VIRTUAL MACHINE BACKUP
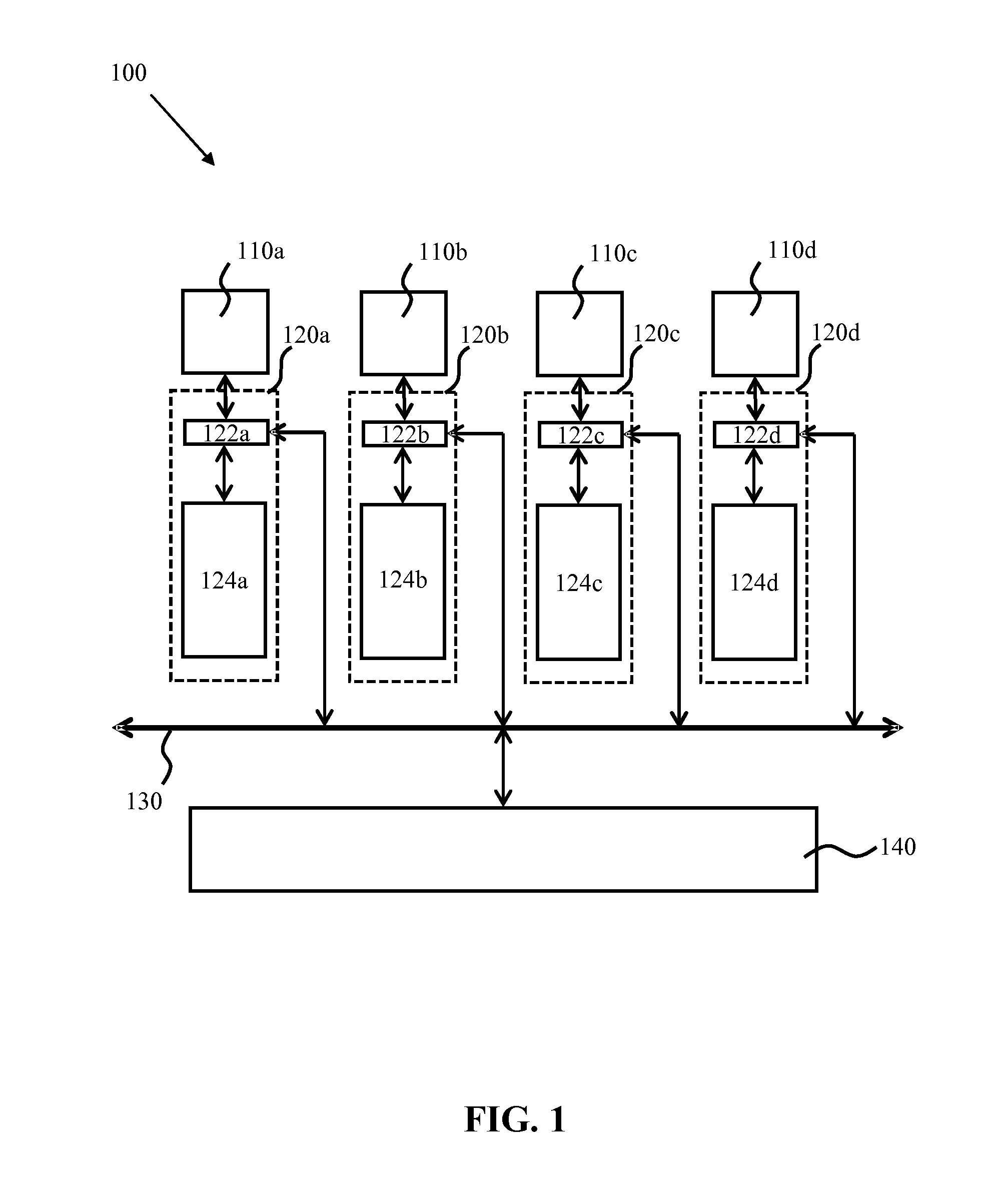
This application claims the priority under 35 U.S.C. §119 from United Kingdom Patent Application No. 1320537.2 filed on Nov. 21, 2013, which is incorporated by reference in its entirety. Embodiments of the inventive subject matter generally relate to the field of virtual machines and, more particularly, to hypervisors supporting one or more virtual machines. Virtualization is commonly applied on computer systems to improve the robustness of the implemented computing architecture to faults and to increase utilization of the resources of the architecture. In a virtualized architecture, one or more processor units, for example processors and/or processor cores, of the computer system act as the physical hosts of virtual machines (VMs), which are seen by the outside world as independent entities. This facilitates robustness of the architecture to hardware failures, as upon a hardware failure, a VM previously hosted by the failed hardware may be passed to another host, without the user of the virtual machine becoming aware of the hardware failure. This concept is an important facilitator of a “high availability” service provided by such a VM. Implementing a switch between two different hardware resources as a result of a failure is not a trivial task, as the VM ideally should be relaunched in a state that is identical to the state of the VM at the point of the hardware failure, in order to avoid inconvenience to the current user of the VM. In one approach, this is provided by running multiple copies of a single VM in lock-step on different entities, for example on different physical servers, such that upon the failure of one entity another entity can take over the responsibility for hosting the VM. A significant drawback of such lock-step arrangements is that processing resources are consumed by a failover copy of a VM, thus reducing the available bandwidth of the system, therefore reducing the total number of VMs that can be hosted by a system. In another approach, a physical host responds to a failure of another physical host by simply rebooting the VM from a shared disk state, for example a shared image of the VM. This however increases the risk of disk corruption and the loss of the exposed state of the VM altogether. In a different failover approach, all VM memory is periodically marked as read only to allow for changes to the VM memory to be replicated in a copy of the VM memory on another host. In this read-only state, a hypervisor is able to trap all writes that a VM makes to memory and maintain a map of pages that have been dirtied since the previous round. Each round, the migration process atomically reads and resets this map, and the iterative migration process involves chasing dirty pages until progress can no longer be made. This approach improves failover robustness because a separate up-to-date image of the VM memory is periodically created on a backup host that can simply launch a replica of the VM using this image following a hardware failure of the primary host. However, a drawback of this approach is that as the VM remains operational during the read-only state of its VM memory, a large number of page faults can be generated. In addition, this approach does not allow for the easy detection of which portion of a page has been altered, such that whole pages must be replicated even if only a single bit has been changed on the page, which is detrimental to the overall performance of the overall architecture, as for instance small page sizes have to be used to avoid excessive data traffic between systems, which reduces the performance of the operating system as the operating system is unable to use large size pages. Another failover approach discloses a digital computer memory cache organization implementing efficient selective cache write-back, mapping and transferring of data for the purpose of roll-back and roll-forward of, for example, databases. Write or store operations to cache lines tagged as logged are written through to a log block builder associated with the cache. Non-logged store operations are handled local to the cache, as in a write-back cache. The log block builder combines write operations into data blocks and transfers the data blocks to a log splitter. A log splitter demultiplexes the logged data into separate streams based on address. In short, the above approaches are not without problems. For instance, during suspension of the VM, the cache is sensitive to page faults as the cache is put into a read-only state. Furthermore, large amounts of data may have to be stored for each checkpoint, which causes pressure on the resource utilization of the computing architecture, in particular the data storage facilities of the architecture. Embodiments generally include a method that includes indicating, in a log, updates to memory of a virtual machine when the updates are evicted from a cache of the virtual machine. The method further includes determining a guard band for the log. The guard band indicates a threshold amount of free space for the log. The method further includes determining that the guard band will be or has been encroached upon corresponding to indicating an update in the log. The method further includes updating a backup image of the virtual machine based, at least in part, on a set of one or more entries of the log. The set of entries is sufficient to comply