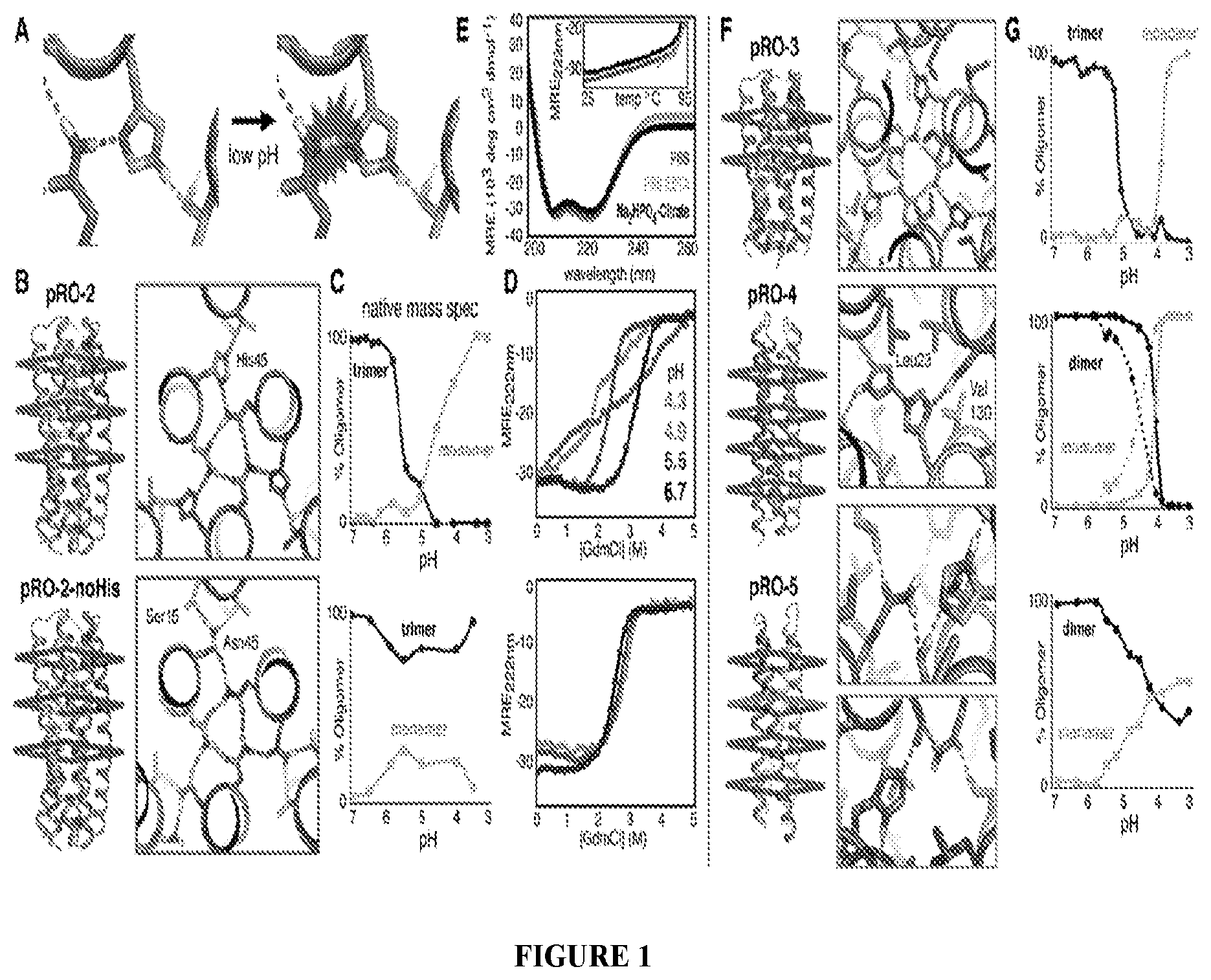
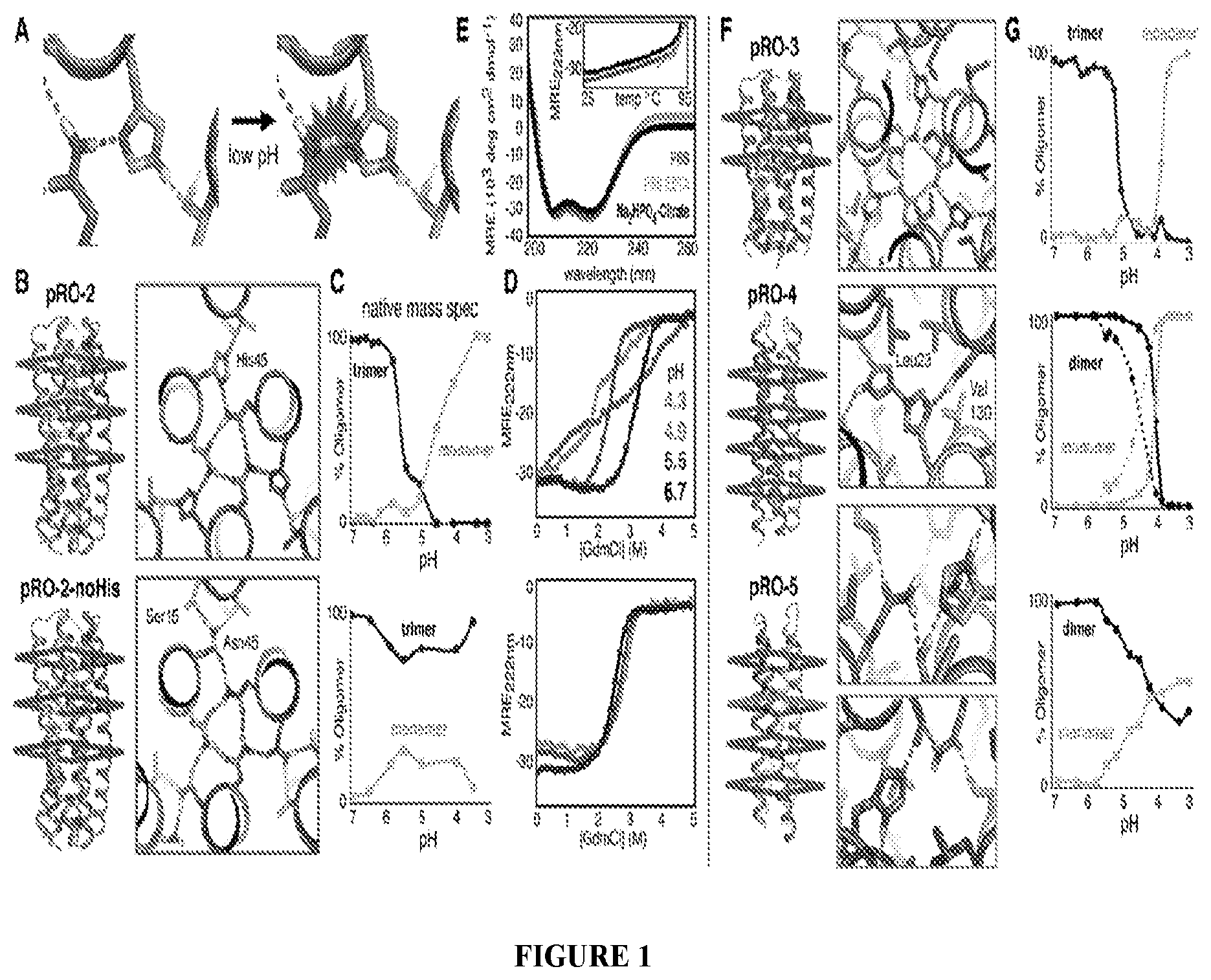
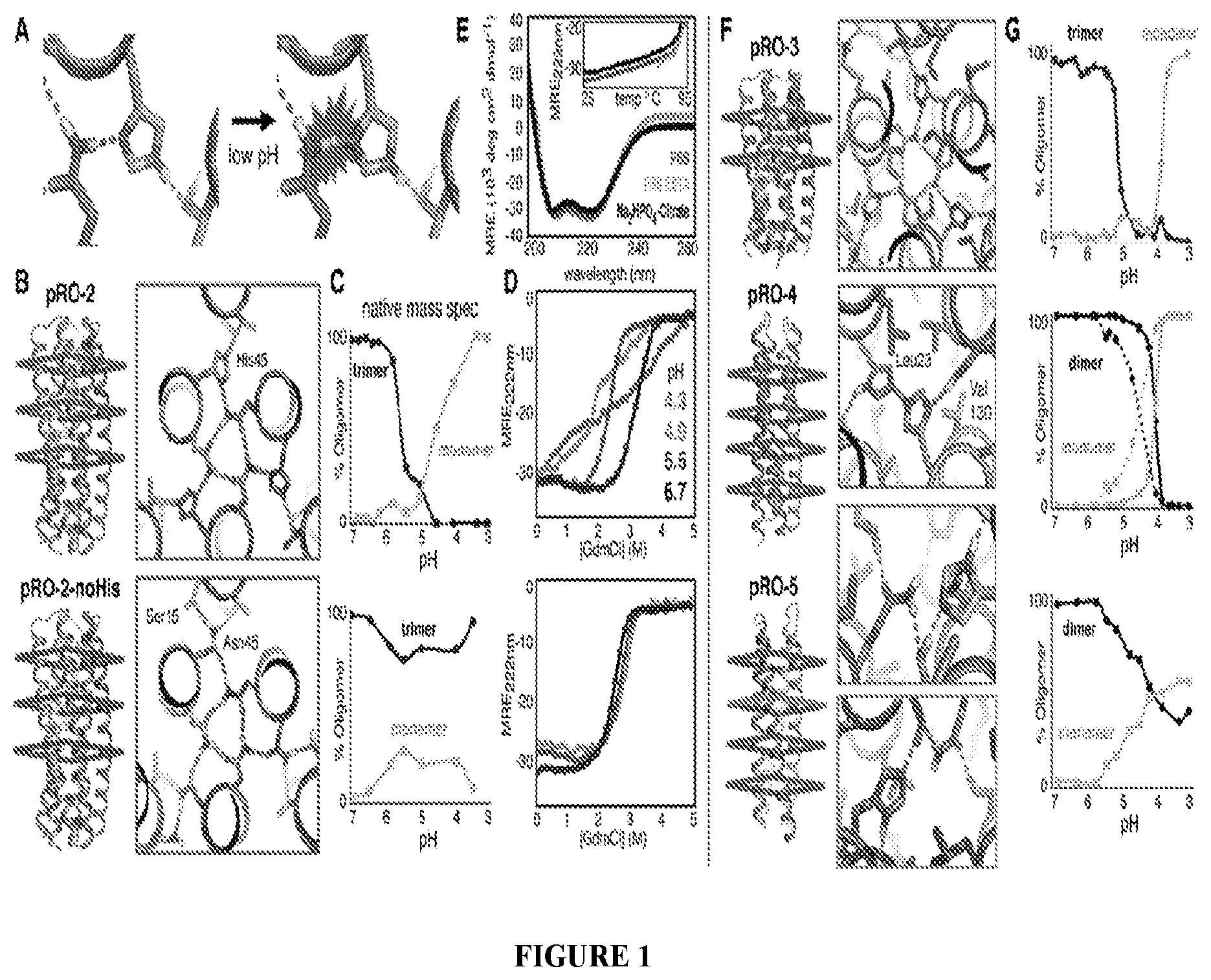
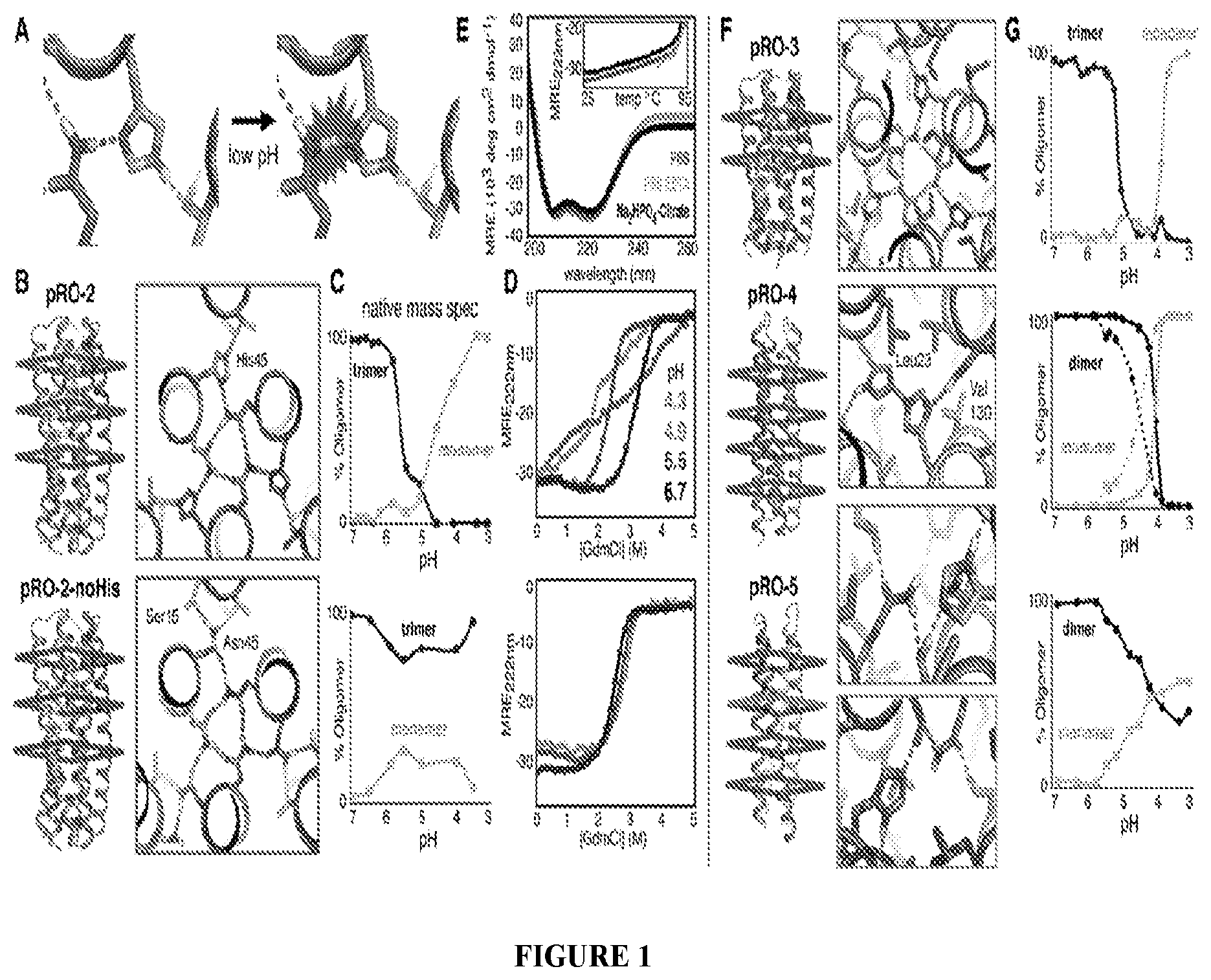
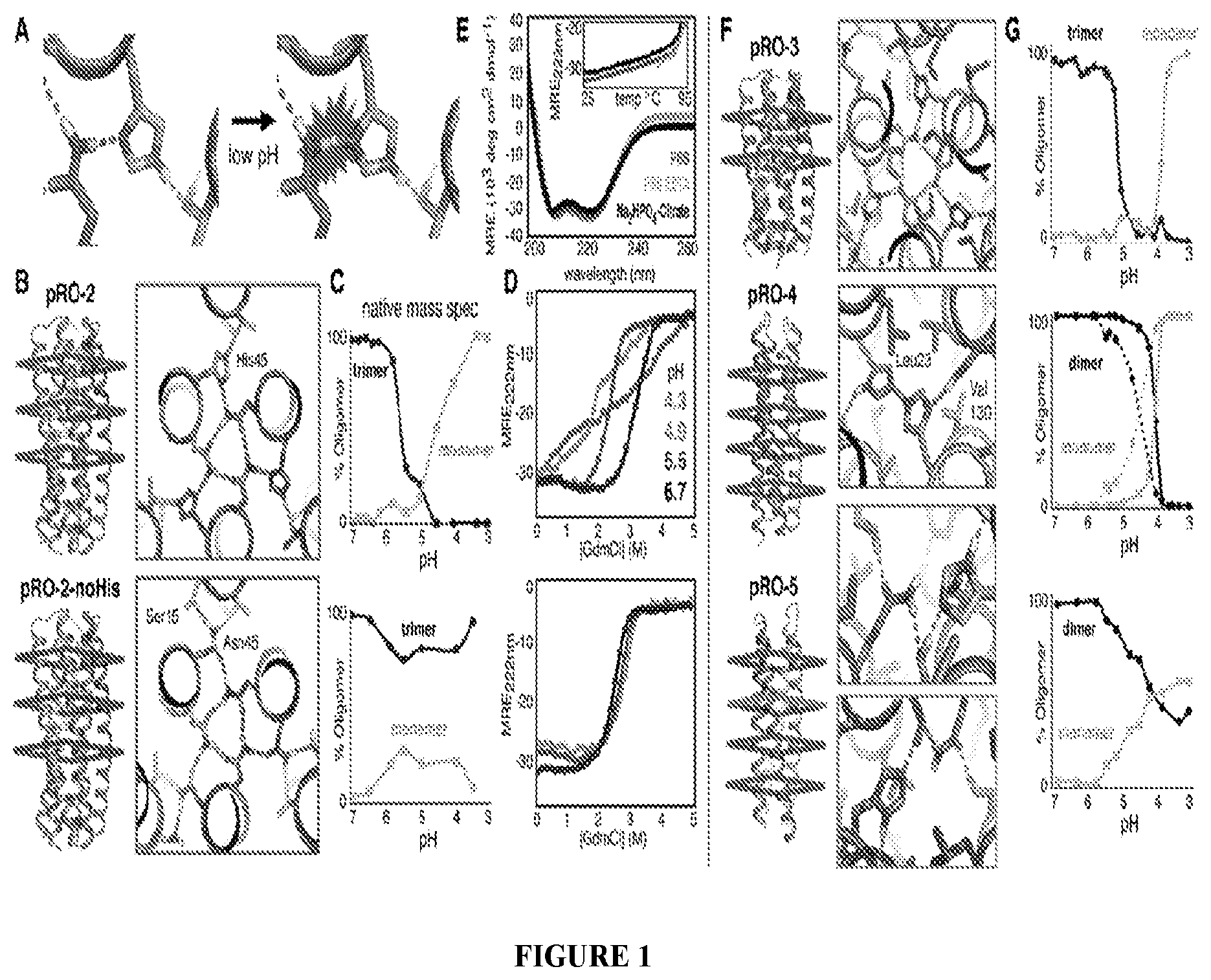
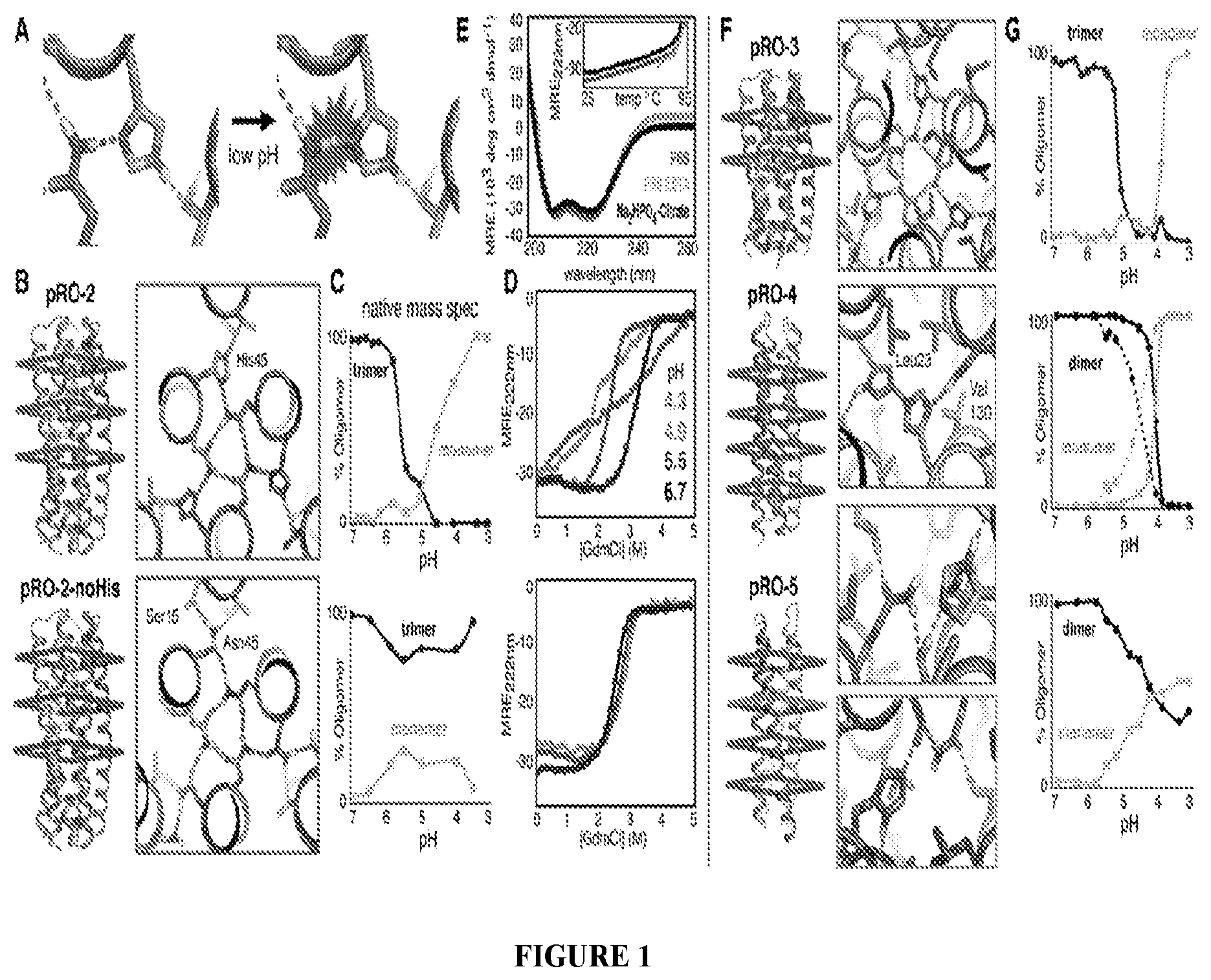
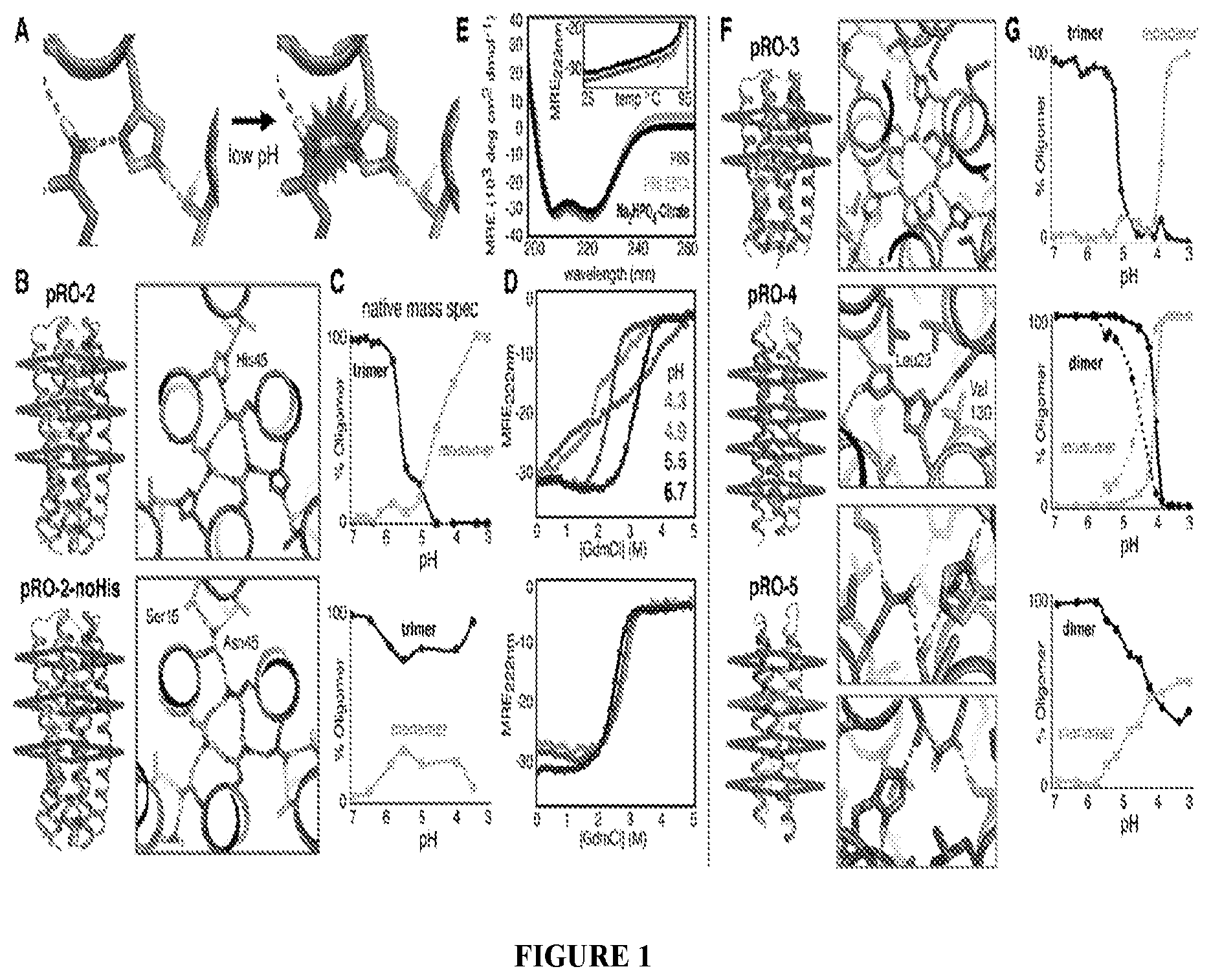
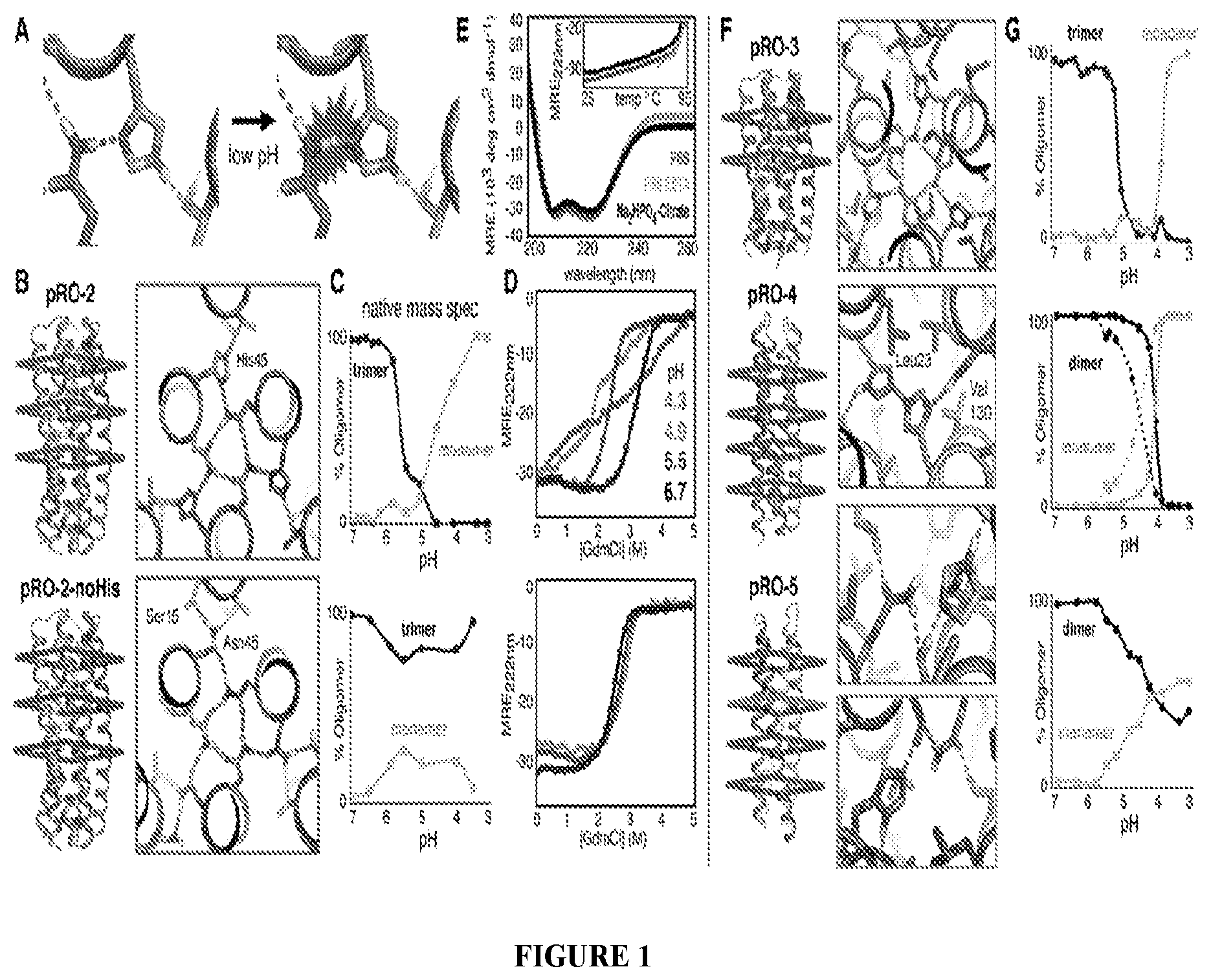
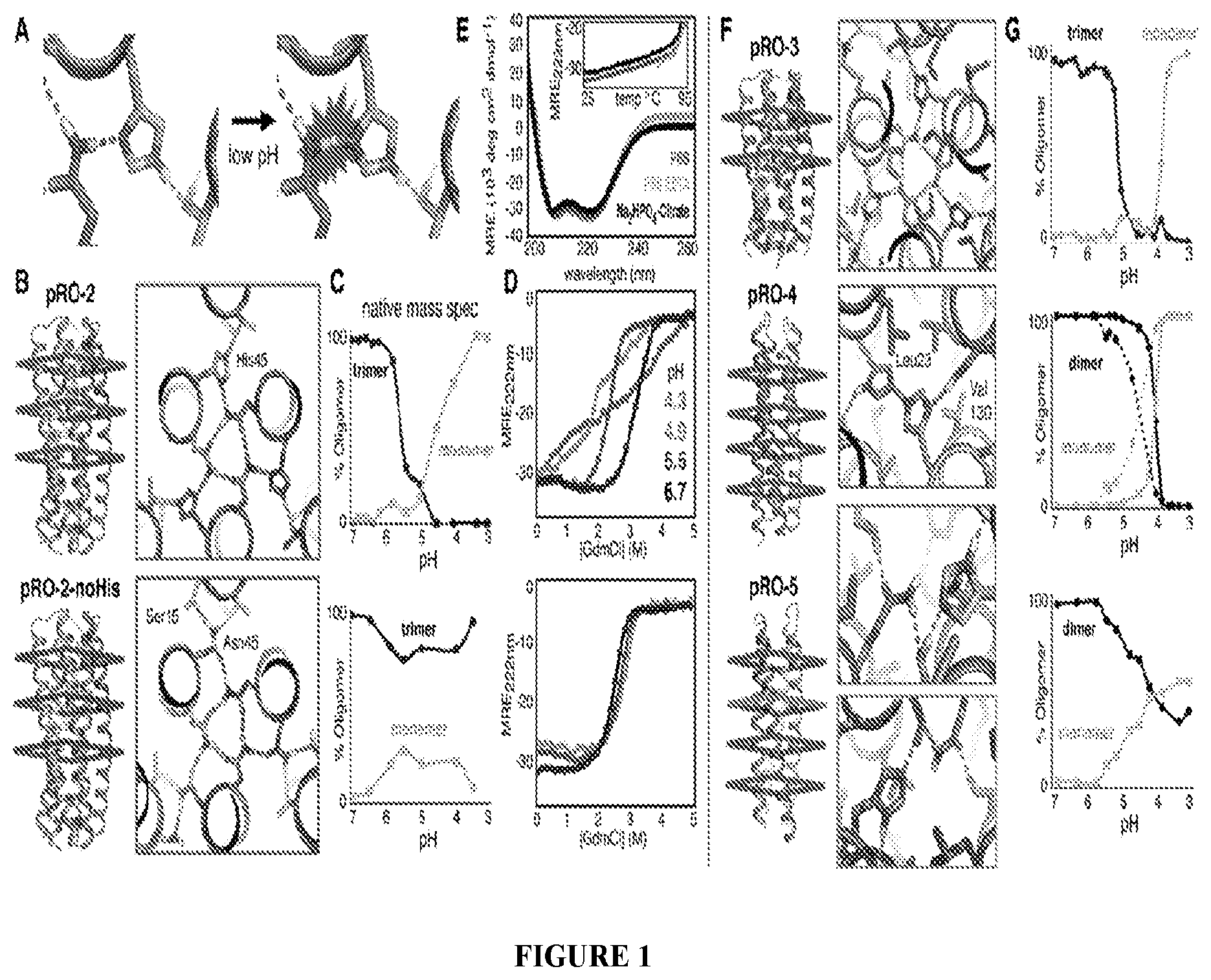
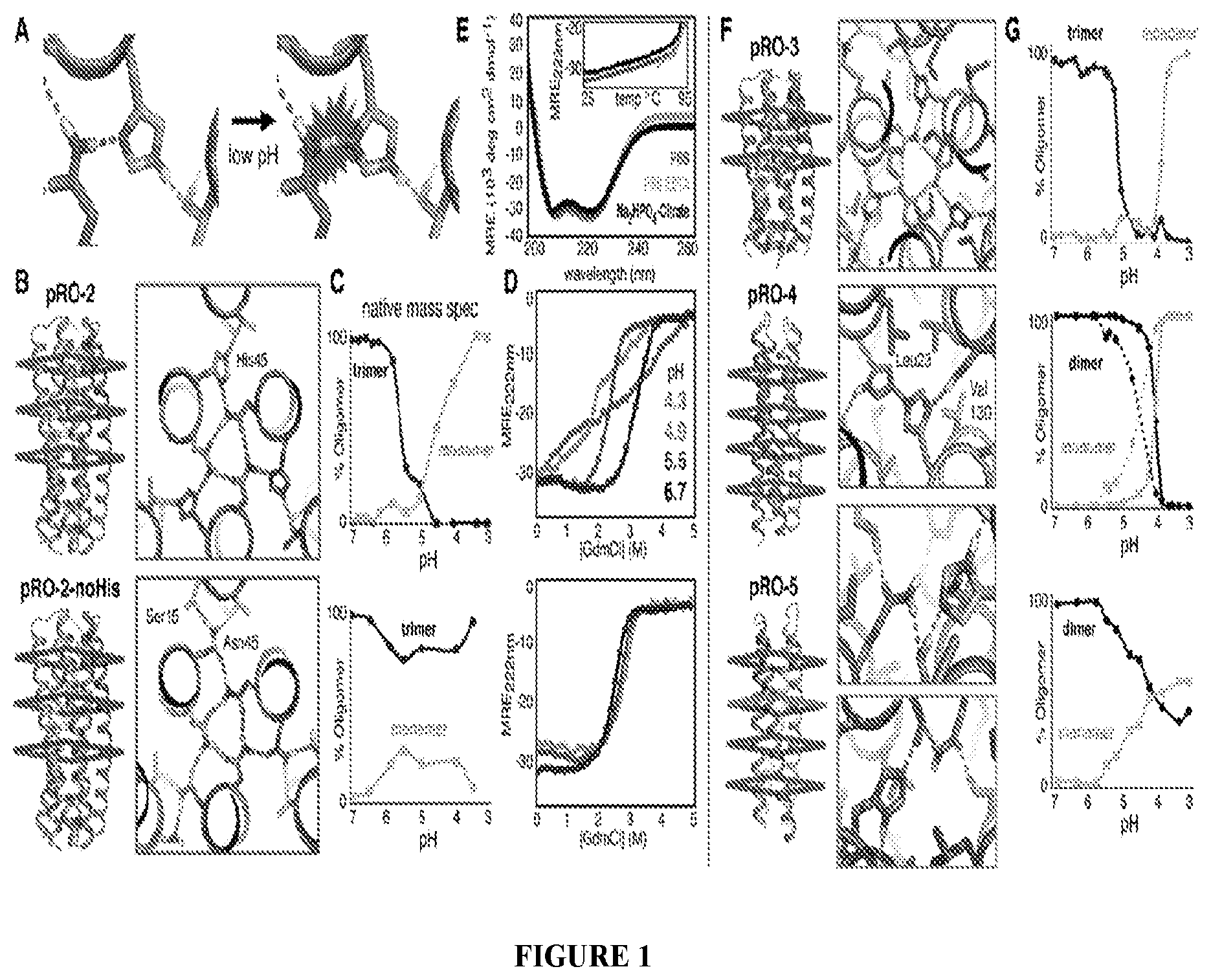
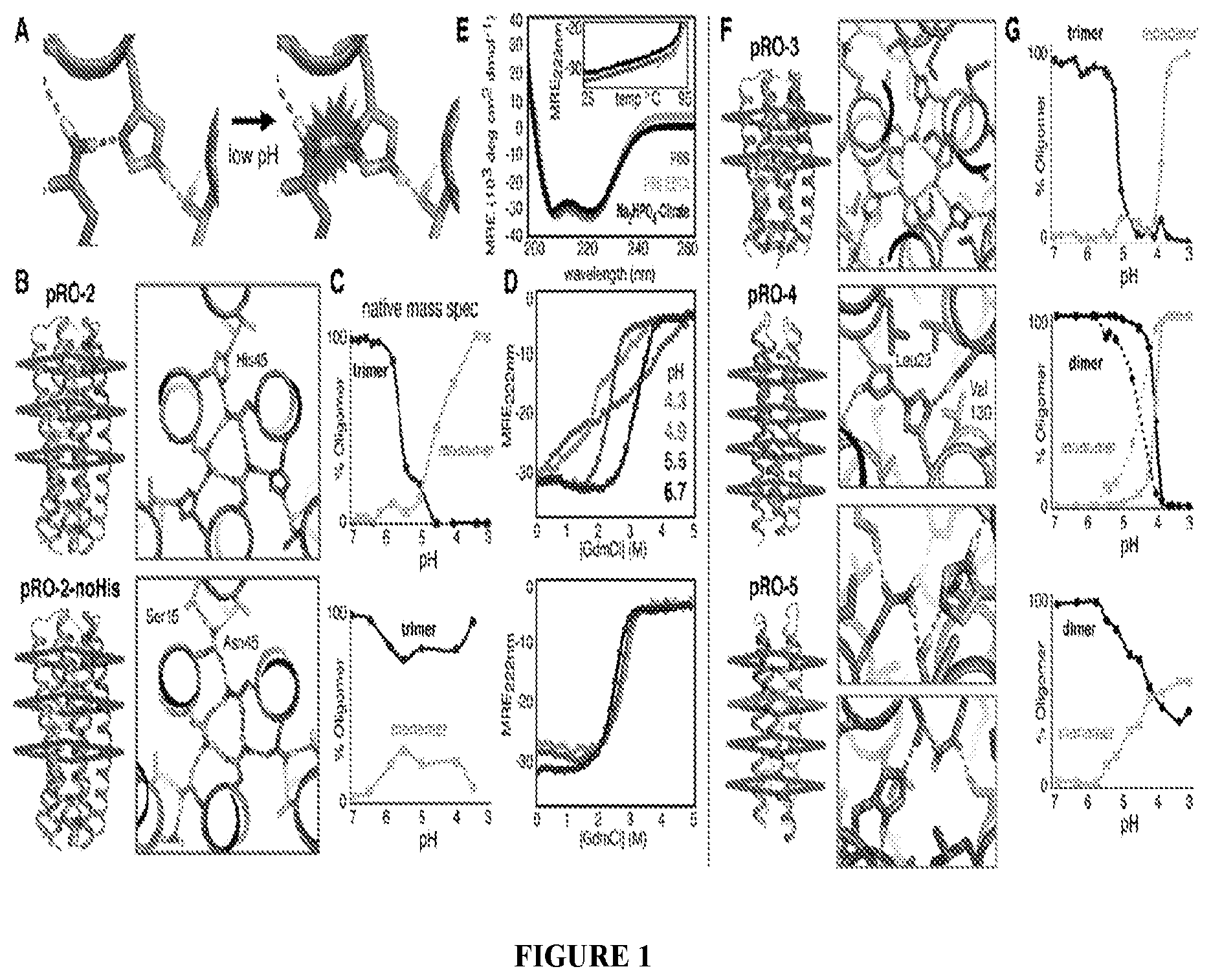
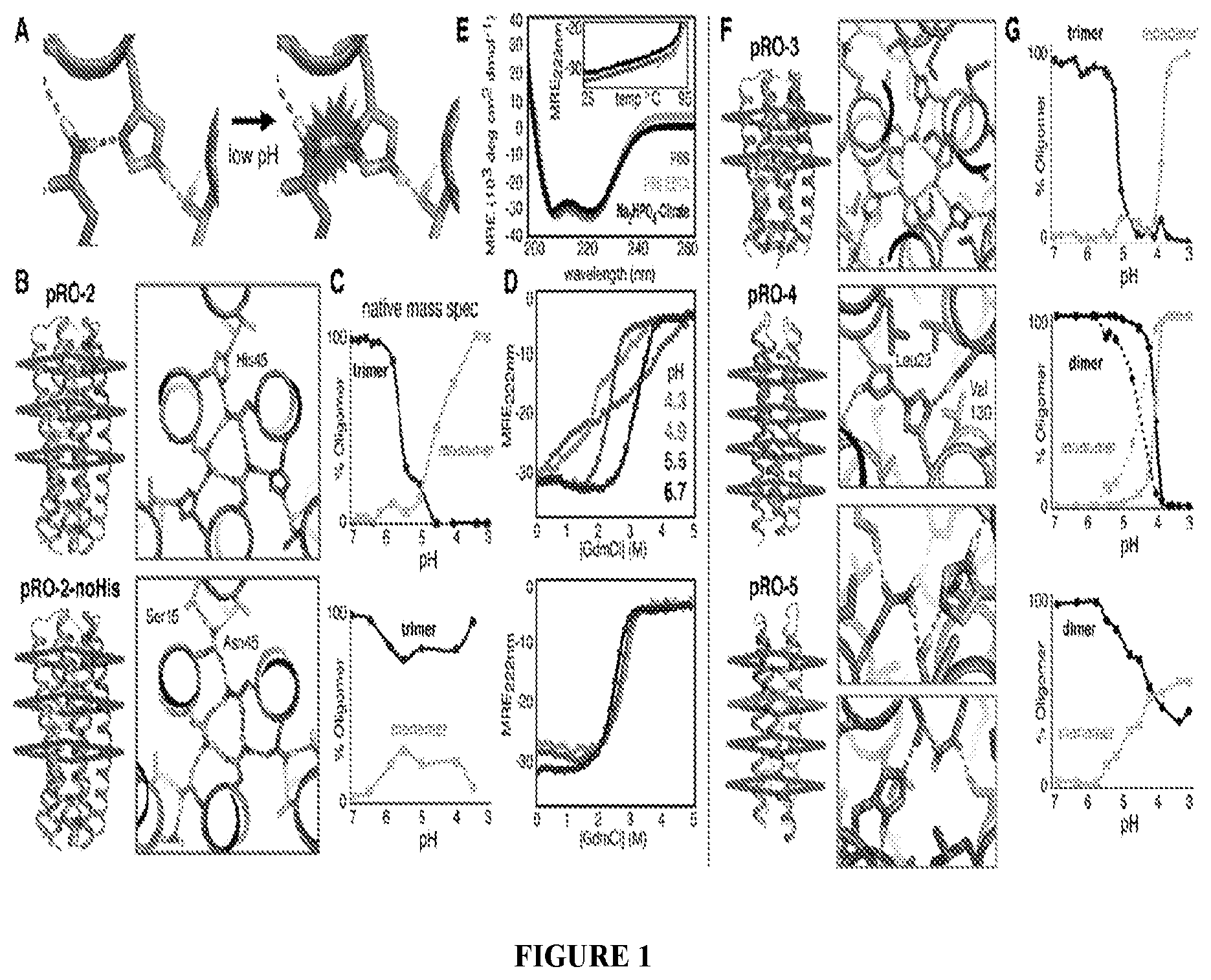
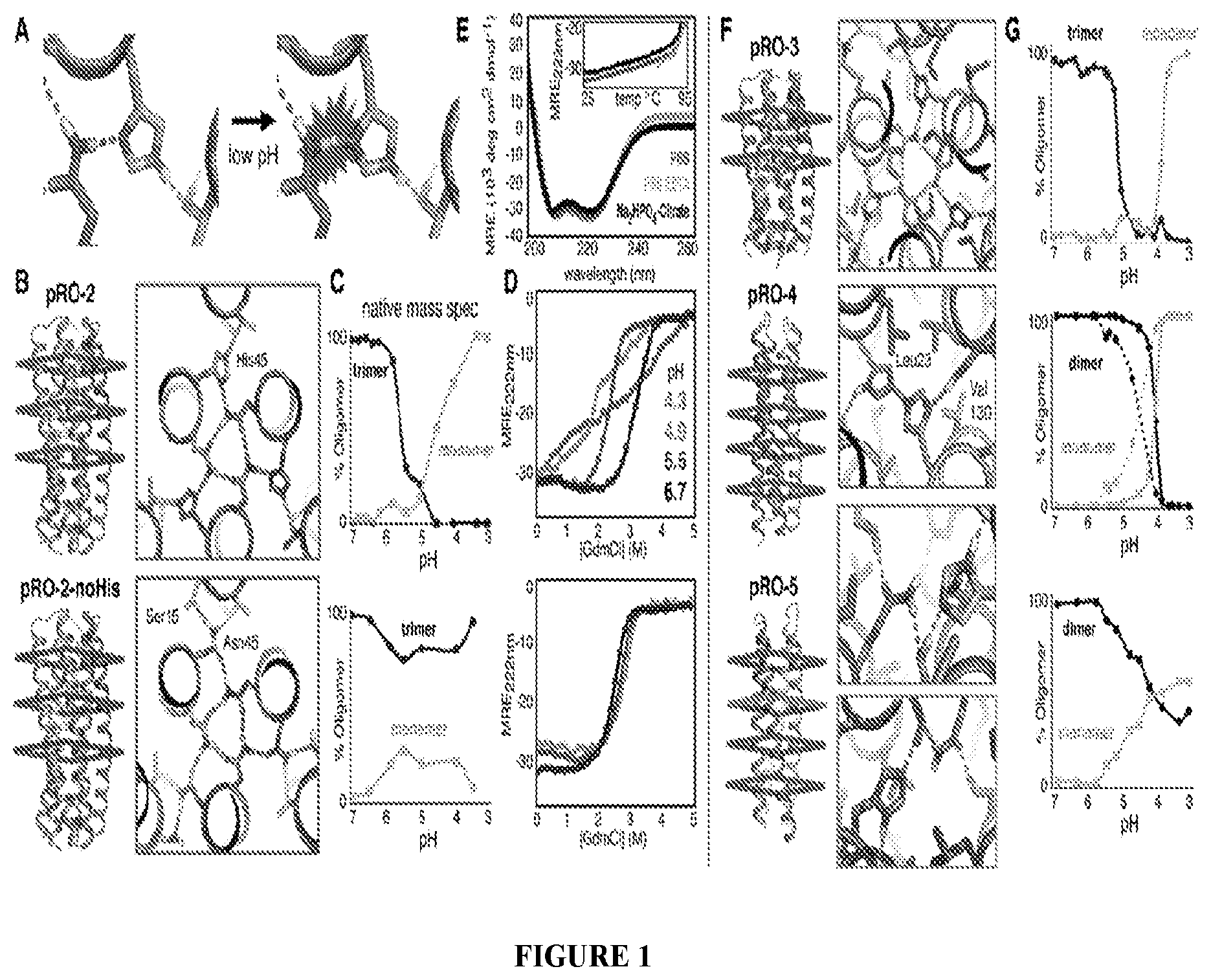
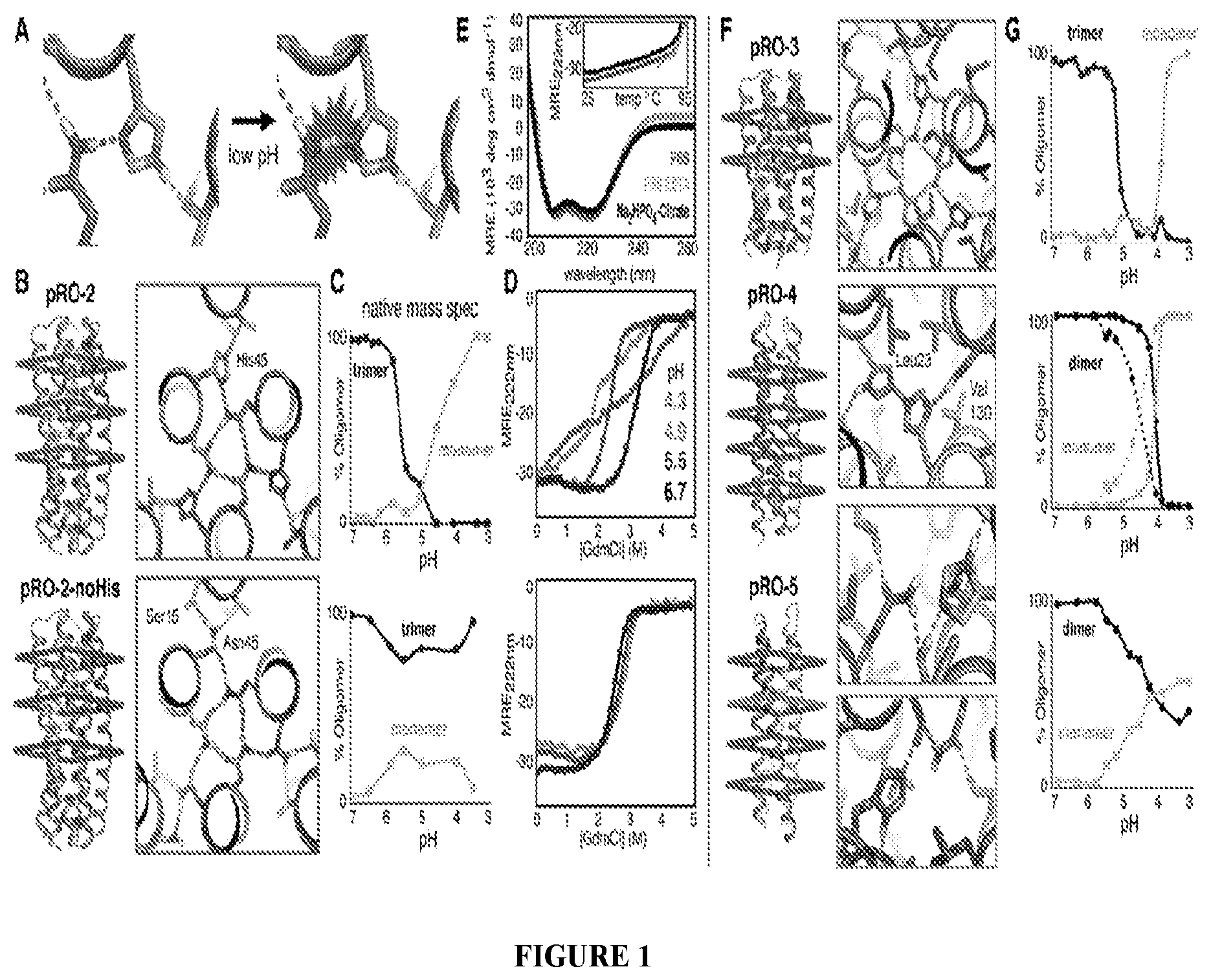
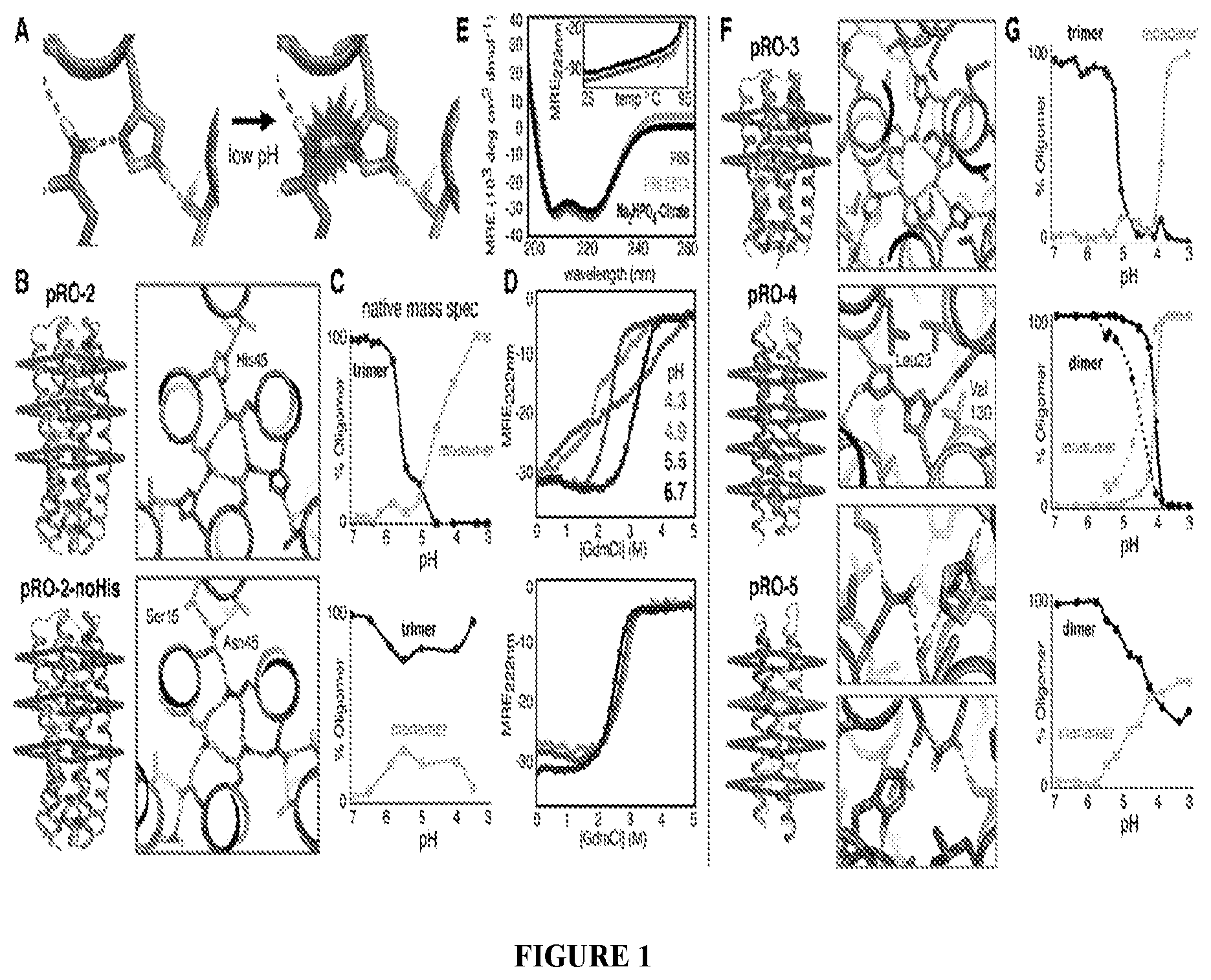
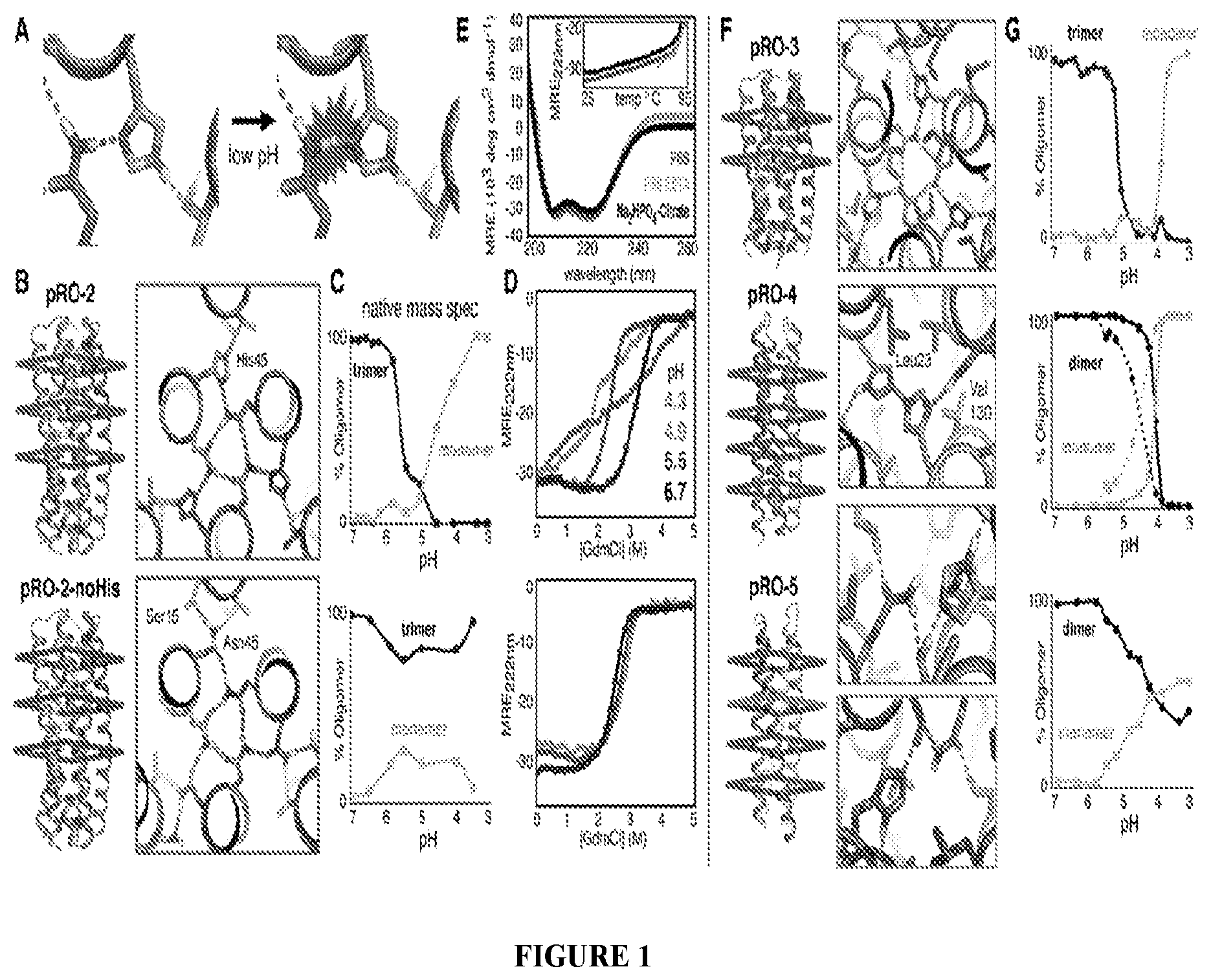
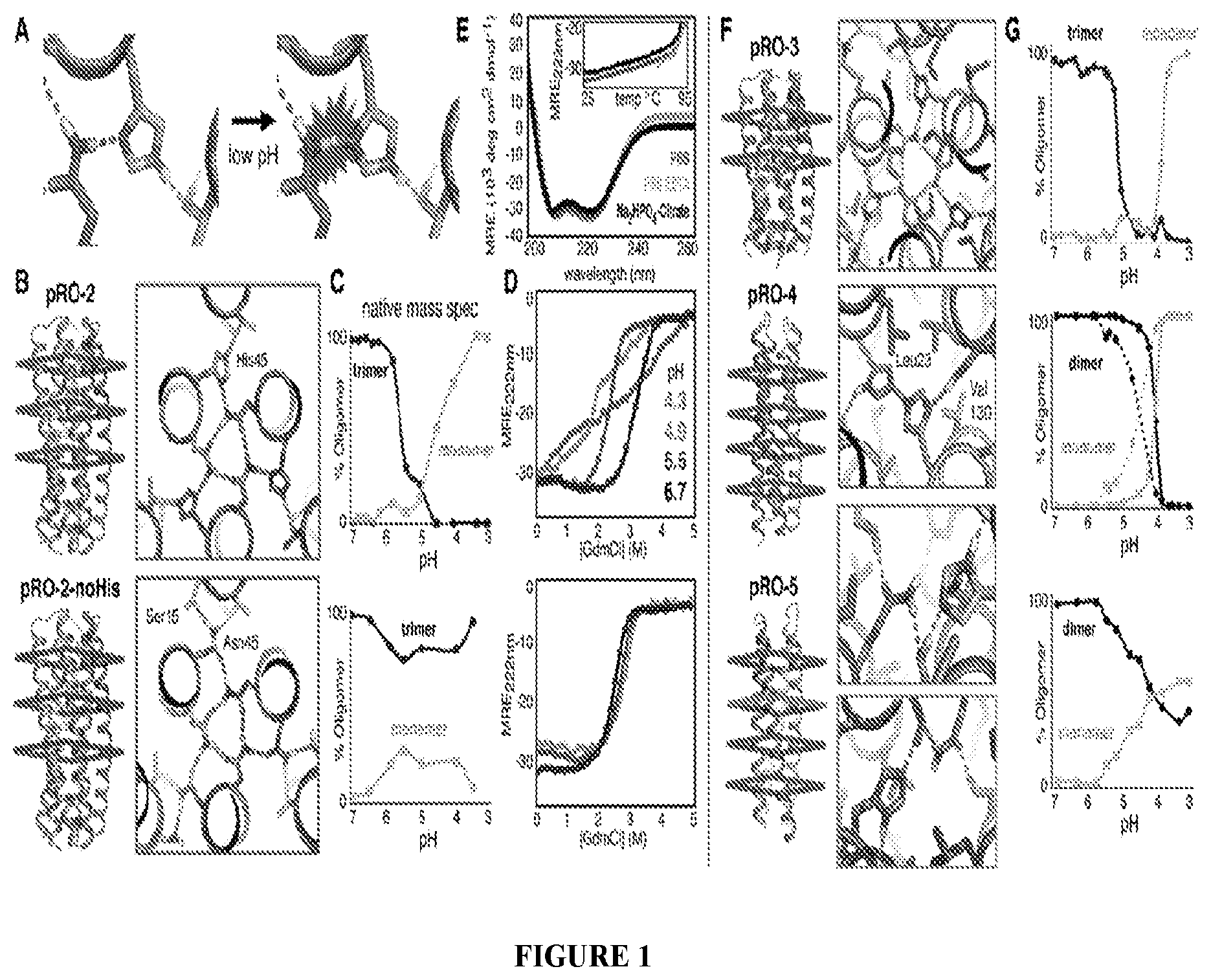
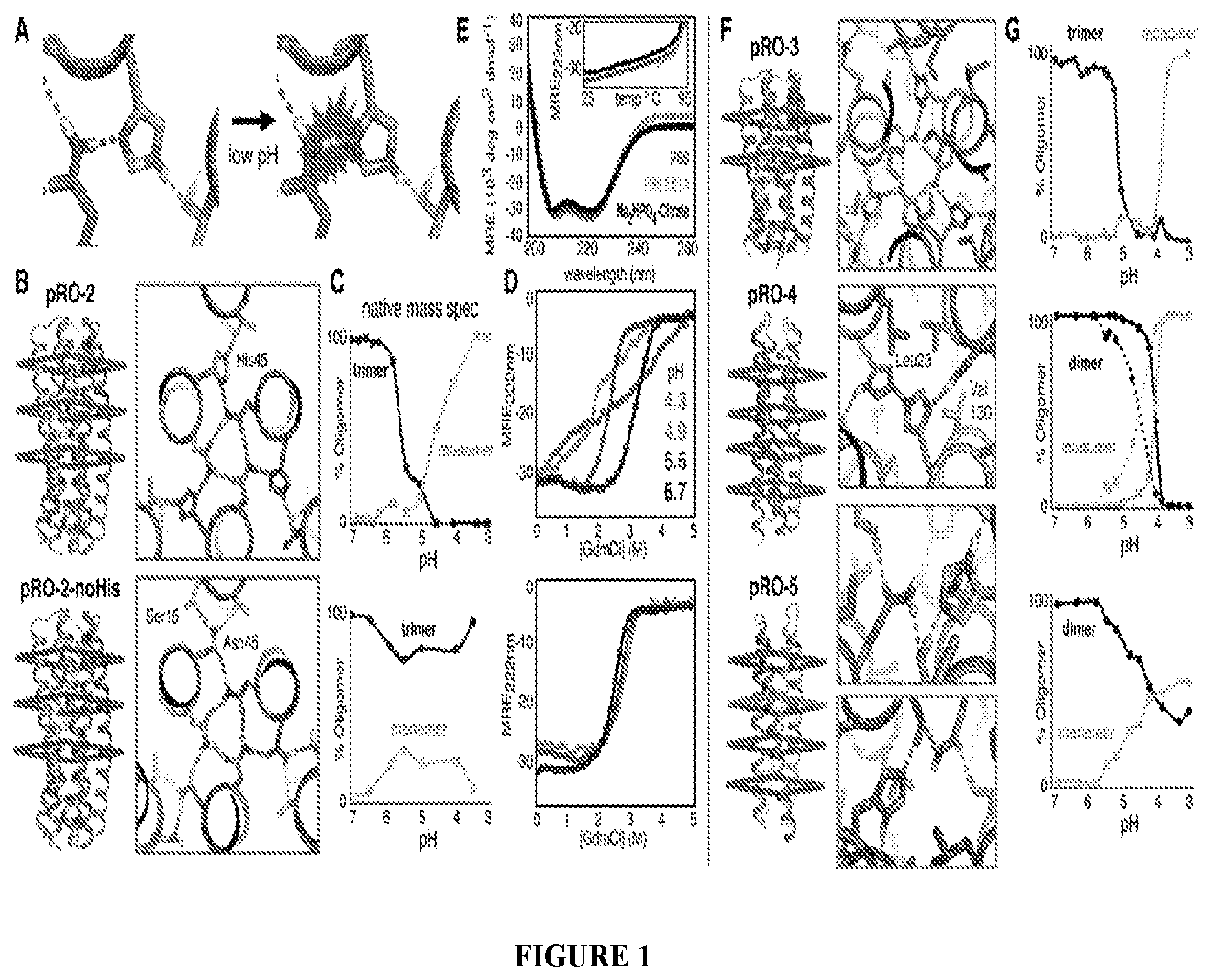
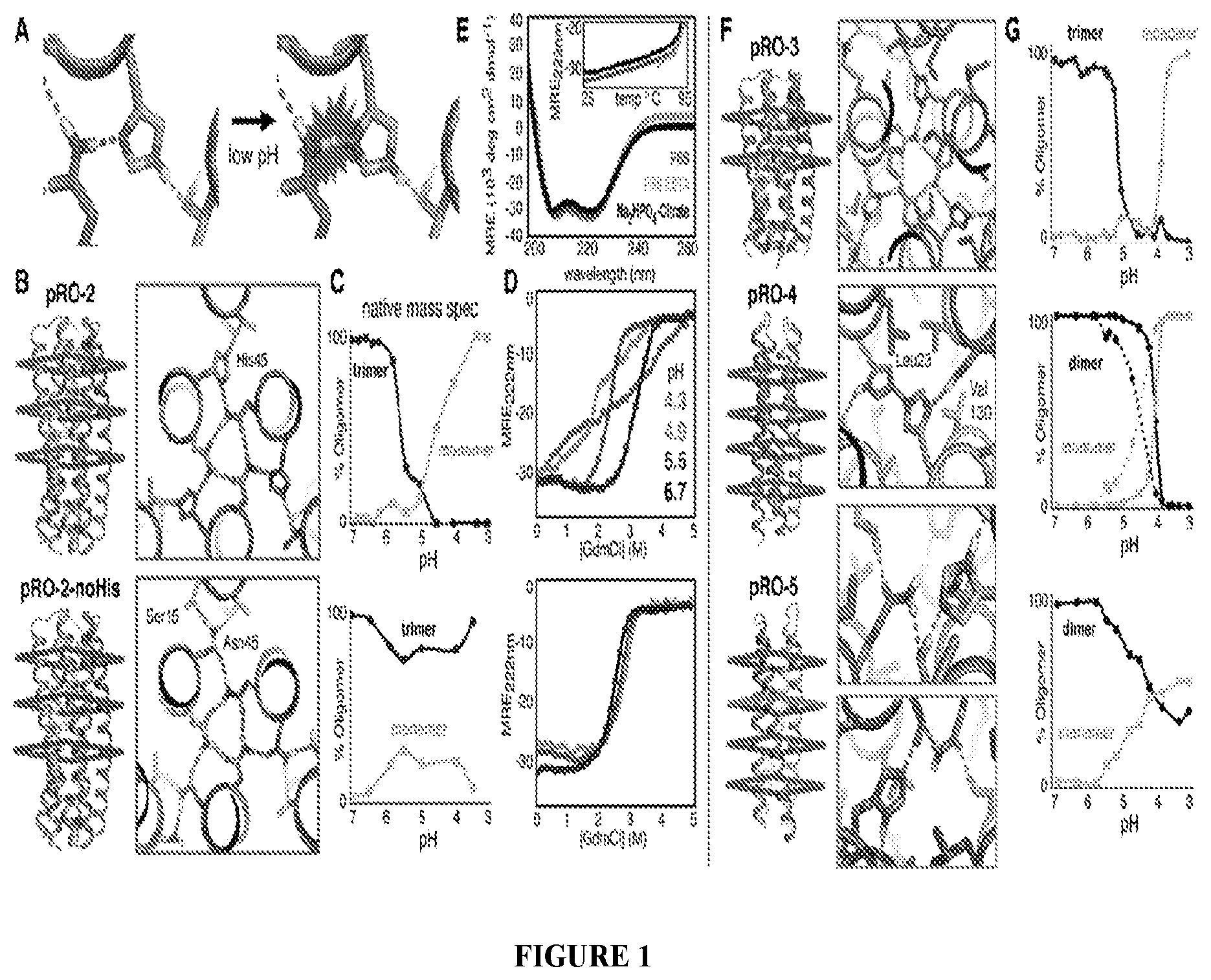
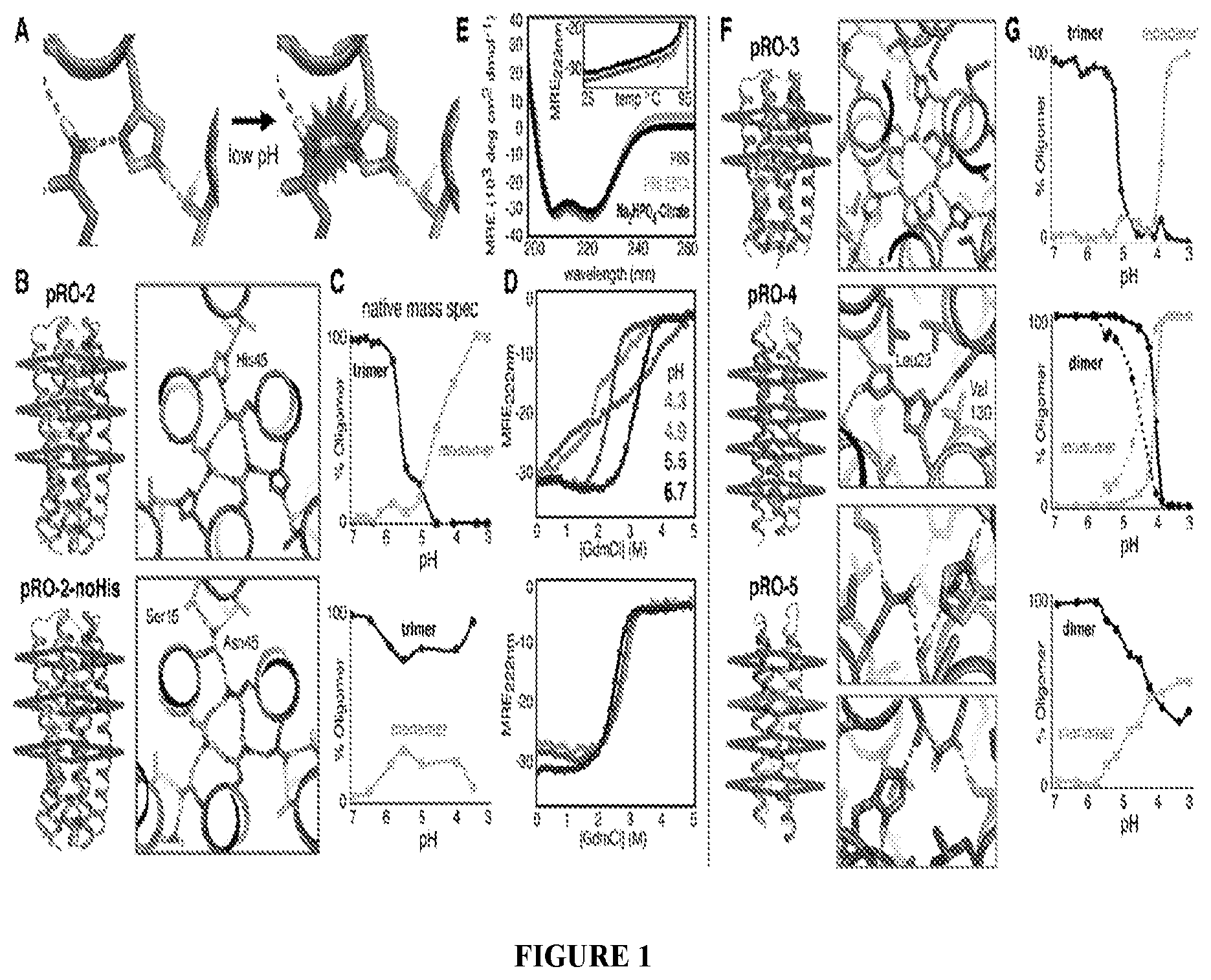
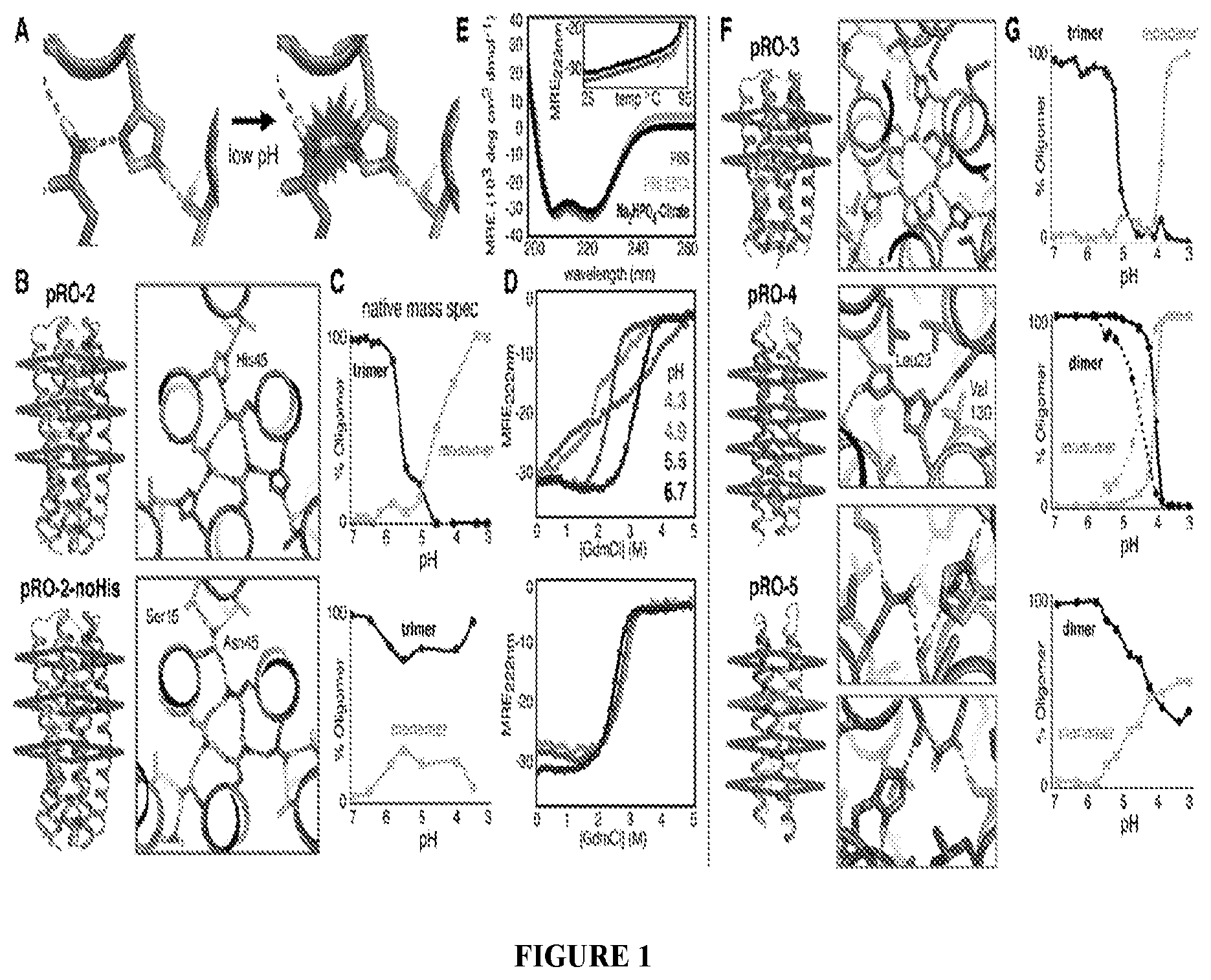
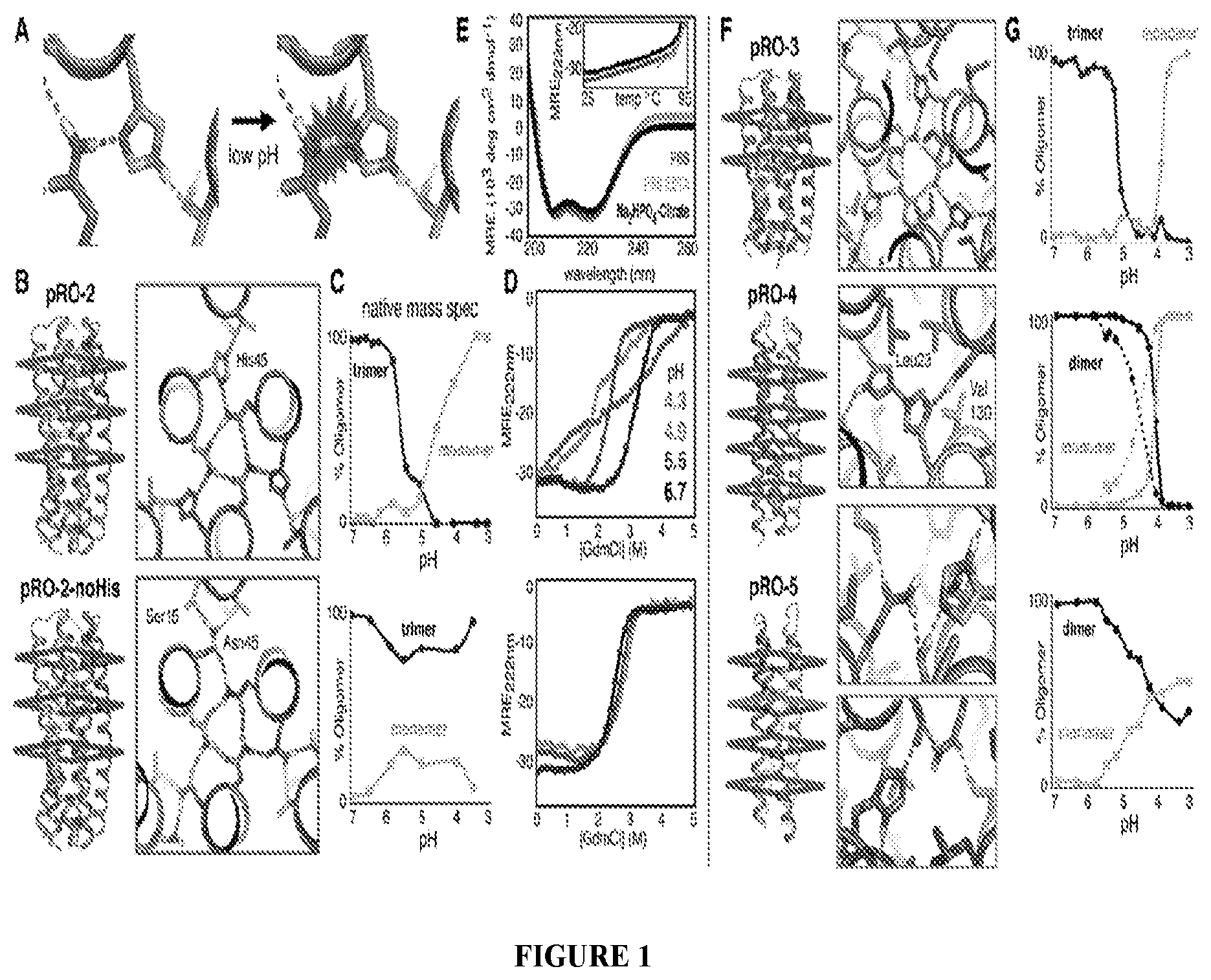
DE NOVO DESIGN OF TUNABLE PH-DRIVEN CONFORMATIONAL SWITCHES
This application claims priority to U.S. Provisional Application Ser. No. 62/835,651 filed Apr. 18, 2019, incorporated by reference herein in its entirety. This application contains a Sequence Listing submitted as an electronic text file named “18-1784-PCT_Sequence-isting_ST25.txt”, having a size in bytes of 205 kb, and created on Apr. 19, 2020. The information contained in this electronic file is hereby incorporated by reference in its entirety pursuant to 37 CFR § 1.52(e)(5). The ability of naturally occurring proteins to change conformation in response to environmental changes is critical to biological function. While there have been advances in the de novo design of extremely stable proteins, the design of conformational switches remains a major challenge. In one aspect, the disclosure provides non-naturally occurring polypeptides or polypeptide oligomers, comprising a buried hydrogen bond network that comprises at least 1, 2, 3, 4, 5, 6, 7, 8, or 9 pH sensitive amino acids located (i) at an intra-chain interface between different structural elements in one polypeptide, or (ii) at an inter-chain interface between structural elements present in different chains of a polypeptide oligomer, wherein the polypeptide or polypeptide oligomer is stable above a given pH, and wherein the polypeptide or polypeptide oligomer undergoes a conformational transition when subjected to a pH at or below the given pH. In one embodiment, the pH sensitive amino acids are selected from the group consisting of histidine, aspartate, and glutamate residues. In another embodiment, the different structural elements are selected from the group consisting of loops, beta sheets, alpha helices, or combinations thereof. In another embodiment, the at least one pH sensitive amino acid located is at an intra-chain interface between different structural elements in the polypeptide. In a further embodiment, the at least one pH sensitive amino acid located is at an inter-chain interface between structural elements present in different chains of the polypeptide oligomer. In one embodiment, the pH sensitive amino acids comprise histidine residues. In another embodiment, the disclosure provides non-naturally occurring pH-responsive polypeptides, comprising an oligomeric helical bundle comprising at least four alpha-helical subunits, wherein the oligomeric helical bundle comprises: one or more interfaces; and one or more histidine-containing layers that participate in buried hydrogen bond networks, wherein each histidine Nε and Nδ atoms are hydrogen-bonded across the one or more interfaces; wherein the polypeptide is stable above a given pH, and wherein oligomers (including but not limited to dimers or trimers) of the polypeptide undergo a conformational transition when subjected to a pH at or below the given pH. In a further embodiment, the disclosure provides non-naturally occurring pH-responsive polypeptides or polypeptide oligomers, comprising a helical bundle comprising at least four alpha-helical subunits, wherein the helical bundle comprises: one or more interfaces; and one or more histidine-containing layers that participate in buried hydrogen bond networks, wherein each histidine Nε and Nδ atoms are hydrogen-bonded across the one or more interfaces; wherein the polypeptide or polypeptide oligomer is stable above a given pH, and wherein the polypeptide or polypeptide oligomer undergoes a conformational transition when subjected to a pH at or below the given pH. In various embodiments, the polypeptides comprise a polypeptide of general formula 1, 2, 3, or 4, as disclosed herein. In one embodiment, the polypeptide or polypeptide oligomers of any embodiment or combination of embodiments further comprises a functional subunit. In some embodiments, the functional subunit comprises a detectable protein or functional fragment thereof, including but not limited to a fluorescent protein or functional fragment thereof. In another embodiment, the polypeptides of the disclosure comprise the amino acid sequence at least 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, or 100% identical to the polypeptide of any one of SEQ ID NOS:1-40, 45-46, 60-66, 69-76, and 81-86. In another aspect, the disclosure provides non-naturally occurring polypeptides, comprising the amino acid sequence at least 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, or 100% identical to the amino acid sequence of one of SEQ ID NOS:1-77 and 81-86. In another embodiment, the disclosure provides oligomeric polypeptides comprising two or more polypeptides of ay embodiment or combination of embodiments disclosed herein. In one embodiment, the oligomeric polypeptides comprise hetero-oligomers, including but not limited to a heterodimer of two different polypeptides. In another embodiment, the oligomeric polypeptides comprise homo-oligomers, including but not limited to a homotrimer. The disclosure further comprises nucleic acids encoding the polypeptide of any embodiment or combination of embodiments disclosed herein, recombinant expression vectors comprising the nucleic acids operatively linked to a control sequence, cells comprising the nucleic acid ad/or the recombinant expression vector of the disclosure, uses of the polypeptides or the oligomeric polypeptides for any methods as disclosed herein, and methods for designing the polypeptides or the oligomeric polypeptides disclosed herein. As used herein, the singular forms “a”, “an” and “the” include plural referents unless the context clearly dictates otherwise. As used herein, the amino acid residues are abbreviated as follows: alanine (Ala; A), asparagine (Asn; N), aspartic acid (Asp; D), arginine (Arg; R), cysteine (Cys; C), glutamic acid (Glu; E), glutamine (Gin; Q), glycine (Gly; G), histidine (His; H), isoleucine (Ole: I), leucine (Leu L), lysine (Lys; K), methionine (Met; M), phenylalanine (Phe; F), proline (Pro; P), serine (Ser; S), threonine (Thr; T), tryptophan (Trp; W), tyrosine (Tyr; Y), and valine (Val; V). All embodiments of any aspect of the disclosure can be used in combination, unless the context clearly dictates otherwise. Unless the context clearly requires otherwise, throughout the description and the claims, the words ‘comprise’, ‘comprising’, and the like are to be construed in an inclusive sense as opposed to an exclusive or exhaustive sense; that is to say, in the sense of “including, but not limited to”. Words using the singular or plural number also include the plural and singular number, respectively. Additionally, the words “herein,” “above,” and “below” and words of similar import, when used in this application, shall refer to this application as a whole and not to any particular portions of the application. The description of embodiments of the disclosure is not intended to be exhaustive or to limit the disclosure to the precise form disclosed. While the specific embodiments of, and examples for, the disclosure are described herein for illustrative purposes, various equivalent modifications are possible within the scope of the disclosure, as those skilled in the relevant art will recognize. In a first aspect, the disclosure provides non-naturally occurring polypeptides or polypeptide oligomers, comprising a buried hydrogen bond network that comprises at least one pH sensitive amino acid located (i) at an intra-chain interface between different structural elements in one polypeptide, or (ii) at an inter-chain interface between structural elements present in different chains of a polypeptide oligomer, wherein the polypeptide or polypeptide oligomer is stable above a given pH, and wherein the polypeptide or polypeptide oligomer undergoes a conformational transition when subjected to a pH at or below the given pH. As disclosed in the examples, the inventors present a general strategy to design pH-polypeptides or polypeptide oligomers by precisely pre-organizing histidine residues in buried hydrogen bond networks that span across the polypeptide interface or oligomeric interface. The pH range at which disassembly occurs, as well as the cooperativity of the transition, can be programmed by balancing the number of histidine-containing networks and the strength of the surrounding hydrophobic interactions. In non-limiting embodiments, the polypeptides or polypeptide oligomers (including but not limited to homotrimers and heterodimers) are stable above pH 6.5, but undergo cooperative, large-scale conformational transitions when the pH is lowered and electrostatic and steric repulsion builds up as the network histidines involved in the buried hydrogen bond network become protonated. The repeating geometric cross-sections allow hydrogen bond networks to be added or subtracted in a modular fashion. In one embodiment, the pH sensitive amino acids are selected from the group consisting of histidine, aspartate, and glutamate residues. In a specific embodiment, the pH sensitive amino acids comprise histidine residues. In other embodiments, the buried hydrogen bond network comprises at least 2, 3, 4, 5, 6, or more pH sensitive amino acids. The polypeptides or polypeptide oligomers may include any suitable “structural element”. In non-limiting embodiments, the different structural elements are selected from the group consisting of loops, beta sheets, alpha helices, or combinations thereof. In a specific embodiment the structural elements comprise alpha helices. In another embodiment, the polypeptides or polypeptide oligomers may include at leas 2, 3, 4, 5, 6, 7, 8, 9, or more structural elements. The different structural elements in a given polypeptide or polypeptide oligomer may comprise different structural elements linked via an amino acid linker, or different structural elements present on separate polypeptides present in a polypeptide oligomer. In one embodiment, the at least one pH sensitive amino acid located is at an intra-chain interface between different structural elements in the polypeptide. In another embodiment, the at least one pH sensitive amino acid located is at an inter-chain interface between structural elements present in different chains of the polypeptide oligomer. In one embodiment, the buried hydrogen-bond network comprises one or more histidine-containing layers, wherein each histidine Nε and Nδ atoms are hydrogen-bonded across the one or more interfaces. As used herein, “layers” refer