BARRIERLESS SNAPSHOTS
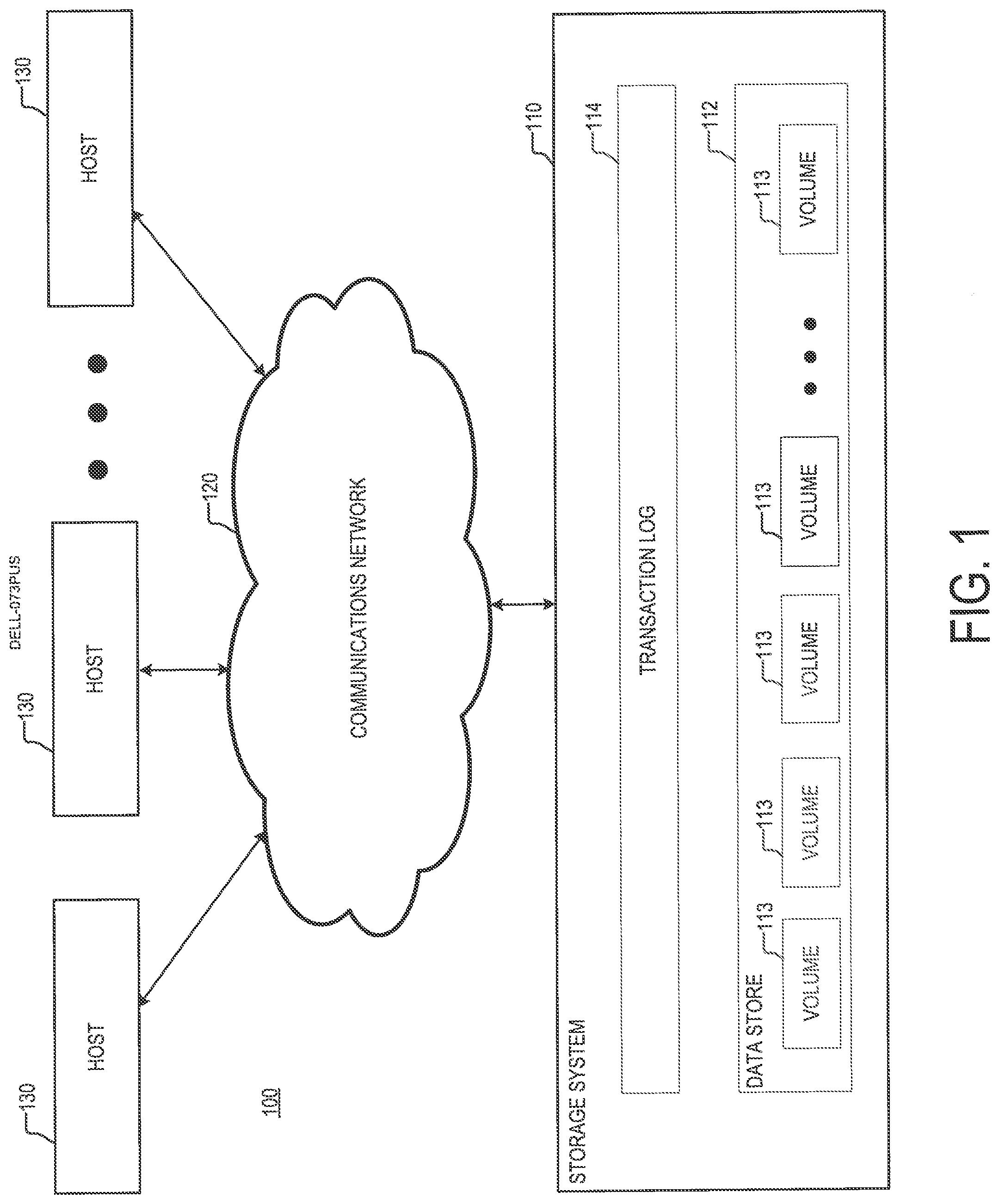
A distributed storage system may include a plurality of storage devices (e.g., storage arrays) to provide data storage to a plurality of nodes. The plurality of storage devices and the plurality of nodes may be situated in the same physical location, or in one or more physically remote locations. The plurality of nodes may be coupled to the storage devices by a high-speed interconnect, such as a switch fabric. This Summary is provided to introduce a selection of concepts in a simplified form that are further described below in the Detailed Description. This Summary is not intended to identify key features or essential features of the claimed subject matter, nor is it intended to be used to limit the scope of the claimed subject matter. According to aspects of the disclosure, a method is provided comprising: generating a snapshot of a volume in a storage system; generating a snapshot marker and adding the snapshot marker to a transaction log of the storage system; scanning the transaction log to identify one or more records that have been added to the transaction log before the snapshot marker, and marking each of the identified records as a splitflush record; flushing any record that is stored in the transaction log by: (a) detecting whether the record is marked as a splitflush record, (b) when the record is marked as a splitflush record, copying the record both to a data store and to the snapshot, and (c) when the record is not marked as a splitflush record, copying the record to the data store only. According to aspects of the disclosure, a system is provided comprising: a memory; one or more processors operatively coupled to the memory, the one or more processors being configured to perform the operations of: generating a snapshot of a volume in a storage system; generating a snapshot marker and adding the snapshot marker to a transaction log of the storage system; scanning the transaction log to identify one or more records that have been added to the transaction log before the snapshot marker, and marking each of the identified records as a splitflush record; flushing any record that is stored in the transaction log by: (a) detecting whether the record is marked as a splitflush record, (b) when the record is marked as a splitflush record, copying the record both to a data store and to the snapshot, and (c) when the record is not marked as a splitflush record, copying the record to the data store only. According to aspects of the disclosure, a non-transitory computer-readable medium is provided storing processor-executable instructions, which when executed by at least one processor cause the processor to perform the operations of: generating a snapshot of a volume in a storage system; generating a snapshot marker and adding the snapshot marker to a transaction log of the storage system; scanning the transaction log to identify one or more records that have been added to the transaction log before the snapshot marker, and marking each of the identified records as a splitflush record; flushing any record that is stored in the transaction log by: (a) detecting whether the record is marked as a splitflush record, (b) when the record is marked as a splitflush record, copying the record both to a data store and to the snapshot, and (c) when the record is not marked as a splitflush record, copying the record to the data store only. Other aspects, features, and advantages of the claimed invention will become more fully apparent from the following detailed description, the appended claims, and the accompanying drawings in which like reference numerals identify similar or identical elements. Reference numerals that are introduced in the specification in association with a drawing figure may be repeated in one or more subsequent figures without additional description in the specification in order to provide context for other features. Before describing embodiments of the concepts, structures, and techniques sought to be protected herein, some terms are explained. In some embodiments, the term “I/O request” or simply “I/O” may be used to refer to an input or output request. In some embodiments, an I/O request may refer to a data read or write request. The transaction log 114 may include a memory buffer where data is stored before being copied to one of the data volumes 113. In operation, the storage system 110 may receive a write request from any of the host devices 130, store data contained in the write request in the transaction log 114, and transmit, to the host device, an acknowledgment corresponding to the write request. After the acknowledgment is completed, the storage system 110 may copy the data from the transaction log 114 into any of the data volumes 113. In some respects, saving data into any of the data volumes 113 may take longer than storing data into the transaction log 114 because it may require additional operations such as calculating error codes or generating mapping metadata. In this regard, storing data (that is associated received write