with the guard band. The method further includes removing the set of entries from the log. Embodiments include a computer system arranged to run a hypervisor running one or more virtual machines; a cache connected to the processor unit and comprising a plurality of cache rows, each cache row comprising a memory address, a cache line and an image modification flag; and a memory connected to the cache and arranged to store an image of at least one virtual machine; wherein: the processor unit is arranged to define a log in the memory; and the cache further comprises a cache controller arranged to: set the image modification flag for a cache line modified by a virtual machine being backed up; periodically check the image modification flags; and write only the memory address of the flagged cache rows in the defined log; and the processor unit is further arranged to monitor the free space available in the defined log and to trigger an interrupt if the free space available falls below a specific amount. Embodiments generally include a method of operating a computer system comprising a processor unit arranged to run a hypervisor running one or more virtual machines; a cache connected to the processor unit and comprising a plurality of cache rows, each cache row comprising a memory address, a cache line and an image modification flag; and a memory connected to the cache and arranged to store an image of at least one virtual machine; the method comprising the steps of defining a log in the memory; setting the image modification flag for a cache line modified by a virtual machine being backed up; periodically checking the image modification flags; writing only the memory address of the flagged cache rows in the defined log; monitoring the free space available in the defined log, and triggering an interrupt if the free space available falls below a specific amount. In some embodiments, a hypervisor is arranged to host a VM as well as act as a VM image replication manager to create a replica of a VM image in another location, for example in the memory of another computer system. As all changes made to an image of an active VM by the processor unit hosting the VM will travel through its cache, it is possible to simply log the memory address associated with a dirty cache line. To this end, the cache rows include an image modification flag that signal the modification of a cache line by the execution of the VM, and therefore, signal a change to the VM image. Including an image modification flag in the cache row allows the memory addresses of the dirty cache lines to be written to the log without requiring the expulsion of the dirty cache lines from the cache at the same time. Hence, the use of an image modification flag ensures that the memory addresses of the modified cache lines can be written to the log without at the same time requiring the cache lines to be flushed from the cache, which reduces the amount of data that needs to be transferred from the cache when updating the log. However, the image modification flag is only set if the change to a cache line is caused by a virtual machine operation that relates to a virtual machine being backed up. If the change to a cache line is caused by a virtual machine that has not been backed up or as the result of the hypervisor operating in privilege mode, then the image modification flag is not set. This reduces the amount of unnecessary data that is backed up at a checkpoint. The log is a circular buffer that contains some unprocessed log entries. The producer core writes new entries to the log, and registers indicate where the start and end of the unprocessed log entries are. When the log entries reach the end of the buffer, they wrap-around to the beginning As the consumer core processes entries, the “unprocessed log entries start here” register is updated. If the consumer core is unable to process the entries with sufficient speed, the processor core's entries can collide with the unprocessed log entries and this is the point at which a re-sync or failover must occur. A guard band is a space between the current location to which new logs are written and the start of the unprocessed entries. The processor unit is arranged to monitor the free space available in the log and to trigger an interrupt if the free space available falls below a specific amount (a guard band). If the head of the log entries moves to within the guard band, an interrupt is triggered. The size of the guard band may be static or dynamic in nature. The guard band should be large enough to contain all the data that might be emitted as part of a checkpoint. This means that when an interrupt is delivered on entry to the guard band, execution of the producer core can be halted and a cache flush initiated. At this point, all of the required log entries are in the circular buffer, and the producer core can be resumed once the consumer core has processed enough log entries to clear the backlog. This avoids the need to do a full memory re-sync or failover in the event that the consumer core is unable to keep up with the producer core. The specific amount of minimum free space available in the log (the guard band which triggers the interrupt) comprises a predetermined amount derived from a sum of the write-back cache sizes, a component representing the number of instructions in the CPU pipeline that have been issued but not yet completed and a component representing