to an interaction between different structural elements in the polypeptide or polypeptide oligomer. The interaction(s) may comprise hydrogen-bonding between different structural elements, hydrophobic interactions between different structural elements, or combinations thereof. In some embodiments, the polypeptide or polypeptide oligomer comprises a polypeptide monomer, as described herein (i.e.: the buried hydrogen bond network comprises at least one pH sensitive amino acid is located at an intra-chain interface between different structural elements in one polypeptide). In another embodiment, the polypeptide or polypeptide oligomer comprises a homo-oligomer, including but not limited to homo-trimers, or a hetero-oligomer, including but not limited to hetero-dimers as described herein (i.e.: the buried hydrogen bond network comprises at least one pH sensitive amino acid located at an inter-chain interface between structural elements present in different chains of the polypeptide oligomer). In another embodiment, the disclosure provides non-naturally occurring pH-responsive polypeptides, comprising an oligomeric helical bundle comprising at least four alpha-helical subunits, wherein the oligomeric helical bundle comprises one or more interfaces; and one or more histidine-containing layers that participate in buried hydrogen bond networks, wherein each histidine Nε and Nδ atoms are hydrogen-bonded across the one or more interfaces; wherein the polypeptide is stable above a given pH, and wherein oligomers (including but not limited to dimers or trimers) of the polypeptide undergo a conformational transition when subjected to a pH at or below the given pH. As will be understood by those of skill in the art, the helical bundle will include the alpha-helical subunits and a single hairpin loop per subunit; as used herein, a “helical bundle subunit” includes the alpha-helix and the hairpin loop. In one embodiment, each alpha helix is connected to the next helix along the primary amino acid sequence via an amino acid linker. The linker may be any suitable amino acid length and composition. In various embodiments, the amino acid linker is between 4-8, 4-7, 5-8, 5-7, or 5-6 amino acids in length. Each inner helix can connect to an outer helix through a short designed loop to produce helix-turn-helix monomer subunits. The short designed loop may be any polypeptide sequence or domain that permits formation of the alpha-helical hairpin, including any functional domain insertions of interest. In one embodiment, the polypeptide comprises two or more (i.e.: 2, 3, 4, 5, 6, or more) histidine-containing layers. In one embodiment, the given pH is between about pH 4.5 to about pH 6.5. As described below, modification of hydrophobic layers shift the “given pH” transition point lower. As the number of hydrophobic layers increases, therefore the number of hydrophobic layers modulates the pH-responsiveness. Thus, the number of hydrophobic layers can be modified to tune pH responsiveness as deemed appropriate for an intended use. In one embodiment, polypeptide comprises a polypeptide of formula I: X1 and X17 are independently absent or comprise peptides; X2, X4, X6, X8, X10, X12, X14, and X16 are each 1-2 amino acids that may be comprised of either hydrophobic residues or polar residues, forming a helical secondary structure, wherein at least 1, 2, 3, 4, 5, 6, 7, or all 8 of X2, X4, X6, X8, X10, X12, X14, and X16 include a histidine residue; X3, X5, X7, X11, X13, and X15 Se 5-6 residue variable amino acid linkers forming a helical secondary structure; and X9 comprises a loop, including but not limited to a hairpin loop, of variable amino acids. The polypeptides are thus composed of a helix-loop-helix secondary structure and hairpin-shaped tertiary structure. In this embodiment, X2, X4, X6, and X8, X10, X12, X14, and X16 are always buried in the oligomeric interface upon homo-trimerization of the polypeptide. Since a canonical alpha-helix has ˜3.6 residues per 360 degree turn, the residues in X2, X4, X6, and X8, as well as X10, X12, X14, and X16 are defined every two complete turns of the alpha-helix (i.e. since they are each 1-2 amino acids in length and domains X3, X5, X7, X11, X13, and X15 segments contain the 5-6 intervening residues. In this embodiment, the buried hydrogen bond network comprises at least one pH sensitive His residue. The polypeptides of this embodiment form homotrimers as described in the examples that follow. In this embodiment, domains X8 and X10, X6 and X12, X4 and X14, and X2 and X16 segment pairs interact in the homo-trimer to form part of a single “layer” (i.e.: the interaction between domains X8 and X10 constitutes one layer; the interaction between domains X6 and X12 constitutes a second layer, the interaction between domains X4 and X14 constitutes a third layer, and the interaction between domains X2 and X16 constitutes a fourth layer). The interactions in each layer may comprise purely hydrophobic interactions, a mix of hydrophobic and polar interactions, and/or a mix of hydrophobic and His interactions. The interactions may occur at an inter-chain interface between domains present in different subunits of the polypeptide oligomer, at an intra-chain interface between different domains in one polypeptide subunit, or both. In one embodiment, the interactions primarily may occur at an inter-chain interface between domains present in different subunits of the polypeptide oligomer. As will be understood by those of skill in the art based on the teachings herein, other embodiments are possible and described below. For example, other polypeptides or polypeptide oligomers (including homo-trimers) may comprise 1, 2, 3 or 4 such layers. Increased numbers of such layers are also possible. In another embodiment, the polypeptide comprises a polypeptide of formula 2: X6-X8 form a first helical secondary structure; X10-X12 form a second helical structure; X9 comprises a loop of variable amino acid length and sequence; and wherein at least 1, 2, 3, 4, 5, or all 6 of X6, X7, X8, X10, X11, and X12 include a pH sensitive amino acid residue; wherein the polypeptide or an oligomer comprising the polypeptide undergoes a conformational transition when subjected to a pH at or below a given pH. In a further embodiment, the polypeptide comprises a polypeptide of formula 3: X4-X8 form a first helical secondary structure; X10-X14 form a second helical structure; X9 comprises a loop of variable amino acid length and sequence; and wherein at least 1, 2, 3, 4, 5, 6, 7, 8, 9, or all 10 of X4, X5, X6, X7, X8, X10, X11, X12, X13, and X14 include a pH sensitive amino acid residue; wherein the polypeptide or an oligomer comprising the polypeptide undergoes a conformational transition when subjected to a pH at or below a given pH. In another embodiment, the polypeptide comprises a polypeptide of formula 4: X2-X8 form a first helical secondary structure; X10-X16 form a second helical structure; X9 comprises a loop of variable amino acid length and sequence and wherein at least 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, or all 14 of X2, X3, X4, X5, X6, X7, X8, X10, X11, X12, X13, X14, X15, and X16 include a pH sensitive amino acid residue; wherein the polypeptide or an oligomer comprising the polypeptide undergoes a conformational transition when subjected to a pH at or below a given pH. In each of these embodiments, the polypeptide, or polypeptide oligomers comprising the polypeptide comprise a buried hydrogen bond network that comprises at least one pH sensitive amino acid located (i) at an intra-chain interface between different domains in one polypeptide, or (ii) at an inter-chain interface between domains present in different chains of a polypeptide oligomer, wherein the polypeptide or polypeptide oligomer is stable above a given pH, and wherein the polypeptide or polypeptide oligomer undergoes a conformational transition when subjected to a pH at or below the given pH. In one embodiment, the pH sensitive amino acids are selected from the group consisting of histidine, aspartate, and glutamate residues. In a specific embodiment, the pH sensitive amino acids comprise histidine residues. In other embodiments, the buried hydrogen bond network comprises at least 2, 3, 4, 5, 6, or more pH sensitive amino acids. The various X domains in these embodiments may comprise any length or content of amino acids so long as the recited limitations are met. In one embodiment of any of these embodiments, 1, 2, 3, 4, 5, 6, 7, or all 8 of X2, X4, X6, X8, X10, X12, X14, and X16 (when present) are 1-2 amino acids that may be comprised of hydrophobic residues, polar residues or both, wherein at least 1, 2, 3, 4, 5, 6, 7, or all 8 of X2, X4, X6, X8, X10, X12, X14, and X16 (when present) include a pH sensitive amino acid. In another embodiment that can be combined with any of these embodiments, 1, 2, 3, 4, 5, or all 6 of X3, X5, X7, X11, X13, and X15 (when present) are 5-6 residue variable amino acid linkers. In a further embodiment of any of these embodiments, X9 nay comprise a hairpin loop, or may comprise a flexible linker including but not limited to a flexible GS-based linker. In a further embodiment of any of these embodiments, additional amino acid residues or functional domains may be present, such as at the N- or C-terminus, as deemed appropriate for an intended use. As used herein, amino acid residues in a polar layer could be any of the following: C, D, E, G, K, N, Q, R, S, T, Y, W, and H. Amino acid residues in a hydrophobic layer could be any of the following: A, F, G, I, L, M, P, V, W and norleucine. Hydrophobic layers shift the “given pH” transition point lower as the number of hydrophobic layers increases, therefore the number of hydrophobic layers does modulate the pH-responsiveness. Thus, the number of hydrophobic layers can be modified to tune pH responsiveness as deemed appropriate for an intended use. In one embodiment, 1, 2, 3, 4, 5, 6, or 7 of X2, X4, X6, X8, X10, X12, X14, and X16 are comprised of hydrophobic residues, as deemed suitable for an intended use. For example, to shift the “given pH” lower, the number of hydrophobic domains is increased and the number of polar domains is decreased; to shift the “given pH” higher, the number of hydrophobic domains is decreased and the number of polar domains is increased. In another embodiment X9 is at least 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25 or more amino acids in length. In a further embodiment, each of X1 and X17, when present, are the same length. In one embodiment, one or more of X1, X9 and X17 comprise a functional subunit, or the polypeptide further comprises a functional domain at the N-terminus or C-terminus. A “functional subunit” is any domain that can be add functionality to the polypeptide. Any functional domain may be used as suitable for an intended purpose. In one embodiment, the functional subunit comprises a detectable protein or functional fragment thereof, including but not limited to a fluorescent protein or functional fragment thereof. For example, a functional subunit comprising a fluorescent protein or functional fragment thereof permits coupling of the conformational change due to protonation of the buried histidines in the hydrogen bond networks at the interface of the helical bundle