained by representing the source feature xA(k) in the source space according to the probability term p(cqlx), to the target space. The averages μqx and μqy of Equation (2) and the covariance matrices Σqxx and Σqyx of Equation (3) are calculated using each feature x(k) of the source voice VS0 and each feature y(k) of the target voice VT0 as learning information and stored in the storage device 14. The analysis unit 26 shown in The conversion unit 42 calculates the converted feature F(xA(k)) for each unit period by applying the source feature xA(k) extracted by the feature extractor 24 for each unit period to the conversion function F(x) of Equation (4). That is, the converted feature F(xA(k)) corresponds to an estimate of the feature of the target voice VT or predicted feature thereof, which corresponds to the source feature xA(k). The feature estimator 44 calculates the estimated feature xB(k) for each unit period by applying the source feature xA(k) extracted by the feature extractor 24 for each unit period to the probability term p(cq|x) of the conversion function F(x). The estimated feature xB(k) represents a predicted point (specifically, a point at which the likelihood that a phoneme corresponds to the source feature xA(k) is statistically high) corresponding to the source feature xA(k) in the source space of the source voice VS0 used to set the conversion function F(x). That is, the estimated feature xB(k) corresponds to a model of the source feature xA(k) represented in the source space. The feature estimator 44 according to the present embodiment calculates the estimated feature xB(k) according to Equation (6) using the average μqx stored in the storage device 14. The spectrum generator 46 shown in The first difference calculator 52 shown in The synthesizing unit 54 shown in The second difference calculator 56 sequentially generates a second conversion filter H2( The subtractor 564 shown in The integration unit 58 shown in At step S22, feature estimation is performed for generating an estimated feature (e.g. estimated feature xB(k)) based on a probability that the source feature belongs to each element distribution of the mixture distribution model by applying the source feature to the probability term. At step S23, first difference calculation is performed for generating a first conversion filter (e.g. first conversion filter H1( At step S24, synthesis process is performed for generating a second spectrum (e.g. second spectral envelope L2( At step S25, second difference calculation is performed for generating a second conversion filter (e.g. second conversion filter H2( At step S26, voice conversion is performed for generating target voice by applying the first conversion filter and the second conversion filter to the source spectrum. A configuration (referred to as “comparative example” hereinafter) in which the difference between the first spectral envelope L1( The first conversion filter H1( In the first embodiment of the present invention, the second conversion filter H2( A second embodiment of the present invention will now be described. In the following embodiments, components having the same operations and functions as those of corresponding components in the first embodiment are denoted by the same reference numerals and detailed description thereof is omitted. As shown in The processing unit 12 according to the second embodiment of the invention performs a plurality of functions (functions of a phoneme selector 72, a voice processing unit 74 and a voice synthesis unit 76) by executing a program stored in the storage device 14. The phoneme selector 72 sequentially selects a phoneme DS corresponding to a sound generating character (referred to as “designated phoneme” hereinafter) such as lyrics designated to a synthesis target. The voice processing unit 74 converts each phoneme D (source voice VS) selected by the phoneme selector 72 into a phoneme DT of the target voice VT of the speaker UT. Specifically, the voice processing unit 74 performs conversion of each phoneme D when instructed to synthesize a voice of the speaker UT. More specifically, the voice processing unit 74 generates a phoneme DT of the target voice VT from the phoneme DS of the source voice VS through the same process as conversion of the source voice VS into the target voice VT by the voice processor 100A according to the first embodiment of the invention. That is, the voice processing unit 74 according to the second embodiment of the invention includes the frequency analyzer 22, the feature extractor 24, the analysis unit 26, the voice converter 32, and the waveform generator 34. Accordingly, the second embodiment can achieve the same effect as that of the first embodiment. When synthesis of a voice of the speaker US is instructed, the voice processing unit 74 stops operation thereof. The voice synthesis unit 76 shown in In the second embodiment described above, since phonemes D extracted from the source sound VS of the speaker US are converted into phonemes D of the target voice VT and then applied to voice synthesis, it is possible to synthesize a voice of the speaker UT even if the phonemes D of the speaker UT are not stored in the storage device 14. Accordingly, capacity of the storage device 14, required to synthesize the voice of the speaker US and the voice of the speaker UT, can be reduced compared to the configuration in which both the phonemes D of the speaker US and phonemes D of the speaker UK are stored in the storage device. The above-described embodiments can be modified in various manners. Detailed modifications will now be described. Two or more arbitrary embodiments selected from the following examples can be appropriately combined. (1) While the integration unit 58 of the analysis