the number of new instructions that will be issued in the time taken for an interrupt to be delivered to the processor core. This ensures that the space in the log is large enough to hold the worst-case scenario, which is essentially that all existing cache-lines are dirty, all pending instructions will create new dirty cache lines and all new instructions created while the interrupt is being delivered will also create new dirty cache lines. The processor unit is arranged to run multiple execution threads, in a technique commonly referred to as “Simultaneous Multithreading (SMT).” The hypervisor is arranged to maintain a thread mask, flagging those threads that relate to one or more virtual machines being backed up. When setting the image modification flag for a cache line modified by a virtual machine being backed up, the hypervisor refers to the thread mask to determine whether to set the image modification flag for the current cache line being modified. Each cache row further comprises a thread ID indicating which execution thread is responsible for modification of the cache line in the respective cache row. A single bitfield register, called a thread mask, is added to each processor unit, with a number of bits equal to the number of hardware threads supported by that unit, and hypervisor-privileged operations added to set those bits. The hypervisor (which knows which virtual machines are running on which hardware threads) sets the associated bits in the thread mask for the hardware threads that are running virtual machines that require checkpoint-based high-availability protection. A new field, thread ID, is added alongside the image modification flag on every cache line. The thread ID field is sufficiently large to contain the ID of the hardware thread that issued the store operation (i.e., two bits if four hardware threads are supported). When a store is performed, the image modification flag is set in the cache, only if the store was not executed when running in the hypervisor privilege mode and if the thread mask bit corresponding to the currently executing hardware thread is set. As well as setting the image modification flag, these store operations can also write the ID of the hardware thread that issued the store to the cache line's thread ID field. When cache lines are logged during a cast-out, snoop intervention or cache-clean operation, the contents of the thread ID field associated with the cache line are also written to the log. Alternatively, the log record is directed to a different log based on the value of the thread ID, with the processor core capable of storing position and size information for multiple logs. When this alternative is used, it is not necessary to write the thread ID field to the log. The above aspects allow multiple virtual machines to execute on a single processor unit concurrently, with any number of them running with checkpoint-based high-availability protection. The presence of the thread ID in the logs, coupled with the hypervisor's record of which virtual machines are currently running on which processor cores and hardware threads, is sufficient to allow the secondary host (the memory location where the backup image is stored) to update the correct virtual machine memory image on receipt of the logs. The cache controller typically is further adapted to write the memory address of a flagged cache line in the defined log upon the eviction of the flagged line from the cache. This captures flagged changes to the VM image that are no longer guaranteed to be present in the cache during the periodic inspection of the image modification tags. The computer system is further arranged to update a backup image of the virtual machine in a different memory location by retrieving the memory addresses from the log; obtaining the modified cache lines using the retrieved memory addresses; and updating the further image with said modified cache lines. The logged memory addresses are used to copy the altered data of the primary image to the copy of the VM image, which copy may for instance be located on another computer system. In this manner, VM images may be synchronized without incurring additional page faults and reduces the traffic between systems due to the smaller granularity of the data modification, i.e. cache line-size rather than page size. Due to the fact that the VM is suspended during image replication, no page protection is necessary. This approach is furthermore page size-agnostic such that various page sizes can be used. Moreover, the additional hardware cost to the computer system is minimal; only minor changes to the cache controller, for example to the cast-out engine and the snoop-intervention engine of the cache controller, and to the cache rows of the cache are required to ensure that the cache controller periodically writes the memory address of the dirty cache line in the log through periodic inspection of the image modification flag during execution of the VM. The computer system may replicate data from the primary VM image to a copy in push or pull fashion. In a push implementation, a processor unit from the same computer system, for example the processor unit running the VM or a different processor unit, may be also responsible, under control of the hypervisor, for updating the copy of the image of the VM in the different memory location, which may be a memory location in the memory of the same computer system