to conformational changes in the chromophore environment of the fused fluorescent protein. This provides a fluorescent readout of the conformation change. As will be understood by those of skill in the art, other functional subunits could be used in a similar manner to link the pH-based conformational change with a readout based on the function of the functional subunit. In another embodiment, the polypeptide comprises the amino acid sequence at least 25%, 30%, 35%, 40%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, or 100% identical to a polypeptide selected from the group consisting of SEQ ID NOs: 1-40, 45-46, 60-66, 69-76 and 81-86. The polypeptides of SEQ ID NOS:1-26 and 33-36 all form homotrimers and the polypeptides of SEQ ID NOS:27-32 and 81-86 form heterodimers. In these embodiments, the buried hydrogen bond network comprises at least one pH sensitive amino acid located at an inter-chain interface between structural elements present in different chains of the polypeptide oligomer. The following embodiments of the polypeptides of the disclosure (SEQ ID NOS: 37-40, 45-46, 60-66, and 69-76) are single chain monomers, and the buried hydrogen bond network comprises at least one pH sensitive amino acid is located at an intra-chain interface between different structural elements in the polypeptide. The underlined regions of the following sequences are not part of the design but hexahistidine tag and thrombin or TEV cleavage site for purification (i.e.: the underlined regions are optional). In many of these sequences the monomeric subunits of the homotrimer are fused by linkers/loops and function domains into a single polypeptide sequence pRO2.3, single-chain, with GS linkers on all the loops, asymmetrized, and a TEV site opposite to the termini direction. This allows the pH responsive trimer to be fused at its n-terminus to other proteins, such as a nanoparticle, and confer membrane disruption. Based on the liposome assay described below, the kinetics of dissociation of linked-pH trimer is slower but achieves the same membrane disruption levels as measured by dye leakage over time (on the order of minutes). This performs as well as pRO2.3 as measured by the liposome disruption assay in the context of a nanoparticle (i.e. fused at its n-terminus to a nanoparticle). The next polypeptide is similar to pRO2.3, with the TEV site parallel to the termini such that a monomer is released upon cleavage. This monomer is modified to have aromatic residues (phenylalanine and tryptophan) on the n-terminal helix to enhance membrane disruption. This performs slightly (5-10%) better than the pRO2.3 homotrimer in the liposome disruption assay. Similar to pRO2.3, with Thrombin cleavage sites on each loop opposite to the termini. Also has the destabilizing I56V mutation to shift the pH disassembly to a higher pH. This performs close as well as pRO2.3 as measured by the liposome disruption assay in the context of a nanoparticle (i.e., fused at its n-terminus to a nanoparticle) but with slower kinetics. Same as above, but with the third asparagine network mutated such that it is all hydrophobics to destabilize the linked-trimer and increase hydrophobic content for better membrane interaction. This performs 5-10% better than pRO2.3 as measured by the liposome disruption assay in the context of a nanoparticle (i.e., fused at its n-terminus to a nanoparticle) but with slower kinetics. Additional polypeptides of the disclosure and inactive controls (i.e.: not pH responsive) are shown below. Underlined residues and/or residues in parentheses are optional. In one embodiment, the polypeptide includes changes to the highlighted residues (i.e., residues involved in hydrogen-bind networks) in Table 1, 2, or 3 of the polypeptides of 1-36 only to other polar amino acids. In another embodiment, the polypeptide includes no changes to the highlighted residues of the polypeptides of SEQ ID NOs:1-36. In a further embodiment, all amino acid substitutions relative to the amino acid sequence of SEQ ID NOs: 1-40, 45-46, 60-66, 69-76, and 81-86 are conservative amino acid substitutions. In various embodiments, a given amino acid can be replaced by a residue having similar physiochemical characteristics, e.g., substituting one aliphatic residue for another (such as Ile, Val, Leu, or Ala for one another), or substitution of one polar residue for another (such as between Lys and Arg; Glu and Asp; or Gln and Asn). Other such conservative substitutions, e.g., substitutions of entire regions having similar hydrophobicity characteristics, are known. Polypeptides comprising conservative amino acid substitutions can be tested in any one of the assays described herein to confirm that the desired activity is retained. Amino acids can be grouped according to similarities in the properties of their side chains (in A. L. Lehninger, in Biochemistry, second ed., pp. 73-75, Worth Publishers, New York (1975)): (1) non-polar: Ala (A), Val (V), Leu (L), Ile (I), Pro (P), Phe (F), Trp (W), Met (M); (2) uncharged polar: Gly (G), Ser (S), Thr (T), Cys (C), Tyr (Y), Asn (N), Gln (Q); (3) acidic: Asp (D), Glu (E); (4) basic: Lys (K), Arg (R), His (H). Alternatively, naturally occurring residues can be divided into groups based on common sidechain properties: (1) hydrophobic: Norleucine, Met, Ala, Val, Leo, Ile; (2) neutral hydrophilic: Cys, Ser, Thr, Asn, Gln; (3) acidic: Asp, Glu; (4) basic: His, Lys, Arg; (5) residues that influence chain orientation: Gly, Pro; (6) aromatic: Trp, Tyr, Phe. Non-conservative substitutions will entail exchanging a member of one of these classes for another class. Particular conservative substitutions include, for example; Ala into Gly or into Ser; Arg into Lys; Asn into Gln or into H is; Asp into Glu; Cys into Ser; Gln into Asn; Glu into Asp; Gly into Ala or into Pro; His into Asn or into G; Ile into Leu or into Val; Leu into Ile or into Val; Lys into Arg, into Gln or into Glu; Met into Leu, into Tyr or into Ile; Phe into Met, into Lea or into Tyr, Ser into Thr; Thr into Ser; Trp into Tyr; Tyr into Trp; and/or Phe into Val, into Ile or into Leu. In another aspect, the disclosure provides non-naturally occurring polypeptide, comprising the amino acid sequence at least 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, or 100% identical to the amino acid sequence selected from the group consisting of SEQ ID NOS:1-77 and 81-86. In one embodiment, the polypeptide includes changes to the highlighted residues in Table 1, 2, or 3 of the amino acid sequence selected from the group consisting of SEQ ID NOS:1-36 only to other polar amino acids. In a further embodiment, the polypeptide includes no changes to the highlighted residues in Table 1, 2, or 3 of the amino acid sequence selected from the group consisting of SEQ ID NOS:1-36. In a further embodiment, all amino acid substitutions relative to the amino acid sequence selected from the group consisting of SEQ ID NOS:1-77 and 81-86 are conservative amino acid substitutions. In another embodiment, the disclosure comprises oligomeric polypeptide comprising two or more polypeptides of any embodiment or combination of embodiments disclosed herein. In one embodiment, the oligomeric polypeptides comprise a hetero-oligomer. The hetero-oligomer may be any suitable hetero-oligomer, including but not limited to heterodimers. Exemplary heterodimers provided herein include heterodimers between polypeptides comprises the amino acid sequence at least 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, or 100% identical to: (a) the amino acid sequence of SEQ ID NO:81 and the amino acid sequence of SEQ ID NO:82 (pro4); (b) the amino acid sequence of SEQ ID NO:81 and the amino acid sequence of SEQ ID NO:84 (pro4); (c) the amino acid sequence of SEQ ID NO:83 and the amino acid sequence of SEQ ID NO:82 (pro4); (d) the amino acid sequence of SEQ ID NO:83 and the amino acid sequence of SEQ ID NO:84 (pro4); or (e) the amino acid sequence of SEQ ID NO:85 and the amino acid sequence of SEQ ID NO:86 (pro5). In another embodiment, the oligomeric polypeptides comprise a homo-oligomer. The homo-oligomer may be any suitable homo-oligomer, including but not limited to homotrimers. Exemplary heterodimers provided herein include homotrimers of the polypeptide comprising the amino acid sequence at least 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 83%, 90%, 95%, 96%, 97%, 98%, 99%, or 100% identical to a pRO-1 polypeptide (SEQ ID NOs:13-14), a prO-2 polypeptides (SEQ ID NOs: 1-12, 15-22, and 33-36), or a pRO-3 polypeptide (SEQ ID NOs:23-26). The polypeptides of the disclosure may include additional residues at the N-terminus, C-terminus, internal to the polypeptide, or a combination thereof; these additional residues are not included in determining the percent identity of the polypeptides of the invention relative to the reference polypeptide. Such residues may be any residues suitable for an intended use, including but not limited to detectable proteins or fragments thereof (also referred to as “tags”). As used herein, “tags” include general detectable moieties (i.e.: fluorescent proteins, antibody epitope tags, etc.), therapeutic agents, purification tags (His tags, etc.), linkers, ligands suitable for purposes of purification, ligands to drive localization of the polypeptide, peptide domains that add functionality to the polypeptides, etc. Examples are provided herein. For example, by fusing the polypeptide to a fluorescent protein, we are coupling the conformational change due to protonation of the buried histidines in the hydrogen bond networks at the interface of the helical bundle to conformational changes in the chromophore environment of the fused fluorescent protein. This provides a fluorescent readout of the conformation change. As will be understood by those of skill in the art, other functional subunits could be used in a similar manner to link the pH-based conformational change with a readout based on the function of the functional subunit. As used throughout the present application, the term “polypeptide”, “peptide” and “protein” are used interchangeably in their broadest sense to refer to a sequence of subunit amino acids of any length, which can include genetically coded and non-genetically coded amino acids, chemically or biochemically modified or derivatized amino acids, and polypeptides having modified peptide backbones. The polypeptides of the invention may comprise L-amino acids+glycine, D-amino acids+glycine (which am resistant to L-amino acid-specific proteases in vivo), or a combination of D- and L-amino acids+glycine. The polypeptides described herein may be chemically synthesized or recombinantly expressed. The polypeptides may be linked to other compounds to promote an increased half-life in vivo, such as by PEGylation, HESylation, PASylation, glycosylation, or may be produced as an Fc-fusion or in deimmunized variants. Such linkage can be covalent or non-covalent n is understood by those of skill in the art. In another aspect, the disclosure provides nucleic acids encoding the polypeptide of any embodiment or combination of embodiments of each aspect disclosed herein. The nucleic acid sequence may comprise single stranded or double stranded RNA or DNA in genomic or cDNA form, or DNA-RNA hybrids, each of which may include