requests) in the transaction log 114 first, and then copying the data to the data store 112 (e.g., to one or more of the data volumes 113) enables the system to acknowledge received write requests at a faster rate, thus reducing the storage system's 110 overall response time. The tail pointer 206 may identify the oldest record 202 in the transaction log 114, which has not been flushed yet. Records 202 may be removed from the transaction log 114 in parallel from the tail of the transaction log 114. Specifically, when a record 202 (identified by the tail pointer 206) is removed from the transaction log 114, user data 210 (shown in The LSN 210 may include any suitable type of number, string, or alphanumerical string that indicates the order in which the record 202 is added to the transaction log 114. The LSN 210 may include a timestamp, a serial number, and/or any other incremental (or decremental) index that represents the location of the record 202 in the transaction log 114. For example, in some implementations, records 202 that are added to the transaction log 114 earlier may have smaller LSNs 210 that records 202 that are added later. As is further discussed below, the LSNs of the records 202 in the transaction log 114 may be used to determine the order in which the records 202 are added to the transaction log 114. The user data 220 may include any suitable type of data that is requested to be stored in one of the data volumes 113. For example, the user data 220 may include a page of data that is received with a write request at the storage system 110. The user data 220 may include documents, media, and/or any other data one might desire to store in the storage system 110. In some implementations, the user data 220 may include a page of data that is received with a write request from one of the host devices 130. The metadata 230 may include any suitable type of metadata that is needed for storing the user data 220 in one of the data volumes 113. In some implementations, the metadata may include one or more volume ID(s) 232, a logical block address (LBA) 234, and a marker 236. In some implementations, the metadata 230 may be extended to support more-than-one volume ownership of the records 202. As is further discussed below, the support of more-than-one volume owner allows generated volume snapshots to be updated with the contents of records 202 after the snapshots are generated. The capability to update already-generated snapshots allows the snapshots to be maintained in a consistent state, without the use of mechanisms such as barrier objects or sequential writing, which are known to degrade system performance. According to the present disclosure, a destination volume that is designated to receive the user data 220 may be referred to as an “owner” of the data. The volume ID(s) 232 may include a first volume ID 232 The LBA 234 may identify an address in the destination volume (identified by the first volume ID 232 In some implementations, writing a given record 202 to a data volume may include: identifying the data volume 113 that is referenced by the record's 202 first volume ID 232 Although the example of Turning to the process 500A, at step 502, a snapshot of a given data volume 113 is generated. At step 504, a copy record 250 is generated for the snapshot and added to the transaction log 114. The copy record 250 may include an LSN 210 (which identifies the time when the copy record 250 is generated and/or added to the transaction log), a volume ID 252 that identifies the given data volume 113, and a snapshot ID 254 that identifies the snapshot. In some implementations, the copy record may have (or be compliant with) the same interface as the records 202, and it may be usable with the same APIs that are used to process the records 202. At step 506, a scan is performed of the transaction log 114 to identify one or more records 202 that have been added to the transaction log 114 before the copy record 250. In some implementations, the one or more records 202 may be identified based on their respective LSN's 210. Additionally or alternatively, in some implementations, the identified records 202 may include only records 202 whose respective LSNs 210 are smaller than the LSN 210 of the copy record 250. Alternatively, in some implementations, the identified records 202 may include only records 202 whose respective LSNs 210 are larger than the LSN 210 of the copy record 250. Additionally or alternatively, in some implementations, the identified records 202 may include only records 202 which haven't been flushed yet (i.e., records that are not marked as “flushed” by their respective markers 236). Additionally or alternatively, in implementations in which the transaction log 114 contains records for multiple data volumes 113, each of the identified records 202 may be associated with the given data volume 113 whose snapshot is created at step 502, and as such, it can include a first volume ID 232 At step 508, each of the identified records 202 is marked as a splitflush record. In some implementations, marking any of