or a memory location in the memory of a different computer system. In a pull implementation, a processor unit of a different computer system may be adapted to update the copy of the VM image in the memory location on this different computer system by pulling the memory addresses and associated modified cache lines from the computer system hosting the VM. The cache may include a write-back cache, which may form part of a multi-level cache further including a write-through cache adapted to write cache lines into the write-back cache, wherein only the cache rows of the write-back cache comprise the flag. As by definition the cache lines in a write-through cache cannot get dirty because cache line modifications are also copied to a write-back cache, only the write-back caches need inspecting when periodically writing the memory addresses to the log. As mentioned above the log which stores the addresses of changed cache lines is a circular buffer and the system comprises a plurality of registers adapted to store a first pointer to a wrap-around address of the circular buffer, a second pointer to the next available address of the circular buffer, a third pointer to an initial address of the circular buffer, and the size of the circular buffer. The cache controller is adapted to update at least the second pointer following the writing of a memory address in the log. Each processor unit is configured to deduplicate the memory addresses in the log prior to the retrieval of the addresses from the log. This reduces the amount of time required for synchronizing data between the memories by ensuring that the altered data in a logged memory location is copied once only. In this manner, the log is updated with the memory addresses of the modified cache lines without the need to flush the modified cache lines from the cache at the same time. The processor unit typically further performs the step of writing the memory address of a flagged cache line in the defined log upon the eviction of said flagged line from the cache to capture flagged changes to the VM image that no longer are guaranteed to be present in the cache during the periodic inspection of the image modification tags. Embodiments of the present inventive subject matter will now be described, by way of example, with reference to the following drawings, in which: Each processor unit 110 In the embodiment shown in Each processor unit 110 The computer system 100 further comprises a memory 140 coupled to the bus architecture 130, which again may take any suitable form, for example a memory integrated in the computer system or a distributed memory accessible over a network. The memory 140 is connected to the caches 120 The computer system 100 is adapted to host one or more virtual machines on the processor units 110 One of the attractions of virtualization is improved robustness due to the ability to provide failover between VMs, which means that should a VM fail, a backup VM is available that will continue to provide the VM functionality to the user. To this end, a copy of a VM is periodically updated so that the copy represents the actual current state of the original VM in case the original VM exhibits a failure and will have to failover to the copy VM. The original VM will be referred to as the primary VM and its copy will be referred to as the secondary VM. Such synchronization between the primary VM and the secondary VM requires the temporary suspension of the primary VM so that its state does not change during the synchronization. The duration of such suspension should be minimized such that the one or more users of the VM are not noticeably affected by the temporary suspension. Typically, to avoid performance penalties, differential checkpoints which capture changes in the state of an entity since the last checkpoint are created. Such checkpoints may be generated by writing the address and data from a cache line to a secondary memory such as a level-2 cache or the system memory 140 as soon as the data in a cache line is altered. When using such checkpoint generation for VM replication purposes, it has the drawback that a large amount of data may be unnecessarily communicated during operation of the primary VM. For instance, if a cache line of the cache 120 An example architecture of the data storage part 124 The cache rows 1210 of a cache 120 The processor unit 110 In a preferred embodiment, the memory address log in the memory 140 has a defined size and allocation to avoid corruption of the memory 140. Any suitable implementation of such a log may be chosen. A particularly suitable implementation is shown in In order to facilitate the management of the log 200 during the execution of a VM on the processor unit 110 The hardware architecture of the cache controller 122 is adapted to traverse the cache 120 When using an embodiment similar to that shown in Under both models, any change to the hardware thread-to-VM assignment (for example scheduling a VM to run on a hardware thread on which it was not previously running) would require a cache-clean operation to ensure that any image modification flag data for the virtual machine that was previously running on the hardware thread had been pushed out to the log 200 prior to the switch taking place, and the hypervisor should note at which point in the log the virtual machine switched from one to another, so that the processor unit 110 In some implementations, the cache