chemically or biochemically modified, non-natural, or derivatized nucleotide bases. Such nucleic acid sequences may comprise additional sequences useful for promoting expression and/or purification of the encoded polypeptide, including but not limited to polyA sequences, modified Kozak sequences, and sequences encoding epitope tags, export signals, and secretory signals, nuclear localization signals, and plasma membrane localization signals. It will be apparent to those of skill in the art, based on the teachings herein, what nucleic acid sequences will encode the polypeptides of the disclosure. In a further aspect, the disclosure provides expression vectors comprising the nucleic acid of any aspect of the disclosure operatively linked to a suitable control sequence. “Expression vector” includes vectors that operatively link a nucleic acid coding region or gene to any control sequences capable of effecting expression of the gene product. “Control sequences” operably linked to the nucleic acid sequences of the disclosure we nucleic acid sequences capable of effecting the expression of the nucleic acid molecules. The control sequences need not be contiguous with the nucleic acid sequences, so long as they function to direct the expression thereof. Thus, for example, intervening untranslated yet transcribed sequences can be present between a promoter sequence and the nucleic acid sequences and the promoter sequence can still be considered “operably linked” to the coding sequence. Other such control sequences include, but are not limited to, polyadenylation signals, termination signals, and ribosome binding sites. Such expression vectors can be of any type, including but not limited plasmid and viral-based expression vectors. The control sequence used to drive expression of the disclosed nucleic acid sequences in a mammalian system may be constitutive (driven by any of a variety of promoters, including but not limited to, CMV, SV40, RSV, actin, EF) or inducible (driven by any of a number of inducible promoters including, but not limited to, tetracycline, ecdysone, steroid-responsive). The expression vector must be replicable in the host organisms either as an episome or by integration into host chromosomal DNA. In various embodiments, the expression vector may comprise a plasmid, viral-based vector, or any other suitable expression vector. In another aspect, the disclosure provides host cells that comprise the expression vectors disclosed herein, wherein the host cells can be either prokaryotic or eukaryotic. The cells can be transiently or stably engineered to incorporate the expression vector of the disclosure, using techniques including but not limited to bacterial transformations, calcium phosphate co-precipitation, electroporation, or liposome mediated-, DEAE dextran mediated-, polycationic mediated-, or viral mediated transfection. A method of producing a polypeptide according to the disclosure is an additional part of the disclosure. In one embodiment, the method comprises the steps of (a) culturing a host according to this aspect of the disclosure under conditions conducive to the expression of the polypeptide, and (b) optionally, recovering the expressed polypeptide. The expressed polypeptide can be recovered from the cell free extract or recovered from the culture medium. In another embodiment, the method comprises chemically synthesizing the polypeptides. In another aspect, the disclosure provides methods for use of the polypeptides or the oligomeric polypeptides of any embodiment or combination of embodiments of the disclosure, for any suitable purpose, including but not limited to delivery of biologics into the cytoplasm through endosomal escape. Delivery methods relying on cell penetrating peptides, supercharged proteins, and lipid-fusing chemical reagents can be toxic because of nonspecific interactions with many types of membranes in a pH-independent manner. Thus, the disclosed polypeptides and oligomeric polypeptides provide a significant improvement over currently available tools. In another aspect, the disclosure provides methods for designing the polypeptides or the oligomeric polypeptide of any embodiment or combination of embodiments of the disclosure, comprising a method as described in the examples that follow. Abstract: The ability of naturally occurring proteins to change conformation in response to environmental changes is critical to biological function. The design of conformational switches remains a major challenge. Here we present a general strategy to design pH-responsive protein conformational switches by precisely pre-organizing histidine residues in buried hydrogen bond networks. We design homotrimers and heterodimers that are stable above pH 6.5, but undergo cooperative, large-scale conformational transitions when the pH is lowered and electrostatic and steric repulsion builds up as the network histidines become protonated. The pH range at which disassembly occurs, as well as the cooperativity of the transition, can be programmed by balancing the number of histidine-containing networks and the strength of the surrounding hydrophobic interactions. Upon disassembly, the designed proteins disrupt lipid membranes both in vitro and in vivo after being endocytosed in mammalian cells; the extent of disruption and the pH-dependence of membrane activity can be tuned such that no membrane activity is observed at pH 7 and substantial membrane activity is observed at and below pH 6. Our results are dynamic de novo proteins with switchable, conformation-dependent functions that provide a new route to addressing the endosomal escape challenge for intracellular delivery. We explored the de novo design of protein systems undergoing pH-dependent conformation changes both because the subtlety of the protonation slate changes makes pH-dependence an excellent model problem and a challenging test of our understanding of protein energetics, and because programmable pH-induced conformational changes could have applications for engineering pH-dependent materials and intracellular delivery agents of biological cargo. We set out to create tunable pH-responsive oligomers (pRO's) by de novo designing parametric helical bundles with extensive histidine-containing networks in which the histidine Nε and Nδ atoms are each making hydrogen bonds ( We used a three-step procedure to computationally design helical bundles with extensive histidine-containing hydrogen bond networks that span inter-helical interfaces. First, oligomeric protein backbones with an inner and outer ring of α-helices were produced by systematically varying helical parameters using the Crick generating equations. Each inner helix was connected to an outer helix through a short designed loop to produce helix-turn-helix monomer subunits. Second, the HBNet™ method in Rosetta™ was extended to computationally design networks with buried histidine residues that accept a hydrogen bond across the oligomeric interface, and then used to select the very small fraction of backbones that accommodate multiple histidine networks (see Computational Design Methods). Third, the sequence of the rest of the protein (surface residues and the hydrophobic contacts surrounding the networks) was improved while keeping the histidine networks constrained. Synthetic genes encoding five parent designs (named pRO-1 to pRO-S) with multiple histidine-containing hydrogen bond networks and tight, complementary hydrophobic packing around the networks, along with variants (named pRO-2.1, pRO-2.2, etc.) were constructed (table 3). All of the designed proteins were well-expressed, soluble, and readily purified by Ni-NTA affinity chromatography, hexahistidine tag cleavage, and a second Ni-NTA step followed by gel filtration. Oligomeric state was assessed by size-exclusion chromatography (SEC) and native mass spectrometry (24). All parent designs assembled to the intended oligomeric state at pH 7 ( The pH-Dependent Conformational Switching is Due to the Designed Histidine Networks To specifically evaluate the role of the histidine networks in the pH-induced transition of pRO-2, we sought to design a variant that lacked the histidine residues but was otherwise identical in sequence. Mutating all histidine residues to asparagine resulted in poor soluble expression and aggregation, likely because the buried asparagine residues are unable to participate in hydrogen bonds; using HBNet™, we rescued the histidine to asparagine mutations by generating networks in which all buried polar atoms participate in hydrogen bonds ( We set out to structurally characterize these designs, but both pRO-2 and pRO-2-noHis were resistant to crystallization efforts. To both test the modularity of our design strategy, as well as to generate additional constructs for crystallization, designs were made that combined networks from each of pRO-2 and pRO-2-noHis (Table 3). These variants remained soluble after disassembling and reassembled to their designed oligomeric state upon subsequent increase back to pH 7 ( We take advantage of this modularity to systematically tune the pH response by developing a model of the pH-dependence of the free energy of assembly for a homotrimer with n pH-independent hydrophobic layers, m pH-dependent hydrogen bond network layers each containing three histidine residues, and l hydrogen bond network layers lacking histidine. We assume that the protonation of individual histidine residues within a network layer is cooperative—this is plausible since the protonation of one histidine residue will likely destabilize its surrounding interface, making the remaining histidine residues more accessible and substantially reducing the free energy cost of protonation. The pH-dependence of homotrimer assembly for such a system is then where ΔGhydrophobic, ΔGpolar_m, and ΔGpolar_lare the free energies of formation of hydrophobic layers, pH-responsive polar layers, and pH-independent polar layers respectively; R is the gas constant, and pKaHis(the pKa of solvent-exposed histidine) is taken to be 6.0. Equation I requires estimates of ΔGhydrophobic, ΔGpolar_m, and ΔGpolar_l, which we obtained from guanidine denaturation experiments ( To test the tuning of the pH-dependence of disassembly, we generated additional designs based on pRO-2 with different values of m, n and l by swapping one or two of the histidine networks (red cross-sections) for either hydrophobic-only interactions (black cross-sections) or the equivalent hydrogen bond network lacking histidine (blue cross-sections) in different combinations ( We compare the observed dependence of k and pH0 on m, n and l with the predictions of the model (Eq. 1) in the following sections. In Equation 1, the pH set point (pH0) is the pH at which the free energy of assembly (the quantity in square brackets) is zero. Designs with histidine networks replaced by hydrophobic layers have higher stability as assessed by chemical denaturation experiments ( In Equation 1, the transition cooperativity (k) is simply 3m, and replacing the histidine networks (m) with polar networks lacking histidines (l) with roughly equal contribution to stability at the pKa of histidine (ΔGpolar_mroughly equal to ΔGpolar_l) allows for tuning of the cooperativity of disassembly with little effect on stability ( While Equation 