the identified records 202 as a splitflush record may include inserting in that record 202 a second volume ID 232 Turning to the process 500B, at step 510, a new record 202 is detected, which has been added to the transaction log 114 after the copy record 250, and which is associated with the same storage location as a respective one of the records 202 that are marked as splitflush records (at step 508). In some implementations, a new record 202 may be associated with the same storage location as a respective (splitflush) record 202 when: (1) the first volume ID 232 At step 512, the respective (splitfulush) record 202 is unmarked. Unmarking the respective (splitflush) record 202 may include deleting from it the second volume ID 232 In some implementations, a snapshot generated may be in a consistent state when it can be used to restore all data (received with write requests) that has been acknowledged by a storage system prior to the creation of the snapshot. Storage systems in the prior art often use barrier objects to control the order in which records are flushed from a transaction log, so as to ensure that no acknowledged records remain unflushed prior to the creation of the snapshot. Using such barrier objects effectively causes all records that have been acknowledged prior to the creation of the snapshot to be flushed before the snapshot is created. However, in systems that use intensive snapshotting and a large number of barriers, this process may become unpredictable as it can introduce cross-data dependencies and block I/O processing as a result. The approach discussed with respect to In some implementations, when records 202 are marked as splitflush records (at step 508), only copies of the records 202 that are stored in volatile memory may be modified. In such implementations, any backup copies of the transaction log 114 that are stored in non-volatile memory would not be modified. However, the split flush markings can be easily recovered by using a recovery process, which is discussed further below with respect to In some implementations, the process 500A may be executed atomically (e.g., by using one or more locks) while any flushing of the log 114 is suspended. Executing the process 500B as an atomic operation may prevent the occurrence of race conditions. In the absence of atomic execution, such race conditions could occur when a record 250 is flushed from the log 114 after a snapshot is created, but before the record 250 is marked as a splitflush record. Shown in stage 710 is the state of a transaction log 701 at a time t0. As illustrated, at time t0, the transaction log 701 may include a plurality of records 702. In some implementations, the transaction log 701 may be the same or similar to the transaction log 114, which is discussed above with respect to respect to Shown in stage 720 is the state of the transaction log 701 at a time t1. As illustrated, at time t1, a copy record 704 is added to the transaction log 701. The copy record 704 may correspond to a snapshot of a data volume (e.g., Vol. 1). In some implementations, the copy record may be the same or similar to the copy record 250, which is discussed above with respect to respect to Shown in stage 730 is the state of the transaction log 701 at a time t2. As illustrated, at time t2, all records 702 that have been added to transaction log 701 before the copy record 704 are marked as splitflush records. In the present example, records 702A-C are marked. As noted above, marking the records 702 may include retrieving a snapshot identifier (e.g., Vo. 2) from the copy record 704, and inserting the retrieved snapshot identifier into the records 702A-C. Shown in stage 740 is the state of the transaction log 701 at a time t3. As illustrated, at time t3, a new record 702 is added to the transaction log 701, which identifies the same storage location as record 702A (i.e., Vol 1, LBA 0). Shown in stage 750 is the state of the transaction log 701 at a time t4. As illustrated, at time t4, the record 702A is unmarked. As illustrated, umparking the record 702 may include removing from the record 702A the snapshot identifier (i.e., Vo. 2), which was added at time t2. Referring to According to the example of Additionally, the term “or” is intended to mean an inclusive “or” rather than an exclusive “or”. That is, unless specified otherwise, or clear from context, “X employs A or B” is intended to mean any of the natural inclusive permutations. That is, if X employs A; X employs B; or X employs both A and B, then “X employs A or B” is satisfied under any of the foregoing instances. In addition, the articles “a” and “an” as used in this application and the appended claims should generally be construed to mean “one or more” unless specified otherwise or clear from context to be directed to a singular form. To the extent directional terms are used in the specification and claims (e.g., upper, lower, parallel, perpendicular, etc.), these terms are merely intended to assist in describing and claiming the invention and are not intended to limit the claims in any