clean operation could be extended to only target specific thread IDs, allowing the operation to selectively clean only the cache lines associated with hardware threads that are being reassigned to another virtual machine. This would reduce the number of unnecessary log entries that were produced if, for example, three hardware threads were running code for virtual machine 0, and a fourth running code for virtual machine 1. A reassignment to have the fourth hardware thread run code for virtual machine 2 only requires that cache lines associated with the fourth hardware thread been written to the in-memory buffer before it can start executing code for virtual machine 2. The process of setting the image modification flag 1217 is explained in more detail with the aid of In addition, the cache controller 122 performs a number of checks in step 420, which checks have been identified in If the cache access does not lead to the modification of a cache line but instead causes the eviction of a cache line from the cache 120 It is noted that the checks 420′, 420″ and 420″′ are shown as a sequence of steps for the sake of clarity only. It should be understood that the cache controller 122 does not have to perform each of these checks to decide what cause of action should be taken next. It is for instance equally feasible that the cache controller 122 may immediately recognize that a cache line eviction or a VM image replication is required, in which case the cache controller 122 may proceed from step 420 directly to step 435 or step 460 respectively. Upon detecting the checkpoint generation instruction in step 420″′, the cache controller 122 traverses the cache 120 At this point, the pointer in register 214 will need updating to ensure that no memory addresses are overwritten. The pointer is updated by the cache controller 122, by the replication manager or by the hypervisor of the processor unit 110 It is furthermore necessary to check if the next available address in the log 200 to be stored in register 214 should be wrapped around to the base address. In some implementations, the cache controller 122 or the replication manager of the processor unit 110 After completing step 470, the cache controller 122 subsequently resets the VM image modification flag to false in step 480. Step 480 may be executed at any suitable point in time, for example after each write action to the log 200, or after all write actions to the log 200 have been completed. At this point, it is reiterated that any suitable cache architecture may be used for the cache 120 At this point, the replication manager may trigger the replication of the VM image in memory 140 to another memory location, such as another memory or cache, by accessing the log 200, fetching the addresses stored in the log 200, fetching the cache lines stored at the fetched addresses and updating a copy of the VM image in the other memory location with the fetched cache lines, as previously explained. It should be understood that the replication manager triggering the flush of the cache line addresses and the subsequent update of the secondary image of the VM does not have to be the replication manager of the processor unit 110 Generally, the embodiments in which the processor unit in charge of the VM image update process resides on the same computer system 100 as the processor unit 110 Upon writing the memory addresses of the modified cache lines 1214 in the log 200 in step 470, the method may further comprise the optional step of deduplicating addresses in the log 200 to remove multiple instances of the same address in the log 200. This for instance can occur if the frequency at which memory addresses are written to the log 200 is higher than the frequency at which the memory addresses in the log 200 are used to update a secondary VM image. At this point, it is noted that the process of The flowchart of For instance, a further processor unit 110 The update of the VM image replica ensures that a processor unit 110 In some implementations, the second operating mode is not a separate operating mode but forms part of the first operating mode, in which case the processor unit 110 It should be understood that in a computer cluster comprising multiple computer systems 100, some processor units 110 Upon retrieving the relevant information, the consumer processor unit 110 The consumer processor unit 110 It should be immediately apparent to the skilled person that various modifications may be possible to the method shown in In some implementations, a processor unit 110 An example flowchart of this implementation is shown in Step 610 ensures that the available space in the log 200 of the processor unit 110 In some implementations, as soon as the primary VM becomes suspended, step 610 may be omitted from the process of The above description describes modifying the cache hardware so that at regular intervals the circular buffer 200 in memory contains a list of all memory locations that have been modified by a given processor core since the last checkpoint. This is achieved by modifications to the cast-out engine and snoop-intervention engine in order to store in the log 200 memory addresses leaving the cache between checkpoints, and at a checkpoint there is initiated a cache flush to ensure that no modified data remains in the cache (thereby ensuring that dirty cache lines pass through the cast-out engine and thus are logged). If the circular