1 qualitatively accounts for the dependence of disassembly and cooperativity on m, n and l, the location of the histidine network layers also contributes. For example, pRO-2.3 and pRO-2.4 have identical layer compositions ( pH-Dependent Membrane Disruption The trimer interface contains a number of hydrophobic residues that become exposed upon pH-induced disassembly; because amphipathic helices can disrupt membranes (17, 31), we investigated whether the designed proteins exhibit pH-dependent interactions with membranes. Purified protein with hexahistidine tag removed was added to synthetic liposomes containing the pH-insensitive fluorescent dye sulforhodamine B (SRB) at self-quenching concentrations over a range of pH values; leakage of liposome contents following disruption of the lipid membrane can be monitored through dequenching of the dye (32). Design pRO-2 caused pH-dependent liposome disruption at pH values as high as 6, with maximal activity around pH 5 ( To further increase the pH of disassembly without altering the putative membrane interacting residues, we tuned the pH-sensitivity by increasing or decreasing the overall interface affinity through mutations in the hydrophobic layers (tuning ΔGhydrophobic) of design pRO-2. Consistent with Eq. 1, increasing ΔGhydrophobicthrough the A54M substitution decreases the transition pH, whereas weakening ΔGhydrophobicwith the I56V substitution increases the transition pH to approximately 5.8 ( To characterize the physical interactions between protein and membranes, and the mechanism of membrane disruption, purified proteins were chemically conjugated to gold nanoparticles and visualized by cryo-electron microscopy and tomography. Design pRO-2 I56V, which has a higher transition pH ( We next investigated the behavior of the designed proteins in the low pH environment of the mammalian cell endocytic pathway. Internalized proteins are either recycled back or destined for degradation through fusing with lysosomes that contain hydrolytic enzymes that are activated at round pH 5(33). To test their behavior in the endocytic pathway, we expressed the pRO-2 trimers as fissions to +36GFP(34, 35) to facilitate both fluorescent imaging and endocytosis; these fusions also showed signs of pH-induced liposome disruption by cryo-electron microscopy and tomography ( As shown in As shown in pH-dependent membrane disruption ability can be conferred to other proteins via fusion at the n-terminus of asymmetrized single-chain pH trimers. In this example, Asym206TEVAnti (magenta) was fused to a nanoparticle and is expressed and purified from It was not previously clear how to achieve the high cooperativity that allows proteins to dramatically alter function in response to small changes in the environment. Our results now clearly answer the latter question in the affirmative—The complete loss of trimer pRO-2 over a very narrow pH range in the present disclosure demonstrates that such high cooperativity has been achieved. Furthermore, the disclosure further demonstrates the ability to systematically tune the set point and cooperativity of the conformational change. The modular and tunable pH set point and cooperativity of our designed homo-oligomers, together with their liposome permeabilizing activity, makes them attractive for delivery of biologics into the cytoplasm through endosomal escape. Delivery methods relying on cell penetrating peptides, supercharged proteins, and lipid-fusing chemical reagents can be toxic because of nonspecific interactions with many types of membranes in a pH-independent manner. Backbone Sampling: Oligomeric protein backbones with an inner and outer ring of α-helices were produced by systematically varying helical parameters using the Crick generating equations (19, 20). Ideal values were used for the supercoil twist (ω0) and helical twist (ω1)(19, 20). Starting points for the superhelical radii were chosen based on successful previous designs (18) and the helical phase (Δϕ1) was sampled from 0° to 90° with a step size of 10°. The offset along the z-axis (Z-offset) for the first helix was fixed to 0 as a reference point, with the rest of the helices independently sampled from −1.51 Å to 1.51 Å, with a step size of 1.51 Å. For heterodimer designs, supercoil phases (Δϕ0) were fixed at 0° 90°, 180° and 270°, respectively, for the four helices. The inner and outer helices were connected by short, structured loops as described previously (18). To find backbones that could accommodate more than two histidine networks, a second round of parametric design was performed with finer sampling around the helical parameters of the initial designs. (Note: because the inner and outer helices have different superhelical radii, the repeating geometric cross sections of the helical bundle are not always perfect geometric repeats along the z-axis; hence, because of the geometric sensitivity of hydrogen bonding, finer sampling was required to find backbones that could accommodate the same histidine hydrogen bond networks at multiple layers/cross sections). Design of Histidine Networks: the HBNet™ (18) method in Rosetta™ (21) was extended to include program code that allowed for the selection of hydrogen bond networks that contain at least one histidine at oligomeric interfaces, and also the option to select for cases where the histidine residue accepts a hydrogen bond across the oligomeric interface. HBNet™ was used to select backbones that could accommodate 1-4 such networks in the homotrimeric and heterodimeric backbones. Rosetta™ Design Calculations: To design the sequence and sidechain rotamer conformations for the rest of the protein surrounding the hydrogen bond networks, the network residues were constrained using AtomPair™ constraints on the donors and acceptors of the hydrogen bonds and RosettaDesign™ calculations carried out, and best designs selected. Design Strategy to Tune pH Set Point and Cooperativity Via Modular Placement of the Histine Network: Once successful designs were identified, HBNet™ was used to generate all possible combinations of hydrogen bond network placement for the existing networks within the backbone of that design; for each, the amino acid sequence and side chain rotamer conformations were optimized around those placed networks as described above. From these combinations for pRO-2, designs pRO-2.1-2.5 ( Plasmids containing synthetic genes that encode the designed proteins were ordered through Genscript, Inc. (Piscataway, N.J., USA), cloned into the NdeI and XhoI sites of either pET2I-NESG or pET-28b vectors (see table 3). Plasmids were transformed into chemically competent Cells were lysed by microfluidization in the presence of 1 mM PMSF. Lysates were clarified by centrifugation at 24,000 ref at 4° C. for at least 30 minutes. Proteins were purified by Immobilized metal affinity chromatography (IMAC): supernatant was applied to Ni-NTA (Qiagen) columns pre-equilibrated in lysis buffer. The column was washed twice with 15 column volumes (CV) of wash buffer (25 mM Tris pH 8.0 at room temperature, 300 mM NaCl, 40 mM Imidazole), followed by 3-5 CV of high-salt wash buffer (25 mM Tris pH 8.0 at room temperature, 1 M NaCl, 40 mM Imidazole) then an additional 15 CV of wash buffer. Protein was eluted with 250 mM Imidazole, and buffer-exchanged into 25 mM Tris pH 8.0 and 150 mM NaCl without imidazole for cleavage of the N-terminal hexahistidine tag by purified hexahistidine-tagged TEV protease (with the exception of design pRO-1, which was cleaved using restriction grade thrombin (EMD Millipore 69671-3) at room temperature for 4 hours or overnight, using a 1:3000 dilution of enzyme into sample solution). A second Ni-NTA step was used to remove hexahistidine tag, uncleaved sample and the hexahistidine-tagged TEV protease, and the cleaved proteins were then concentrated and further purified by gel filtration using FPLC and a Superdex™ 75 Increase 10/300 GL (GE) size exclusion column in 25 mM Tris pH 8.0 at room temperature, 150 mM NaCl, and 2% glycerol. For low-pH experiments involving circular dichroism (CD), small-angle X-ray scattering (SAXS), and size exclusion chromatography (SEC), Na2PO4-Citrate buffer was used to ensure that a single buffer system could be used that was stable over the entire pH range to be tested. Buffers were made using established ratios of stock solutions of 0.2 M Na2PO4and 0.1 M Citrate; final pH was adjusted using hydrochloric acid (HCl) or sodium hydroxide (NaOH) if needed. For SAXS and SEC, 150 mM NaCl and 2% glycerol were added. Native mass spectrometry experiments required the use of ammonium acetate buffer, and pH was adjusted using acetic acid, with the final pH value measured (see Native Mass Spectrometry section below). For liposome disruption assays, 10 mM Tris, 150 mM NaCl, 0.02% NaN3, pH 8.0 was used and pH was changed by rapid acidification using 10 mM HEPES, 150 mM NaCl, 50 mM Citrate and 0.02% NaN3buffer at pH 3.0 as described previously (32), and final pH values were measured (see Fluorescence Dequenching Liposome Leakage Assay section below). Hexahistidine tag was removed for all experiments that tested the effect of pH. CD wavelength scans (260 to 195 nm) and temperature melts (25 to 95° C.) were measured using a JASCO™ J-1500 or an AVIV™ model 420 CD spectrometer. Temperature melts monitored absorption signal at 222 nm and were carried out at a heating rate of 4° C./min; protein samples were at 0.25 mg/mL in either phosphate buffered saline (PBS) pH 7.4 or Na2PO4-Citrate at indicated pH values (see Buffers systems for varying pH). Guanidinium chloride (GdmCl) titrations were all performed on an AVIV 420 spectrometer with an automated titration apparatus using either PBS pH 7.4 or Na2PO4-Citrate buffers at indicated pH at room temperature, monitoring helical signal at 222 nm, using a protein concentration of 0.025 mg/mL in a 1 cm cuvette with stir bar. Each titration consisted of at least 30 evenly distributed concentration points with one minute mixing time for each step. Titrant solution consisted of the same concentration of protein in the same buffer system plus GdmCl; GdmCl concentration of starting solutions was determined by reactive index. Samples were buffer exchanged twice into 200 mM ammonium acetate (NH4Ac; MilliporeSigma) using Micro Bio-Spin P-6 columns (Bio-Rad). Protein concentrations were determined by UV absorbance using a Nanodrop 2000c spectrophotometer (Thermo Fisher Scientific) and diluted to make up a 10-fold stock solution (50 μM and 16.7 μM monomer and trimer concentration, respectively). 1 μL of this solution was mixed with 9 μL 200 mM NH4Ac/50 mM triethylammonium acetate (TEAA; MilliporeSigma), adjusted with acetic acid (Fisher Scientific) to obtain the desired final pH and incubated on ice for 30 min. For experiments to test for the reversibility of disassembly, the pH was subsequently increased either by addition of ammonia or by buffer-exchange to 200 mM NH4Ac/50 mM TEAA (pH 7.0) via ultrafiltration (Amicon Ultra, MWCO 3 kDa). 