unit 26 generates the conversion filter H(k) by integrating the first conversion filter H1( (2) While the second conversion filter H2( (3) While series of a plurality of coefficients that define the line spectrum of an autoregressive model are exemplified as features xA(k) and xB(k) in the above-described embodiments, feature types are not limited thereto. For example, a configuration using an MFCC (Mel-frequency cepstral coefficient) as a feature can be employed. Moreover, Cepstrum or Line Spectral Frequencies (LSF, other name “Line Spectral Pairs (LSP)”) may be used other than MFCC. In a voice processing apparatus, a processor performs generating a converted feature by applying a source feature of source voice to a conversion function, generating an estimated feature based on a probability that the source feature belongs to each element distribution of a mixture distribution model that approximates distribution of features of voices having different characteristics, generating a first conversion filter based on a difference between a first spectrum corresponding to the converted feature and an estimated spectrum corresponding to the estimated feature, generating a second spectrum by applying the first conversion filter to a source spectrum corresponding to the source feature, generating a second conversion filter based on a difference between the first spectrum and the second spectrum, and generating target voice by applying the first conversion filter and the second conversion filter to the source spectrum. 1. A voice processing apparatus comprising a processor configured to perform:
generating a converted feature by applying a source feature of source voice to a conversion function for voice characteristic conversion, the conversion function including a probability term representing a probability that a feature of voice belongs to each element distribution of a mixture distribution model that approximates distribution of features of voices having different characteristics; generating an estimated feature based on a probability that the source feature belongs to each element distribution of the mixture distribution model by applying the source feature to the probability term; generating a first conversion filter based on a difference between a first spectrum corresponding to the converted feature and an estimated spectrum corresponding to the estimated feature; generating a second spectrum by applying the first conversion filter to a source spectrum corresponding to the source feature; generating a second conversion filter based on a difference between the first spectrum and the second spectrum; and generating target voice by applying the first conversion filter and the second conversion filter to the source spectrum. 2. The voice processing apparatus according to smoothing the first spectrum and the second spectrum in a frequency domain thereof; and calculating a difference between the smoothed first spectrum and the smoothed second spectrum as the second conversion filter. 3. The voice processing apparatus according to sequentially selecting a plurality of phonemes as the source voice, so that each phoneme selected as the source voice is processed by the processor to sequentially generate a plurality of phonemes as the target voice; and connecting the plurality of the phonemes each generated as the target voice to synthesize an audio signal. 4. The voice processing apparatus according to 5. The voice processing apparatus according to 6. The voice processing apparatus according to 7. The voice processing apparatus according to 8. A voice processing method comprising the steps of:
generating a converted feature by applying a source feature of source voice to a conversion function for voice characteristic conversion, the conversion function including a probability term representing a probability that a feature of voice belongs to each element distribution of a mixture distribution model that approximates distribution of features of voices having different characteristics; generating an estimated feature based on a probability that the source feature belongs to each element distribution of the mixture distribution model by applying the source feature to the probability term; generating a first conversion filter based on a difference between a first spectrum corresponding to the converted feature and an estimated spectrum corresponding to the estimated feature; generating a second spectrum by applying the first conversion filter to a source spectrum corresponding to the source feature; generating a second conversion filter based on a difference between the first spectrum and the second spectrum; and generating target voice by applying the first conversion filter and the second conversion filter to the source spectrum. 9. The voice processing method according to smoothing the first spectrum and the second spectrum in a frequency domain thereof; and calculating a difference between the smoothed first spectrum and the smoothed second spectrum as the second conversion filter. 10. The voice processing method according to sequentially selecting a plurality of phonemes as the source voice, so that each phoneme selected as the source voice is processed to sequentially generate a plurality of phonemes as the target voice; and connecting the plurality of the phonemes each generated as the target voice to synthesize an audio signal. 11. The voice processing method according to 12. The voice processing method according to 13. The voice processing method according to 14. The voice processing method according to BACKGROUND OF THE INVENTION
SUMMARY OF THE INVENTION
BRIEF DESCRIPTION OF THE DRAWINGS
DETAILED DESCRIPTION OF THE INVENTION
First Embodiment
μqz=[μqxμqy] (2)Second Embodiment
Modifications