buffer 200 becomes full, a full re-sync of memory must occur, or an immediate failover to the secondary system. This problem is addressed by ensuring that there is always sufficient space in the circular buffer 200 to accept any dirty data in the cache. As shown in However, to avoid this occurring, there is used a guard band, which is the available space between the current location to which new logs are written, and the start of the unprocessed entries, which is shown in In some implementations, the guard band can be sized statically based on the worst-case possibility that, at the point where the guard band is reached it is assumed that all logged caches are full of dirty data, all instructions in the CPU pipeline that have been issued but have not yet completed are “store”-type instructions, and each of them will push out a dirty cache line (and thus emit a log entry) and create a new dirty cache line and in the time it takes for the interrupt to be delivered from the consumer cache to the consumer core, a certain number of new instructions will be issued, and each of those instructions are “store”-type operations, and each will push out a dirty cache line (and thus emit a log entry) and create a new dirty cache line. Thus, in an implementation with a write-though L1 cache, and write-back L2 and L3 caches, the required guard band size is: sizeof(L2)+sizeof(L3)+worstcase(PIPELINE)+worstcase(INTERRUPT) All of these elements are computable based on the architecture of a given microprocessor. In a further implementation, the cache-size related elements can be computed based on the number of dirty cache lines currently in the cache, rather than the worst-case number. This means that the size of the guard band can vary dynamically based on the number of log entries that would be emitted during the cache flush operation at the checkpoint. This is trivial to maintain within the cache, which is responsible for both tracking the fullness of the cache and also ensuring that the guard band is not reached. The PIPELINE and INTERRUPT portions of the calculation would remain constant. It should be understood that in the context of the present inventive subject matter, a computer system is to be interpreted as a device that includes a collection of processor elements that can be utilized in unison. This does not necessarily equate to a single physical entity; it is equally feasible that a computer system is distributed over several physical entities, for example different boxes, or that a single physical entity includes more than one computer systems, for example several separate groups of processor units. As will be appreciated by one skilled in the art, aspects of the present inventive subject matter may be embodied as a system, method or computer program product. Accordingly, aspects of the present inventive subject matter may take the form of an entirely hardware embodiment, an entirely software embodiment (including firmware, resident software, micro-code, etc.) or an embodiment combining software and hardware aspects that may all generally be referred to herein as a “circuit,” “module” or “system.” Furthermore, aspects of the present inventive subject matter may take the form of a computer program product embodied in one or more computer readable medium(s) having computer readable program code embodied thereon. Any combination of one or more computer readable medium(s) may be utilized. The computer readable medium may be a computer readable signal medium or a computer readable storage medium. A computer readable storage medium may be, for example, but not limited to, an electronic, magnetic, optical, electromagnetic, infrared, or semiconductor system, apparatus, or device, or any suitable combination of the foregoing. More specific examples (a non-exhaustive list) of the computer readable storage medium would include the following: an electrical connection having one or more wires, a portable computer diskette, a hard disk, a random access memory (RAM), a read-only memory (ROM), an erasable programmable read-only memory (EPROM or Flash memory), an optical fiber, a portable compact disc read-only memory (CD-ROM), an optical storage device, a magnetic storage device, or any suitable combination of the foregoing. In the context of this document, a computer readable storage medium may be any tangible medium that can contain, or store a program for use by or in connection with an instruction execution system, apparatus, or device. A computer readable signal medium may include a propagated data signal with computer readable program code embodied therein, for example, in baseband or as part of a carrier wave. Such a propagated signal may take any of a variety of forms, including, but not limited to, electro-magnetic, optical, or any suitable combination thereof. A computer readable signal medium may be any computer readable medium that is not a computer readable storage medium and that can communicate, propagate, or transport a program for use by or in connection with an instruction execution system, apparatus, or device. Program code embodied on a computer readable medium may be transmitted using any appropriate medium, including but not limited to wireless, wireline, optical fiber cable, RF, etc., or any suitable combination of the foregoing. Computer program code for carrying out operations for aspects of the present inventive subject matter may be written in any combination