way. Such terms do not require exactness (e.g., exact perpendicularity or exact parallelism, etc.), but instead it is intended that normal tolerances and ranges apply. Similarly, unless explicitly stated otherwise, each numerical value and range should be interpreted as being approximate as if the word “about”, “substantially” or “approximately” preceded the value of the value or range. Moreover, the terms “system,” “component,” “module,” “interface,”, “model” or the like are generally intended to refer to a computer-related entity, either hardware, a combination of hardware and software, software, or software in execution. For example, a component may be, but is not limited to being, a process running on a processor, a processor, an object, an executable, a thread of execution, a program, and/or a computer. By way of illustration, both an application running on a controller and the controller can be a component. One or more components may reside within a process and/or thread of execution and a component may be localized on one computer and/or distributed between two or more computers. Although the subject matter described herein may be described in the context of illustrative implementations to process one or more computing application features/operations for a computing application having user-interactive components the subject matter is not limited to these particular embodiments. Rather, the techniques described herein can be applied to any suitable type of user-interactive component execution management methods, systems, platforms, and/or apparatus. While the exemplary embodiments have been described with respect to processes of circuits, including possible implementation as a single integrated circuit, a multi-chip module, a single card, or a multi-card circuit pack, the described embodiments are not so limited. As would be apparent to one skilled in the art, various functions of circuit elements may also be implemented as processing blocks in a software program. Such software may be employed in, for example, a digital signal processor, micro-controller, or general-purpose computer. Some embodiments might be implemented in the form of methods and apparatuses for practicing those methods. Described embodiments might also be implemented in the form of program code embodied in tangible media, such as magnetic recording media, optical recording media, solid state memory, floppy diskettes, CD-ROMs, hard drives, or any other machine-readable storage medium, wherein, when the program code is loaded into and executed by a machine, such as a computer, the machine becomes an apparatus for practicing the claimed invention. Described embodiments might also be implemented in the form of program code, for example, whether stored in a storage medium, loaded into and/or executed by a machine, or transmitted over some transmission medium or carrier, such as over electrical wiring or cabling, through fiber optics, or via electromagnetic radiation, wherein, when the program code is loaded into and executed by a machine, such as a computer, the machine becomes an apparatus for practicing the claimed invention. When implemented on a general-purpose processor, the program code segments combine with the processor to provide a unique device that operates analogously to specific logic circuits. Described embodiments might also be implemented in the form of a bitstream or other sequence of signal values electrically or optically transmitted through a medium, stored magnetic-field variations in a magnetic recording medium, etc., generated using a method and/or an apparatus of the claimed invention. It should be understood that the steps of the exemplary methods set forth herein are not necessarily required to be performed in the order described, and the order of the steps of such methods should be understood to be merely exemplary. Likewise, additional steps may be included in such methods, and certain steps may be omitted or combined, in methods consistent with various embodiments. Also, for purposes of this description, the terms “couple,” “coupling,” “coupled,” “connect,” “connecting,” or “connected” refer to any manner known in the art or later developed in which energy is allowed to be transferred between two or more elements, and the interposition of one or more additional elements is contemplated, although not required. Conversely, the terms “directly coupled,” “directly connected,” etc., imply the absence of such additional elements. As used herein in reference to an element and a standard, the term “compatible” means that the element communicates with other elements in a manner wholly or partially specified by the standard, and would be recognized by other elements as sufficiently capable of communicating with the other elements in the manner specified by the standard. The compatible element does not need to operate internally in a manner specified by the standard. It will be further understood that various changes in the details, materials, and arrangements of the parts which have been described and illustrated in order to