5 μL samples were filled into an in-house pulled glass capillary and ionized by nESI at a monomer or a trimer concentration of 5 μM or 1.67 μM respectively. All pH titration data were acquired on an in-house modified SYNAPT® G2 HDMS (Waters Corporation) with a surface-induced dissociation (SID) device incorporated between a truncated trap traveling wave ion guide and the ion mobility cell (39). The following instrument parameters were used spray voltage 0.9-1.3 kV; sampling cone, 20 V; extraction cone, 2 V; source temperature, room temperature; trap gas flow, 4 mL/min; trap bins, 45V. The data were processed with MassLynx™ v4.1 and DriftScope™ v2.1. Smoothed mass spectra (mean; window 20; number of smooths 20) are shown in Samples were purified by gel filtration in either 25 mM Tris pH 8.0 at room temperature, 150 mM NaCl, and 2% glycerol, or Na2PO4-Citrate buffer at indicated pH with 150 mM NaCl and 2% glycerol. For each sample, data was collected for at least two different concentrations to test for concentration-dependent effects; “high” concentration samples ranged from 4-10 mg/ml and “low” concentration samples ranged from 1-5 mg/ml (table 5). Fractions preceding the void volume of the column, or from the flow-through during concentration using spin concentrators (Millipore), were used as blanks for buffer subtraction. SAXS measurements were made at the SiBYLS™ 12.3.1 beamline at the Advanced Light Source. The X-ray wavelength (λ) was 1.27 Å and the sample-to-detector distance of the Mar165 detector was 1.5 m, corresponding to a scattering vector q (q=4π*sin(θ/λ) where 2θ is the scattering angle) range of 0.01 to 0.59 Å−1. Data sets were collected using 34 0.2 second exposures over a period of 7 seconds at 11 keV with protein at a concentration of 6 mg/mL. The light path is generated by a super-bend magnet to provide a 1012 photons/sec flux (1 Å wavelength) and detected on a Pilatus3 2M pixel array detector. Each sample is collected multiple times with the same exposure length, generally every 0.3 seconds for a total of 10 seconds resulting in 30-34 fames per sample. These individual spectra were averaged together over each of the Gunier, Parod, and Wide-q regions depending on signal quality over each region and frame using the FrameSlice™ web server. The averaged spectra for each sample were analyzed using the ScÅtter™ software package as previously described (29, 40). FoXS™ (41,42) was used to compare design models to experimental scattering profiles and calculate quality of fit (X) values. Purified protein samples were concentrated to 13 ng/ml for pRO-2.3 and 17 mg/ml for pRO-2 Sin 20 mM Tris pH 8.0 at room temperature with 100 mM NaCl. Samples were screened with a 5-position deck Mosquito crystallization robot (ttplabtech) with an active humidity chamber, utilizing JCSG Core™ I-IV screens (Qiagen). Crystals were obtained after 2 to 14 days by the sitting drop vapor diffusion method with the drops consisting of a 1:1, 2:1 and 1:2 mixture of protein solution and reservoir solution. The conditions that resulted in the crystals used for structure determination are as follows: pRO-2.3 crystallized in JCSG-I B7, which consists of 0.2M di-sodium tartrate and 20% w/v PEG 3350; pRO-2.5 crystalized in JCSG-I A9, which consists of 0.2 M Potassium acetate and 20% w/v PEG 3350. Protein crystals were looped and placed in reservoir solution containing 20% (v/v) glycerol as a cryoprotectant, and flash-frozen in liquid nitrogen. Datasets were collected at the Advanced Light Source at Lawrence Berkeley National Laboratory with beamlines 8.2.1 and 8.2.2. Data sets were indexed and scaled using XDS (43). Phase information was obtained by molecular replacement using the program PHASER™ (44) from the Phenix software suite (45); computational design models were used for the initial search. Following molecular replacement, the models were improved using Phenix™ autobuild (46); efforts were made to reduce model bias by setting rebuild-in-place to false, and using simulated annealing and prime-and-switch phasing. Iterative rounds of manual building in COOT™ (47) and refinement in Phenix™ were used to produce the final models. Due to the high degree of self-similarity inherit in coiled-coil-like proteins, datasets for the reported structures suffered from a high degree of pseudo translational non-crystallographic symmetry, as report by Phenix™.Xtriage, which complicated structure refinement and may explain the higher than expected R-values reported. RMSDs of bond lengths, angles and dihedrals from ideal geometries were calculated using Phenix™ (45). The overall quality of the final models was assessed using MOLPROBITY (48). Table 4 summarizes diffraction data and refinement statistics. Liposomes composed of DOPC (1,2-dioleoyl-sn-glycero-3-phosphocholine), DOPC with 25% cholesterol (molar ratio to DOPC), 3:1 DOPC:POPS (1-palmitoyl-2-oleoyl-sn-glycero-3-phospho-L-serine), and 3:1 DOPC:POPS with 25% cholesterol were prepared identically to a final concentration of 5 mM total lipid as previously described (32); lipids from Avanti Polar Lipids. Lipids solubilized in chloroform were dried under nitrogen gas and stored under vacuum for a minimum of 2 hours to remove residual solvent. The dried lipid film was the resuspended in Tris buffer (10 mM Tris, 150 mM NaCl, and 0.02% NaN3pH 8.0) containing 25 mM Sulforhodamine B (SRB) fluorophore (Sigma) and subjected to 10 sequential freeze thaw cycles in liquid nitrogen. Liposomes were extruded 29 times through 100 nm pore size polycarbonate filters (Avanti Polar Lipids) and purified from free fluorophore using a PD-10 gel filtration column (GE Healthcare) into storage buffer (10 mM Tris, 150 mM NaCl, and 0.02% NaN3pH 8.0). Liposome size and homogeneity was analyzed by dynamic light scattering (DLS) using a Dynapro Nanostar™ DLS (Wyatt Technologies). On average liposome diameter ranged from 120-130 nm with low polydispersity. Liposomes were stored at 4° C. and used within 5 days of preparation. Liposome disruption and content leakage was analyzed by fluorescence spectroscopy as previously described (32). Liposomes containing SRB fluorophore at self-quenching concentrations were incubated with 2.5 μM peptide, with respect to monomer, at 24° C. and pH 8.0 in Tris buffer (10 mM Tris, 150 mM NaCl, 0.02% NaN3, pH 8.0) for 10 minutes. The solution was rapidly acidified to the target pH by addition of a fixed volume of acidification buffer and incubated for 20 minutes. Acidification buffers are mixtures of the Tris pH 8.0 buffer and citrate buffer pH 3.0 (10 mM HEPES, 150 mM NaCl, 50 mM Citrate and 0.02% NaN3pH 3.0) in empirically determined ratios to achieve the target pH. SRB fluorescence is independent of pH within the ranges used here. Finally. Triton X-100 (Sigma) was added to a final concentration of 1% to fully disrupt liposomes. Liposome disruption as indicated by content leakage and SRB dequenching was normalized using the formula [Fω−F(0)]/[F(Max)−F(0)] where F(0)is the average fluorescence intensity before acidification and F(Max)is the average fluorescence intensity ater addition of Triton X-100. All measurements were collected on a Varian Cary Eclipse spectrophotometer using an excitation/emission pairing of 1 565/586 and 2.5 nm slit widths at 24° C. Any data plotted together was collected using the sum batch of liposomes. Designs pRO-2, pRO-2 I56V, and pRO-2-noHis were chemically conjugated to 10 nm Gold nanoparticles according to manufacturer's instructions, ensuring all gold nanoparticles were conjugated to protein. The conjugation reactions were performed immediately prior to use for electron microscopy imaging. For each design pRO-2, pRO-2 I56V, and pRO-2-noHis a solution of 2.5 μM purified protein, 0.125 μM gold-conjugated protein, and 1 mM DOPC liposomes was applied to glow-discharged C-Flat 2/2-2C-T holey carbon grids (Protochips, Inc.) and acidified on the grid by addition of HEPES-citrate buffer. The grids were prepared using a Vitrobot Mark IV (FEI) at 4 C and 100% humidity before being plunge-frozen in ethane cooled with liquid nitrogen. Electron micrographs were collected using a Tecnai G2 Spirit™ Transmission Electron Microscope (FEI) operated at 120 kV and equipped with a 4k×4k Gatan Ultrascan CCD camera at a nominal magnification of 26,000× or a Tecnai TF-20 Transmission Electron Microscope (FEI) operated at 200 kV equipped with a K2 Summit Direct Electron Detector (Gatan). Projection micrographs collected on the TF-20 were captured with the detector operating in counting mode. Specimens were imaged at 14,500 magnification, giving a pixel size of 0.254 nm, with a dose of ˜18e−/Å2across 75 200 ms movie frames. Data were collected in a semi-automated fashion using Leginon™ (49) and micrograph movie frames were aligned using MotionCor2™ (50). Leginon™ was used to collect tomography tilt series from −48 to +48 degrees bidirectionally in 3 degree increments with a total accumulated dose of ˜100 e−/Å2. Reconstructions were processed using etomo in the IMOD™ software suite (31) with CTF parameters estimated from CTFFIND4™ (52). Reconstructed tomograms were visualized and measurements were made using ImageJ™ (53). U-2 OS (ATCC) cells were cultured in DMEM supplemented with 10% (v/v) inactivated FBS (Corning), 2 mM glutamine, penicillin (100 IU/mL), and streptomycin (100 μg/mL) at 37° C. and 5% CO2. The glass-bottom coverslip chambers were pre-coated with 500 μg/mL of Matrigel (Corning). Transfection of LAMP1-HaloTag™ was performed using Lonza Nucleofector system according to the manufacturer's specifications. After overnight of recovery and expression, the cells expressing LAMP1-HaloTag™ were labeled with 100 nM JF646-HTL for 30 minutes and washed three times with pre-warmed DMEM medium. The final concentration of 5 μM+36GFP fusion proteins was incubated with the LAMP1-HaloTag™ expressing U-2 OS cells on a pre-coated coverslip for 1 hr. Cells were fixed with 4% paraformaldehyde for 20 min at room temperature (RT) and quenched/rinsed with PBS supplemented with 30 mM glycine. Then, the coverslips were mounted on FluoroSave™ (Millipore). For pH measurement of the lysosome, LysoSensor™ Yellow/Blue DND-160 was incubated at 1 mg/mL overnight and washed twice prior to imaging (54). The final concentration of 5 μM protein was incubated with the LAMP1-HaloTag expressing U2-OS cells that were loaded with 1 mg/mL LysoSensor™ Yellow/Blue DND-160 for 1 hr. In separate chambers, LysoSensor™ Yellow/Blue DND-160 loaded cells were incubated with bafilomycin A1 (1 μM) and chloroquine (50 μM) for 1 hr as a control. For fixed cell confocal microscopy, a customized Nikon TiE inverted scope outfitted with a Yokogawa spinning-disk scan head (#CSU-X1) along with an Andor iXon™ EM-CCD camera (DU-897) with 100-ns exposure time was used to collect 3D images using an SR Apo TIRF 100×1.49 oil-immersion objective. Mender's coefficients were calculated in 3D with JF646 signal (LAMP-HaloTag) and +36GFP signal (corresponding proteins) using Imaris software with thresholding. Zeiss 880 equipped with AiryScan™ was also used to obtain high resolution images using a Plan-Apochromatic 63×/1.4 oil DIC objective. For live cell confocal microscopy, Zeiss 880 was used to collect LysoSensor™ Yellow/Blue signal. LysoSensor™ Yellow/Blue was excited with a 405 nm laser, and its emission was collected into the two regions (Blue=410-499 nm Yellow=500-600 nm) using a Plan-Apochromat 63×/1.4 oil DIC objective. The ratio of the two channels was calculated using the home-built software in Matlab™. All structural images for figures were generated using PyMOL™ (55). Python scripts were written to generate theoretical models according Equation 1, and curve-fitting to native mass spectrometry data ( Disclosed herein are polypeptides or polypeptide oligomers, including a buried hydrogen bond network that includes at least (1, 2, 3, 4, 5, 6, 7, 8, or 9) pH sensitive amino acids located (i) at an intra-chain interface between different: structural elements in one polypeptide, or (it) at an inter-chain interface between structural elements present in different chains of a polypeptide oligomer, wherein the polypeptide or polypeptide oligomer is stable above a given pH, and wherein the polypeptide or polypeptide oligomer undergoes a conformational transition when subjected to a pH at or below the given pH. 1. A non-naturally occurring polypeptide or polypeptide oligomer, comprising a buried hydrogen bond network that comprises at least 1, 2, 3, 4, 5, 6, 7, 8, or 9 pH sensitive amino acids located (i) at an intra-chain interface between different structural elements in one polypeptide, or (ii) at an inter-chain interface between structural elements present in different chains of a polypeptide oligomer, wherein the polypeptide or polypeptide oligomer is stable above a given pH, and wherein the polypeptide or polypeptide oligomer undergoes a conformational transition when subjected to a pH at or below the given pH. 2.-6. (canceled) 7. The polypeptide or polypeptide oligomer of 8.-9. (canceled) 10. A non-naturally occurring pH-responsive polypeptide, or polypeptide oligomer, comprising an oligomeric helical bundle comprising at least four alpha-helical subunits, wherein the oligomeric helical bundle comprises