of one or more programming languages, including an object oriented programming language such as Java, Smalltalk, C++ or the like and conventional procedural programming languages, such as the “C” programming language or similar programming languages. The program code may execute entirely on the user's computer, partly on the user's computer, as a stand-alone software package, partly on the user's computer and partly on a remote computer or entirely on the remote computer or server. In the latter scenario, the remote computer may be connected to the user's computer through any type of network, including a local area network (LAN) or a wide area network (WAN), or the connection may be made to an external computer (for example, through the Internet using an Internet Service Provider). Aspects of the present inventive subject matter are described below with reference to flowchart illustrations and/or block diagrams of methods, apparatus (systems) and computer program products according to implementations of the inventive subject matter. It will be understood that each block of the flowchart illustrations and/or block diagrams, and combinations of blocks in the flowchart illustrations and/or block diagrams, can be implemented by computer program instructions. These computer program instructions may be provided to a processor of a general purpose computer, special purpose computer, or other programmable data processing apparatus to produce a machine, such that the instructions, which execute via the processor of the computer or other programmable data processing apparatus, create means for implementing the functions/acts specified in the flowchart and/or block diagram block or blocks. These computer program instructions may also be stored in a computer readable medium that can direct a computer, other programmable data processing apparatus, or other devices to function in a particular manner, such that the instructions stored in the computer readable medium produce an article of manufacture including instructions which implement the function/act specified in the flowchart and/or block diagram block or blocks. The computer program instructions may also be loaded onto a computer, other programmable data processing apparatus, or other devices to cause a series of operational steps to be performed on the computer, other programmable apparatus or other devices to produce a computer implemented process such that the instructions which execute on the computer or other programmable apparatus provide processes for implementing the functions/acts specified in the flowchart and/or block diagram block or blocks. The flowchart and block diagrams in the Figures illustrate the architecture, functionality, and operation of possible implementations of systems, methods and computer program products according to various embodiments of the present inventive subject matter. In this regard, each block in the flowchart or block diagrams may represent a module, segment, or portion of code, which comprises one or more executable instructions for implementing the specified logical function(s). It should also be noted that, in some implementations, the functions noted in the block may occur out of the order noted in the figures. For example, two blocks shown in succession may, in fact, be executed substantially concurrently, or the blocks may sometimes be executed in the reverse order, depending upon the functionality involved. It will also be noted that each block of the block diagrams and/or flowchart illustration, and combinations of blocks in the block diagrams and/or flowchart illustration, can be implemented by special purpose hardware-based systems that perform the specified functions or acts, or combinations of special purpose hardware and computer instructions. While particular implementations of the present inventive subject matter have been described herein for purposes of illustration, many modifications and changes will become apparent to those skilled in the art. Accordingly, the appended claims are intended to encompass all such modifications and changes as fall within the true spirit and scope of the present inventive subject matter. A computer system comprises a processor unit arranged to run a hypervisor running one or more virtual machines, a cache connected to the processor unit and comprising a plurality of cache rows, each cache row comprising a memory address, a cache line and an image modification flag and a memory connected to the cache and arranged to store an image of at least one virtual machine. The processor unit is arranged to define a log in the memory and the cache further comprises a cache controller arranged to set the image modification flag for a cache line modified by a virtual machine being backed up, periodically check the image modification flags and write only the memory address of the flagged cache rows in the defined log. The processor unit is further arranged to monitor the free space available in the defined log and to trigger an interrupt if the free space available falls below a specific amount. 1. A method comprising:
indicating, in a log, updates to memory of a virtual machine when the updates are evicted from a cache of the virtual machine; determining a guard band for the log, wherein the guard band indicates a threshold amount of free space for the log; determining that the guard band will be or has been encroached upon corresponding to indicating an update in the log; updating a backup image of the virtual machine based, at least in part, on a set of one or more entries of the log, wherein the set of entries is sufficient to comply with the guard band; and removing the set of entries from the log. 2. The method of determining a number of write-back cache lines in the cache; determining a number of instructions in a pipeline for a processor unit that executes instructions issued by the virtual machine; determining a number of additional instructions capable of being issued to the pipeline in the time taken to trigger an interrupt of the processor unit; and defining the guard band based on a sum of the determined number of write-back cache lines, the determined number of instructions, and the determined number of additional instructions. 3. The method of determining a number of dirty cache lines in the cache; determining a number of store instructions in a pipeline for a processor unit that executes instructions issued by the virtual machine; determining a number of additional instructions capable of being issued to the pipeline in the time taken to trigger an interrupt of the processor unit; and defining the guard band based on a sum of the determined number of dirty cache lines, the determined number of store instructions, and the determined number of additional instructions. 4. The method of 5. The method of 6. The method of 7. The method of 8. A computer program product for maintaining a backup image of a virtual machine comprising:
a computer readable storage medium having program instructions embodied therewith, the program instructions comprising program instructions to, indicate, in a log, updates to memory of a virtual machine when the updates are evicted from a cache of the virtual machine; determine a guard band for the log, wherein the guard band indicates a threshold amount of free space for the log; determine that the guard band will be or has been encroached upon corresponding to indicating an update in the log; update a backup image of the virtual machine based, at least in part, on a set of one or more entries of the log, wherein the set of entries is sufficient to comply with the guard band; and remove the set of entries from the log. 9. The computer program product of determine a number of write-back cache lines in the cache; determine a number of instructions in a pipeline for a processor unit that executes instructions issued by the virtual machine; determine a number of additional instructions capable of being issued to the pipeline in the time taken to trigger an interrupt of the processor unit; and define the guard band based on a sum of the determined number of write-back cache lines, the determined number of instructions, and the determined number of additional instructions. 10. The computer program product of determine a number of dirty cache lines in the cache; determine a number of store instructions in a pipeline for a processor that executes instructions issued by the virtual machine; determine a number of additional instructions capable of being issued to the pipeline in the time taken to trigger an interrupt of the processor unit; and define the guard band based on a sum of the determined number of dirty cache lines, the determined number of store instructions, and the determined number of additional instructions. 11. The computer program product of 12. The computer program product of 13. The computer program product of 14. An apparatus comprising:
a processor; and a computer readable storage medium having program instructions embodied therewith, the program instructions executable by the processor to cause the apparatus to, indicate, in a log, updates to memory of a virtual machine when the updates are evicted from a cache of the virtual machine; determine a guard band for the log, wherein the guard band indicates a threshold amount of free space for the log; determine that the guard band will be or has been encroached upon corresponding to indicating an update in the log; update a backup image of the virtual machine based, at least in part, on a set of one or more entries of the log, wherein the set of entries is sufficient to comply with the guard band; and remove the set of entries from the log. 15. The apparatus of determine a number of write-back cache lines in the cache; determine a number of instructions in a pipeline for the processor; determine a number of additional instructions capable of being issued to the pipeline in the time taken to trigger an interrupt of the processor; and define the guard band based on a sum of the determined number of write-back cache lines, the determined number of instructions, and the determined number of additional instructions. 16. The apparatus of determine a number of dirty cache lines in the cache; determine a number of store instructions in a pipeline for the processor; determine a number of additional instructions capable of being issued to the pipeline in the time taken to trigger an interrupt of the processor; and define the guard band based on a sum of the determined number of dirty cache lines, the determined number of store instructions, and the determined number of additional instructions. 17. The apparatus of 18. The apparatus of 19. The apparatus of RELATED APPLICATIONS
FIELD OF THE INVENTION
BACKGROUND
BRIEF SUMMARY OF THE INVENTION
BRIEF DESCRIPTION OF THE DRAWINGS
DETAILED DESCRIPTION OF THE EMBODIMENTS