explain the nature of the claimed invention might be made by those skilled in the art without departing from the scope of the following claims. A method is provided comprising: generating a snapshot of a volume in a storage system; generating a snapshot marker and adding the snapshot marker to a transaction log of the storage system; scanning the transaction log to identify one or more records that have been added to the transaction log before the snapshot marker, and marking each of the identified records as a splitflush record; flushing any record that is stored in the transaction log by: (a) detecting whether the record is marked as a splitflush record, (b) when the record is marked as a splitflush record, copying the record both to a data store and to the snapshot, and (c) when the record is not marked as a splitflush record, copying the record to the data store only. 1. A method comprising:
generating a snapshot of a volume in a storage system; generating a snapshot marker and adding the snapshot marker to a transaction log of the storage system; scanning the transaction log to identify one or more records that have been added to the transaction log before the snapshot marker, and marking each of the identified records as a splitflush record; flushing any record that is stored in the transaction log by: (a) detecting whether the record is marked as a splitflush record, (b) when the record is marked as a splitflush record, copying the record both to a data store and to the snapshot, and (c) when the record is not marked as a splitflush record, copying the record to the data store only. 2. The method of 3. The method of 4. The method of generating a recovered copy of the transaction log in response to a failure in the storage system; detecting that the snapshot marker is present in the recovered copy of the transaction log; scanning the recovered transaction log to identify one or records that have been added to the transaction log before the snapshot marker, and marking each of the identified records as a splitflush record. 5. The method of 6. The method of 7. The method of 8. A system comprising:
a memory; one or more processors operatively coupled to the memory, the one or more processors being configured to perform the operations of: generating a snapshot of a volume in a storage system; generating a snapshot marker and adding the snapshot marker to a transaction log of the storage system; scanning the transaction log to identify one or more records that have been added to the transaction log before the snapshot marker, and marking each of the identified records as a splitflush record; flushing any record that is stored in the transaction log by: (a) detecting whether the record is marked as a splitflush record, (b) when the record is marked as a splitflush record, copying the record both to a data store and to the snapshot, and (c) when the record is not marked as a splitflush record, copying the record to the data store only. 9. The system of 10. system of 11. The system of generating a recovered copy of the transaction log in response to a failure in the storage system; detecting that the snapshot marker is present in the recovered copy of the transaction log; scanning the recovered transaction log to identify one or records that have been added to the transaction log before the snapshot marker, and marking each of the identified records as a splitflush record. 12. The system of 13. The system of 14. The system of 15. A non-transitory computer-readable medium storing processor-executable instructions, which when executed by at least one processor cause the processor to perform the operations of:
generating a snapshot of a volume in a storage system; generating a snapshot marker and adding the snapshot marker to a transaction log of the storage system; scanning the transaction log to identify one or more records that have been added to the transaction log before the snapshot marker, and marking each of the identified records as a splitflush record; flushing any record that is stored in the transaction log by: (a) detecting whether the record is marked as a splitflush record, (b) when the record is marked as a splitflush record, copying the record both to a data store and to the snapshot, and (c) when the record is not marked as a splitflush record, copying the record to the data store only. 16. The non-transitory computer-readable medium of 17. The non-transitory computer-readable medium of 18. The non-transitory computer-readable medium of generating a recovered copy of the transaction log in response to a failure in the storage system; detecting that the snapshot marker is present in the recovered copy of the transaction log; scanning the recovered transaction log to identify one or records that have been added to the transaction log before the snapshot marker, and marking each of the identified records as a splitflush record. 19. The non-transitory computer-readable medium of 20. The non-transitory computer-readable medium of BACKGROUND
SUMMARY
BRIEF DESCRIPTION OF THE DRAWING FIGURES
DETAILED DESCRIPTION