one or more interfaces; and one or more histidine-containing layers that participate in buried hydrogen bond networks, wherein each histidine Ne and NS atoms are hydrogen-bonded across the one or more interfaces; wherein the polypeptide or polypeptide oligomer is stable above a given pH, and wherein oligomers (including but not limited to dimers or trimers) of the polypeptide undergo a conformational transition when subjected to a pH at or below the given pH. 11.-14. (canceled) 15. The polypeptide of X1 and X17 are independently absent or comprise peptides; X2, X4, X6, X8, X10, X12, X14, and X16 are each 1-2 amino acids that may be comprised of either hydrophobic residues or polar residues, forming a helical secondary structure, wherein at least 1, 2, 3, 4, 5, 6, 7, or all 8 of X2, X4, X6, X8, X10, X12, X14, and X16 include a histidine residue; X3, X5, X7, X11, X13, and X15 are 5-6 residue variable amino acid linkers forming a helical secondary structure; and X9 comprises a loop, including but not limited to a hairpin loop, of variable amino acids. 16. The polypeptide of 17. (canceled) 18. The polypeptide of 19. (canceled) 20. The polypeptide of X6-X8 form a first helical secondary structure; X10-X12 form a second helical structure; X9 comprises a loop of variable amino acid length and sequence; and wherein at least 1, 2, 3, 4, 5, or all 6 of X6, X7, X8, X10, X11, and X12 include a pH sensitive amino acid residue; wherein the polypeptide or an oligomer comprising the polypeptide undergoes a conformational transition when subjected to a pH at or below the given pH;
X4-X8 form a first helical secondary structure: X10-X14 form a second helical structure: X9 comprises a loop of variable amino acid length and sequence; and wherein at least 1, 2, 3, 4, 5, 6, 7, 8, 9, or all 10 of X4, X5, X6, X7, X8, X10, X11, X12, X13, and X14 include a pH sensitive amino acid residue: wherein the polypeptide or an oligomer comprising the polypeptide undergoes a conformational transition when subjected to a pH at or below the given pH; or
X2-X8 form a first helical secondary structure; X10-X16 form a second helical structure; X9 comprises a loop of variable amino acid length and sequence; and wherein at least 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, or all 14 of X2, X3, X4, X5, X6, X7, X8, X10, X11, X12, X13, X14, X15, and X16 include a pH sensitive amino acid residue; wherein the polypeptide or an oligomer comprising the polypeptide undergoes a conformational transition when subjected to a pH at or below the given pH. 21.-22. (canceled) 23. The polypeptide of 24.-25. (canceled) 26. The polypeptide of 27. (canceled) 28. The polypeptide of 29.-30. (canceled) 31. The polypeptide of 32. The polypeptide of 33. (canceled) 34. The polypeptide of 35. A non-naturally occurring polypeptide, comprising the amino acid sequence at least 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, or 100% identical to the amino acid sequence of one of SEQ ID NOS:1-77 and 81-86. 36. The polypeptide of 37.-38. (canceled) 39. An oligomeric polypeptide comprising two or more polypeptides of 40. (canceled) 41. The oligomer of (I) a heterodimer between polypeptides comprising the amino acid sequence at least 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, or 100% identical to:
(a) the amino acid sequence of SEQ ID NO:81 and the amino acid sequence of SEQ ID NO:82; (b) the amino acid sequence of SEQ ID NO:81 and the amino acid sequence of SEQ ID NO:84; (c) the amino acid sequence of SEQ ID NO:83 and the amino acid sequence of SEQ ID NO:82; (d) the amino acid sequence of SEQ ID NO:83 and the amino acid sequence of SEQ ID NO:84; or (e) the amino acid sequence of SEQ ID NO:85 and the amino acid sequence of SEQ ID NO:86; or (II) a homo-trimer of a polypeptide comprising the amino acid sequence at least 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 96%, 97%, 98%, 99%, or 100% identical to the amino acid sequence of one of SEO ID NOS: 1-26 or 33-36. 42.-43. (canceled) 44. A nucleic acid encoding the polypeptide of 45. A recombinant expression vector comprising the nucleic acid of 46. A recombinant host cell comprising the nucleic acid of 47.-49. (canceled)CROSS REFERENCE
REFERENCE TO SEQUENCE LISTING
BACKGROUND
SUMMARY
DESCRIPTION OF THE FIGURES
DETAILED DESCRIPTION
X1-X2-X3-X4-X5-X6-X7-X8-X9-X10-X11-X12-X13-X14-X15-X16-X17, wherein:
X6-X7-X8-X9-X10-X11-X12, wherein;
X4-X5-X6-X7-X8-X9-X10-X11-X12-X13-X14, wherein;
X2-X3-X4-X5-X6-X7-X8-X9-X10-X11-X12-X13-X14-X15-X16, wherein:pRO-2 MGSHHHHHHGSGSENLYFQGSEYEIRKALEELKAATAE LKRATASLRAITEELKKNPSEDALVEHNRAIVEHNAII VEHNRIIAAVLELIVRAIE (SEQ ID NO: 1) SEYEIRKALEELKAATAELKRATASLRAITEELKKNPS EDALVEHNRAIVEHNAIIVEHNRIIAAVLELIVRAIK (SEQ ID NO: 2) pRO- MGSHHHHHHGSGSENLYFQGSEYEIRKALEELKAALAE 2.1 LKRATASLRAITEELKKNPSEDALVEHNRAIVEHNAII VEVLRIIAAVLELIVRAIE (SEQ ID NO: 3) SEYEIRKALEELKAALAELKRATASLRAITEELKKNPS EDALVEHNRAIVEHNAIIVEVLRIIAAVLELIVRAIK (SEQ ID NO: 4) pRO- MGSHHHHHHGSGSENLYFQGSEYEIRKALEELKAALAE 2.2 LKRATASLRAILEELKKNPSEDAIVEAIRAIVEHNAII VEVLRIIAAVLELIVRAIE (SEQ ID NO: 5) SEYEIRKALEELKAALAELKRATASLRAILEELKKNPS EDAIVEAIRAIVEHNAIIVEVLRIIAAVLELIVRAIE (SEQ ID NO: 6) pRO- MGSHHHHHHGSGSENLYFQGSEYEIRKALEELKASTAE 2.3 LKRATASLRAITEELKKNPSEDALVEHNRAIVEHNAII VENNRIIAAVLELIVRAIE (SEQ ID NO: 7) SEYEIRKALEELKASTAELKRATASLRAITEELKKNPS EDALVEHNRAIVEHNAIIVENNRIIAAVLELIVRAIE (SEQ ID NO: 8) pRO- MGSHHHHHHGSGSENLYFQGSEYEIRKALEELKAATAE 2.4 LKRATASLRASTEELKKNPSEDALVENNRLIVEHNAII VEHNRIIAAVLELIVRAIE (SEQ ID NO: 9) SEYEIRKALEELKAATAELKRATASLRASTEELKKNPS EDALVENNRLIVEHNAIIVEHNRIIAAVLELIVRAIE (SEQ ID NO: 10) pRO- MGSHHHHHHGSGSENLYFQGSEYEIRKALEELKASTAE 2.5 LKRATASLRASTEELKKNPSEDALVENNRLIVEHNAII VENNRIIAAVLELIVRAIE (SEQ ID NO: 11) SEYEIRKALEELKASTAELKRATASLRASTEELKKNPS EDALVENNRLIVEHNAIIVENNRIIAAVLELIVRAIE (SEQ ID NO: 12) pRO-2 MGSHHHHHHGSGSENLYFQGSEYEIRKALEELKAATAE LKRATASLRAITEELKKNPSEDALVEHNRAIVEHNAII VEHNRIIAAVLELIVRAIK (SEQ ID NO: 1) SEYEIRKALEELKAATAELKRATASLRAITEELKKNPS EDALVEHNRAIVEHNAIIVEHNRIIAAVLELIVRAIK (SEQ ID NO: 2) pRO- MGSHHHHHHGSGSENLYFQGSEYEIRKALEELKAALAE 2.1 LKRATASLRAITEELKKNPSEDALVEHNRAIVEHNAII VEVLRIIAAVLELIVRAIK (SEQ ID NO: 3) SEYEIRKALEELKAALAELKRATASLRAITEELKKNPS EDALVEHNRAIVEHNAIIVEVLRIIAAVLELIVRAIK (SEQ ID NO: 4) pRO- MGSHHHHHHGSGSENLYFQGSEYEIRKALEELKAALAE 2.2 LKRATASLRAILEELKKNPSEDALVEAIRAIVEHNAII VEVLRIIAAVLELIVRAIK (SEQ ID NO: 5) SEYEIRKALEELKAALAELKRATASLRAILEELKKNPS EDAIVEAIRAIVEHNAIIVEVLRIIAAVLELIVRAIK (SEQ ID NO: 6) pRO- MGSHHHHHHGSGSENLYFQGSEYEIRKALEELKASTAE 2.3 LKRATASLRAITEELKKNPSEDALVEHNRAIVEHNAII VENNRIIAAVLELIVRAIK (SEQ ID NO: 7) SEYEIRKALEELKASTAELKRATASLRAITEELKKNPS EDALVEHNRAIVEHNAIIVENNRIIAAVLELIVRAIK (SEQ ID NO: 8) pRO- MGSHHHHHHGSGSENLYFQGSEYEIRKALEELKAATAE 2.4 LKRATASLRASTEELKKNPSEDALVENNRAIVEHNAII VEHNRIIAAVLELIVRAIK (SEQ ID NO: 9) SEYEIRKALEELKAATAELKRATASLRASTEELKKNPS EDALVENNRLIVEHNAIIVEHNRIIAAVLELIVRAIK (SEQ ID NO: 10) pRO- MGSHHHHHHGSGSENLYFQGSEYEIRKALEELKASTAE 2.5 LKRATASLRASTEELKKNPSEDALVENNRLIVEHNAII VENNRIIAAVLELIVRAIK (SEQ ID NO: 11) SEYEIRKALEELKASTAELKRATASLRASTEELKKNPS EDALVENNRLIVEHNAIIVENNRIIAAVLELIVRAIK (SEQ ID NO: 12) Amino acid sequences of all designs tested. All constructs were cloned into pET21-NESG plasmid except for design pRO-1, which was cloned in PET28b. Heterodimers pRO-4 and pRO-5 were ordered as constructs; DNA sequence containing stop codon, additional ribosome binding sequence, and second start codon is shown by the lower case letters in parenthesis (this sequence is not included in the amino acid sequence or associate SEQ ID NO). Underlined regions are removed after hexahistidine tag cleavage (i.e.: they are optional). Bold positions indicate mutations/differences between a design variant and its parent design. Design name Amino acid sequences of designed proteins in this study pRO-1 MGSSHHHHHHSSGLVPRGSHMGTLKEVLERLEEVLRRHREVAREHQRWAREHEQWVRDDP NSAKWIAESTRWILETTDAISRTADVLAEAIRVLAESD (SEQ ID NO: 13) GSHMGTLKEVLERLEEVLRRHREVAREHQRWAREHEQWVRDDPNSAKWIAESTRWILETT DAISRTADVLAEAIRVLAESD (SEQ ID NO: 14) pRO-2 MGSHHHHHHGSGSENLYFQGSEYEIRKALEELKAATAELKRATASLRAITEELKKNPSED ALVEHNRAIVEHNAIIVEHNRIIAAVLELIVRAIK (SEQ ID NO: 1) SEYEIRKALEELKAATAELKRATASLRAITEELKKNPSEDALVEHNRAIVEHNAIIVEHN RIIAAVLELIVRAIK (SEQ ID NO: 2) pRO-2 H45N/ MGSHHHHHHGSGSENLYFQGSEYEIRKALEELKAATAELKRATASLRAITEELKKNPSED H52N/H59N ALVENNRAIVENNAIIVENNRIIAAVLELIVRAIK (SEQ ID NO: 15) GSEYEIRKALEELKAATAELKRATASLRAITEELKKNPSEDALVENNRAIVENNAIIVEN NRIIAAVLELIVRAIK (SEQ ID NO: 16) pRO-2- MGSHHHHHHGSGSENLYFQGSEYEIRKALEELKASTAELKRSTASLRASTEELKKNPSED noHis ALVENNRLIVENNAIIVENNRIIAAVLELIVRAIK (SEQ ID NO: 75) Inactive control GSEYEIRKALEELKASTAELKRSTASLRASTEELKKNPSEDALVENNRLIVENNAIIVEN NRIIAAVLELIVRAIK (SEQ ID NO: 76) Inactive control pRO-2.1 MGSHHHHHHGSGSENLYFQGSEYEIRKALEELKAALAELKRATASLRAITEELKKNPSED ALVEHNRAIVEHNAIIVEVLRIIAAVLELIVRAIK (SEQ ID NO: 3) SEYEIRKALEELKAALAELKRATASLRAITEELKKNPSEDALVEHNRAIVEHNAIIVEVL RIIAAVLELIVRAIK (SEQ ID NO: 4) pRO-2.2 MGSHHHHHHGSGSENLYFQGSEYEIRKALEELKAALAELKRATASLRAILEELKKNPSED AIVEAIRAIVEHNAIIVEVLRIIAAVLELIVRAIK (SEQ ID NO: 5) SEYEIRKALEELKAALAELKRATASLRAILEELKKNPSEDAIVEAIRAIVEHNAIIVEVL RIIAAVLELIVRAIK (SEQ ID NO: 6) pRO-2.3 MGSHHHHHHGSGSENLYFQGSEYEIRKALEELKASTAELKRATASLRAITEELKKNPSED ALVEHNRAIVEHNAIIVENNRIIAAVLELIVRAIK (SEQ ID NO: 7) SEYEIRKALEELKASTAELKRATASLRAITEELKKNPSEDALVEHNRAIVEHNAIIVENN RIIAAVLELIVRAIK (SEQ ID NO: 8) pRO-2.4 MGSHHHHHHGSGSENLYFQGSEYEIRKALEELKAATAELKRATASLRASTEELKKNPSED ALVENNRLIVEHNAIIVEHNRIIAAVLELIVRAIK (SEQ ID NO: 9) SEYEIRKALEELKAATAELKRATASLRASTEELKKNPSEDALVENNRLIVEHNAIIVEHN RIIAAVLELIVRAIK (SEQ ID NO: 10) pRO-2.5 MGSHHHHHHGSGSENLYFQGSEYEIRKALEELKASTAELKRATASLRASTEELKKNPSED ALVENNRLIVEHNAIIVENNRIIAAVLELIVRAIK (SEQ ID NO: 11) SEYEIRKALEELKASTAELKRATASLRASTEELKKNPSEDALVENNRLIVEHNAIIVENN RIIAAVLELIVRAIK (SEQ ID NO: 12) pRO-2 I56V MGSHHHHHHGSGSENLYFQGSEYEIRKALEELKAATAELKRATASLRAITEELKKNPSED ALVEHNRAIVEHNAIVVEHNRIIAAVLELIVRAIK (SEQ ID NO: 17) GSEYEIRKALEELKAATAELKRATASLRAITEELKKNPSEDALVEHNRAIVEHNAIVVEH NRIIAAVLELIVRAIK (SEQ ID NO: 18) pRO-2 A54M MGSHHHHHHGSGSENLYFQGSEYEIRKALEELKAATAELKRATASLRAITEELKKNPSED ALVEHNRAIVEHNMIIVEHNRIIAAVLELIVRAIK (SEQ ID NO: 19) GSEYEIRKALEELKAATAELKRATASLRAITEELKKNPSEDALVEHNRAIVEHNMIIVEH NRIIAAVLELIVRAIK (SEQ ID NO: 20) pRO-2 I70N MGSHHHHHHGSGSENLYFQGSEYEIRKALEELKAATAELKRATASLRAITEELKKNPSED ALVEHNRAIVEHNAIIVEHNRIIAAVLELNVRAIK (SEQ ID NO: 21) GSEYEIRKALEELKAATAELKRATASLRAITEELKKNPSEDALVEHNRAIVEHNAIIVEH NRIIAAVLELNVRAIK (SEQ ID NO: 22) pRO-3 MGSHHHHHHGSGSENLYFQGSEALYELEKALRELKKATAALERATAELKKNPSEDALVEH NRLIAAHNKIIAEVLRIIAKVLK (SEQ ID NO: 23) GSEALYELEKALRELKKATAALERATAELKKNPSEDALVEHNRLIAAHNKIIAEVLRIIA KVLK (SEQ ID NO: 24) pRO-3.1 MGSHHHHHHGSGSENLYFQGSEALYELEKATRELKKATDELERATEELEKNPSEDALVEH NRLIAEHNKIIAEHNRIIAKVLK (SEQ ID NO: 25) GSEALYELEKATRELKKATDELERATEELEKNPSEDALVEHNRLIAEHNKIIAEHNRIIA KVLK (SEQ ID NO: 26) pRO-4 MDEEDHLKKLKTHLEKLERHLKLLEDHAKKLEDILKERPEDSAVKESIDELRRSIELVRE internal SIEIFRQSVEEEE(taagaaggagatatcatcatg)GSSHHHHHHSSGENLYFQGDVKEL ribosome TKILDTLTKILETATKVIKDATKLLEEHRKSDKPDPRLIETHKKLVEEHETLVRQHKELA binding EEHLKRTR (SEQ ID NO: 27) site MDEEDHLKKLKTHLEKLERHLKLLEDHAKKLEDILKERPEDSAVKESIDELRRSIELVRE SIEIFRQSVEEEE(taagaaggagatatcatcatg)GDVKELTKILDTLTKILETATKVI KDATKLLEEHRKSDKPDPRLIETHKKLVEEHETLVRQHKELAEEHLKRTR (SEQ ID NO: 28) Chain A MDEEDHLKKLKTHLEKLERHLKLLEDHAKKLEDILKERPEDSAVKESIDELRRSIELVRE SIEIFRQSVEEEE (SEQ ID NO: 81) Chain B GSSHHHHHHSSGENLYFQGDVKELTKILDTLTKILETATKVIKDATKLLEEHRKSDKPDP RLIETHKKLVEEHETLVRQHKELAEEHLKRTR (SEQ ID NO: 82) pRO-4 L23A/ MDEEDHLKKLKTHLEKLERHLKLAEDHAKKLEDILKERPEDSAVKESIDELRRSIELVRE V130A SIEIFRQSVEEEE(taagaaggagatatcatcatg)GSSHHHHHHSSGENLYFQGDVKEL TKILDTLTKILETATKVIKDATKLLEEHRKSDKPDPRLIETHKKLVEEHETLARQHKELA EEHLKRTR (SEQ ID NO: 29) MDEEDHLKKLKTHLEKLERHLKLAEDHAKKLEDILKERPEDSAVKESIDELRRSIELVRE SIEIFRQSVEEEE(taagaaggagatatcatcatg)GDVKELTKILDTLTKILETATKVI KDATKLLEEHRKSDKPDPRLIETHKKLVEEHETLARQHKELAEEHLKRTR (SEQ ID NO: 30) MDEEDHLKKLKTHLEKLERHLKLAEDHAKKLEDILKERPEDSAVKESIDELRRSIELVRE SIEIFRQSVEEEE (SEQ ID NO: 83) GSSHHHHHHSSGENLYFQGDVKELTKILDTLTKILETATKVIKDATKLLEEHRKSDKPDP RLIETHKKLVEEHETLARQHKELAEEHLKRTR (SEQ ID NO: 84) pRO-5 MTKEDILERQRKIIERAQEIHRRQQEILKEQEKIIRKPGSSEEAMKRSLKLIEESLRLLK ELLELSEESAQLLYEQR(taagaaggagatatcatcatgGSSHHHHHHSSGENLYFQGTE KRLLEEAERAHREQKEIIKKAQELHKELTKIHQQSGSSEEAKKRALKISQEIRELSKRSL ELLREILYLSQEQK (SEQ ID NO: 31) MTKEDILERQRKIIERAQEIHRRQQEILKEQEKIIRKPGSSEEAMKRSLKLIEESLRLLK ELLELSEESAQLLYEQR(taagaaggagatatcatcatg)GTEKRLLEEAERAHREQKEI IKKAQELHKELTKIHQQSGSSEEAKKRALKISQEIRELSKRSLELLREILYLSQEQK (SEQ ID NO: 32) MTKEDILERQRKIIERAQEIHRRQQEILKEQEKIIRKPGSSEEAMKRSLKLIEESLRLLK ELLELSEESAQLLYEQR (SEQ ID NO: 85) GSSHHHHHHSSGENLYFQGTEKRLLEEAERAHREQKEIIKKAQELHKELTKIHQQSGSSE EAKKRALKISQEIRELSKRSLELLREILYLSQEQK (SEQ ID NO: 86) pRO-2-GS MGSHHHHHHGSGSENLYFQGSEYEIRKALEELKAATAELKRATASLRAITEELKKGGSGS GSEDALVEHNRAIVEHNAIIVEHNRIIAAVLELIVRAIK (SEQ ID NO: 33) GSEYEIRKALEELKAATAELKRATASLRAITEELKKGGSGSGSEDALVEHNRAIVEHNAI IVEHNRIIAAVLELIVRAIK (SEQ ID NO: 34) pRO-2.3-GS MGSHHHHHHGSGSENLYFQGSEYEIRKALEELKASTAELKRATASLRAITEELKKGGSGS GSEDALVEHNRAIVEHNAIIVENNRIIAAVLELIVRAIK (SEQ ID NO: 35) GSEYEIRKALEELKASTAELKRATASLRAITEELKKGGSGSGSEDALVEHNRAIVEHNAI IVENNRIIAAVLELIVRAIK (SEQ ID NO: 36) indicates data missing or illegible when filed (SEQ ID NO: 37) GSEEEIKRLLEELRKSSEELRRITKELDDLSKELRVGGSGSGSEMLVEH NKLISEHNRTIVENNRIIVEILEAIARVGGSGSGSVEVERILDELRKSS EELDRVTKELKKLTEELDVGGSENLYFQGSGSVEALVRHNVLITRHNDI IVKNNDIINKILKLIAEAVGGSGSGSELERILRELEESTKELRKATEEL RRLSEELKVGGSGSGSVEALVRHNEAIVEHNKIIVKNNDIIVKILELIT ERI (SEQ ID NO: 38) GSEEEIKRLLEELRKSSEELRRITKELDDLSKELRVGGSGSGSEMLVEH NKLISEHNRIIVENNRIIVEILEAIARVGGSGSGSVEVERILDELRKSS EELDRVTKELKKLTEELDVGGSGSGSVEALVRHNVLITRHNDIIVKNND IINKILKLIGEAVGGSENLYFQGSGSEFERWLRQLEESTKELRKFTEEL RRFSEELKVGGSGSGSVEALVRHNEAIVEHNKAIVKNNDIIVKILELVT ERI (SEQ ID NO: 39) GSEEEIKRLLEELRKSSEELRRITKELDDLSKELRVGGSGSGSLVPRGS GSGSGSHALVEHNKLISEHNRIVVENNRIIVEILEAIARVGGSGSGSVE VERILDELRKSSEELDRVTKELKKLTEELDVGGSGSGSLVPRGSGSGSG SVEALVRHNVLITRHNDIVVKNNDIINKILKLIAEAVGGSGSGSELERI LRELEESTKELRKATEELRRLSEELKVGGSGSGSLVPRGSGSGSGSHEA LVRHNEAIVEHNKIVVKNNDIIVKILELITERI (SEQ ID NO: 40) GSEEEIKRLLEELRKALEELRRITKELDDLSKELRVGGSGSGSLVPRGS GSGSGSHALVEHNKLISEHNRIVVEVLRIIAEILEAIARVGGSGSGSVE VERILDELRKALEELDRVTKELKKLTEELDVGGSGSGSLVPRGSGSGSG SVEALVRHNVLITRHNDIVVKVLDIIAKILKLIAEAVGGSGSGSELERI LRELEEALKELRKATEELRRLSEELKVGGSGSGSLVPRGSGSGSGSHEA LVRHNEAIVEHNKIVVKVLDIIAKILELITERI single_chain_noHis_asym_163 (SEQ ID NO: 41) (MGSSHHHHHHSSGLVPRGS)HMGSDELKYELEKSTRELQKSTDELEKSTEELERNPSKDVLVENNELIVRNNKI IVKNNIIIVRTEKKGSGGSGDELKEELEKSTRELDKSTKKLERSTEELKRNPSKDALVENNKLIVENNTIIVRNN DIIVRTRKKGSGGSGDELKEELEKSTRELKKSTKELQKSTEELERNPSKDALVKNNKLIADNNRIIVRNNTIIVR DIKAS Inactive control single_chain_noHis_asym_163 (SEQ ID NO: 42) HMGSDELKYELEKSTRELQKSTDELEKSTEELERNPSKDVLVENNELIVRNNKIIVKNNIIIVRTEKKGSGGSGD ELKEELEKSTRELDKSTKKLERSTEELKRNPSKDALVENNKLIVENNTIIVRNNDIIVRTRKKGSGGSGDELKEE LEKSTRELKKSTKELQKSTEELERNPSKDALVKNNKLIADNNRIIVRNNTIIVRDIKAS Inactive control single_chain_noHis_asym_162 (SEQ ID NO: 43) (MGSSHHHHHHSSGLVPRGS)HMGSDDEDLDRVLEELRRSTEELDRSTKDLERSTQELRRNPSVDALVKNNNAIV RNNEIIVENNRIILEVLELLLRSIKGSGGSGDREEIKKVLDELRESTERLERSTEELRRSTEELKKNPAVEVLVR NNTIIVKNNKIIVDNNRIIVRVLELLEKTIKGSGGSGDKYEIRKVLKELKDSTEELRNSTKNLTDSTEELKRNPS VEILVKNNILIVENNKIIVENNRIIVDVLELIRKAIAS Inactive control single_chain_noHis_asym_162 (SEQ ID NO: 44) HMGSDDEDIDRVLEELRRSTEELDRSTKDLERSTQELRRNPSVDALVKNNNAIVRNNEIIVENNRIILEVLELLL RSIKGSGGSGDREEIKKVLDELRESTERLERSTEELRRSTEELKKNPAVEVLVRNNTIIVKNNKIIVDNNRIIVR VLELLEKTIKGSGGSGDKYEIRKVLKELKDSTEELRNSTKNLTDSTEELKRNPSVEILVKNNILIVENNKIIVEN NRIIVDVLELIRKAIAS Inactive control single_chain_asym_162 (SEQ ID NO: 45) (MGSSHHHHHHSSGLVPRGS)HMGSDDEDLDRVLEELRRITEELDRITKDLERLTQELRRNPSVDALVKHNNAIV RHNEIIVEHNRIILEVLELLLRSIKGSGGSGDREEIKKVLDELREATERLERATEELRRLTEELKKNPAVEVLVR HNTIIVKHNKIIVDHNRIIVRVLELLEKTIKGSGGSGDKYEIRKVLKELKDITEELRNMTKNLTDLTEELKRNPS VEILVKHNILIVEHNKIIVEHNRIIVDVLELIRKAIAS single_chain_asym_162 (SEQ ID NO: 46) HMGSDDEDIDRVLEELRRITEELDRITKDLERLTQELRRNPSVDALVKHNNAIVRHNEIIVEHNRIILEVLELLL RSIKGSGGSGDREEIKKVLDELREATERLERATEELRRSTEELKKNPAVEVLVRHNTIIVKHNKIIVDHNRIIVR VLELLEKTIKGSGGSGDKYEIRKVLKELKDITEELRNMTKNLTDLTEELKRNPSVEILVKHNILIVEHNKIIVEH NRIIVDVLELIRKAIAS TagGFP2-TEV-TagBFP: Two fluorescent proteins TagGFP2 and TagBFP fused together by a TEV protease site linker. (SEQ ID NO: 47) (MGSSHHHHHHSSGLVPRGS)HMSGGEELFAGIVPVLIELDGDVHGHKFSVRGEGEGDADYGKLEIKFICTTGKL PVPWPTLVTTLCYGIQCFARYPEHMKMNDFFKSAMPEGYIQERTIQFQDDGKYKTRGEVKFEGDTLVNRIELKGK DFKEDGNILGHKLEYSFNSHNVYIRPDKANNGLEANFKTRHNIEGGGVQLADHYQTNVPLGDGPVLIPINHYLST QTKISKDRNEARDHMVLLESFSACCHTGGSGGSENLYFQGASGGSGSELIKENMHMKLYMEGTVDNHHFKCTSEG EGKPYEGTQTMRIKVVEGGPLPFAFDILATSFLYGSKTFINHTQGIPDFFKQSFPEGFTWERVTTYEDGGVLTAT QDTSLQDGCLIYNVKIRGVNFTSNGPVMQKKTLGWEAFTETLYPADGGLEGRNDMALKLVGGSHLIANIKTTYRS KKPAKNLKMPGVYYVDYRLERIKEANNETYVEQHEVAVARY (SEQ ID NO: 48) HMSGGEELFAGIVPVLIELDGDVHGHKFSVRGEGEGDADYGKLEIKFICTTGKLPVPWPTLVTTLCYGIQCFARY PEHMKMNDFFKSAMPEGYIQERTIQFQDDGKYKTRGEVKFEGDTLVNRIELKGKDFKEDGNILGHKLEYSFNSHN VYIRETKANNGLEANFKTRHNIEGGGVQLADHYQTNVPLGDGPVLIPINHYLSTQTKISKDRNEARDHMVLLESF SACCHTGGSGGSENLYFQGASGGSGSELIKENMHMKLYMEGTVDNHHFKCTSEGEGKPYEGTQTMRIKVVEGGPL PFAFDILATSFLYGSKTFINHTQGIPDFFKQSFPEGFTWERVTTYEDGGVLTATQDTSLQDGCLIYNVKIRGVNF TSNGPVMQKKTLGWEAFTETLYPADGGLEGRNDMALKLVGGSHLIANIKTTYRSKKPAKNLKMPGVYYVDYRLER IKEANNETYVEQHEVAVARY TagGFP2-single_chain_noHis_asym_163-TagBFP (SEQ ID NO: 49) (MGSSHHHHHHSSGLVPRGS)HMSGGEELFAGIVFVLIELDGDVHGHKFSVRGEGEGDADYGKLEIKFICTTGKL PVPWPTLVTTLCYGIQCFARYPEHMKMNDFFKSAMPEGYIQERTIQFQDDGKYKTRGEVKFEGDTLVNRIELKGK DFKEDGNILGHKLEYSFNSHNVYIRPDKANNGLEANFKTRHNIEGGGVQLADHYQTNVPLGDGPVLIPINHYLST QTKISKDRNEARDHMVLLESFSACCHTGGSGGSDELKYELEKSTRELQKSTDELEKSTEELERNPSKDVLVENNE LIVRNNKIIVKNNIIIVRTEKKGSGGSGDELKEELEKSTRELDKSTKKLERSTEELKRNPSKDALVENNKLIVEN NTIIVRNNDIIVRTRKKGSGGSGDELKEELEKSTRELKKSTKELQKSTEELERNPSKDALVKNNKLIADNNRIIV RNNTIIVRDIKASGGSGSELIKENMHMKLYMEGTVDNHHFKCTSEGEGKPYEGTQTMRIKVVEGGPLPFAFDILA TSFLYGSKTFINHTQGIPDFFKQSFPEGFTWERVTTYEDGGVLTATQDTSLQDGCLIYNVKIRGVNFTSNGPVMQ KKTLGWEAFTETLYPADGGLEGRNDMALKLVGGSHLIANIKTTYRSKKPAKNLKMPGVYYVDYRLERIKEANNET YVEQHEVAVARY Inactive control TagGFP2_single_chain_noHis_asym_163-TagBFP (SEQ ID NO: 50) HMSGGEELFAGIVPVLIELDGDVHGHKFSVRGEGEGDADYGKLEIKFICTTGKLPVPWPTLVTTLCYGIQCFARY PEHMKMNDFFKSAMPEGYIQERTIQFQDDGKYKTRGEVKFEGDTLVNRIELKGKDFKEDGNILGHKLEYSFNSHN VYIRPDKANNGLEANFKTRHNIEGGGVQLADHYQTNVPLGDGPVLIPINHYLSTQTKISKDRNEARDHMVLLESF SACCHTGGSGGSDELKYELEKSTRELQKSTDELEKSTEELERNPSKDVLVENNELIVRNNKIIVKNNIIIVRTEK KGSGGSGDELKEELEKSTRELDKSTKKLERSTEELKRNPSKDALVENNKLIVENNTIIVRNNDIIVRTRKKGSGG SGDELKEELEKSTRELKKSTKELQKSTEELERNPSKDALVKNNKLIADNNRIIVRNNTIIVRDIKASGGSGSELI KENMHMKLYMEGTVDNHHFKCTSEGEGKPYEGTQTMRIKVVEGGPLPFAFDILATSFLYGSKTFINHTQGIPDFF KQSFPEGFTWERVTTYEDGGVLTATQDTSLQDGCLIYNVKIRGVNFTSNGPVMQKKTLGWEAFTETLYPADGGLE GRNDMALKLVGGSHLIANIKTTYRSKKPAKNLKMFGVYYVDYRLERIKEANNETYVEQHEVAVARY Inactive control TagGFP2-single_chain_noHis_asym_163-TagBFP (SEQ ID NO: 51) (MGSSHHHHHHSSGLVPRGS)HMSGGEELFAGIVPVLIELDGDVHGHKFSVRGEGEGDADYGRLEIKFICTTGKL PVPWPTLVTTLCYGIQCFARYPEHMKMNDFFKSAMPEGYIQERTIQFQDDGKYKTRGEVKFEGDTLVNRIELKGK DFKEDGNILGHKLEYSFNSHNVYIRPDKANNGLEANFKTRHNIEGGGVQLADHYQTNVPLGDGPVLIPINHYLST QTKISKDRNEARDHMVLLESFSACCHTGGSGGSDELKYELEKSTRELQKSTDELEKSTEELERNPSKDVLVENNE LIVRNNKIIVKNNIIIVRTEKKGSGGSGDELKEELEKSTRELDKSTKKLERSTEELKRNPSKDALVENNKLIVEN NTIIVRNNDIIVRTRKKGSGGSGDELKEELEKSTRELKKSTKELQKSTEELERNPSKDALVKNNKLIADNNRIIV RNNTIIVRDIKASGGSGSELIKENMHMKLYMEGTVDNHHFKCTSEGEGKPYEGTQTMRIKVVEGGPLPFAFDILA TSFLYGSKTFINHTQGIPDFFKQSFPEGFTWERVTTYEDGGVLTATQDTSLQDGCLIYNVKIRGVNFTSNGPVMQ KKTLGWEAFTETLYPADGGLEGRNDMALKLVGGSHLIANIKTTYRSKKPAKNLKMPGVYYVDYRLERIKEANNET YVEQHEVAVARY Inactive control TagGFP2-single_chain_noHis_asym_163-TagBFP (SEQ ID NO: 52) HMSGGEELFAGIVPVLIELDGDVHGHKFSVRGEGEGDADYGKLEIKFICTTGKLPVPWPTLVTTLCYGIQCFARY PEHMKMNDFFKSAMPEGYIQERTIQFQDDGKYKTRGEVKFEGDTLVNRIELKGKDFKEDGNILGHKLEYSFNSHN VYIRPDKANNGLEANFKTRHNIEGGGVQLADHYQTNVPLGDGPVLIPINHYLSTQTKISKDRNEARDHMVLLESF SACCHTGGSGGSDELKYELEKSTRELQKSTDELEKSTEELERNPSKDVLVENNELIVRNNKIIVKNNIIIVRTEK KGSGGSGDELKEELEKSTRELDKSTKKLERSTEELKRNPSKDALVENNKLIVENNTIIVRNNDIIVRTRKKGSGG SGDELKEELEKSTRELKKSTKELQKSTEELERNPSKDALVKNNKLIADNNRIIVRNNTIIVRDIKASGGSGSELI KENMHMKLYMEGTVDNHHFKCTSEGEGKPYEGTQTMRIKVVEGGPLPFAFDILATSFLYGSKTFINHTQGIPDFF KQSFPEGFTNERVTTYEDGGVLTATQDTSLQDGCLIYNVKIRGVNFTSNGPVMQKKTLGWEAFTETLYPADGGLE GRNDMALKLVGGSHLIANIKTTYRSKKPAKNLKMPGVYYVDYRLERIKEANNETYVEQHEVAVARY Inactive control cpmoxCerulean_v2 (SEQ ID NO: 53) (MGSSHHHHHHSSGENLY)FQGSGSGGIHGNVYITADKQKNGIKANFGLNSNVEDGSVQLADHYQQNTPIGDGPV LLPDNHYLSTQSALSKDPNEKRDHMVLLEFVTAAGITLGMDELYKGGTGGSMVSKGEELFTGVVPILVELDGDVN GHKFSVRGEGEGDATNGKLTLKFISTTGKLPVPWPTLVTTLSWGVQSFARYPDHMKQHDFFKSAMPEGYVQERTI FFKDDGTYKTRAEVKFEGDTLVNRIELKGIDFKEDGNILGHKLEY* Inactive cpmoxCerulean_v2 (SEQ ID NO: 54) FQGSGSGGIHGNVYITADKQKNGIKANFGLNSNVEDGSVQLADHYQQNTPIGDGPVLLPDNHYLSTQSALSKDPN EKRDHMVLLEFVTAAGITLGMDELYKGGTGGSMVSKGEELFTGVVPILVELDGDVNGHKFSVRGEGEGDATNGKL TLKFISTTGKLPVPWPTLVTTLSWGVQSFARYPDHMKQHDFFKSAMPEGYVQERTIFFKDDGTYKTRAEVKFEGD TLVNRIELKGIDFKEDGNILGHKLEY* Inactive SB13(2 + 1)-cpmoxCerulean3_v2 (SEQ ID NO: 55) (MGSSHHHHHHSSGENLY)FQGSGSGSTKYELRRALEELEKALRELKKSLDELERSLEELEKNPSEDALVENNRL NVENNKIIVEVLRIIAEVLKINAKSDGSGSGSTKYELRRALEELEKALRELKKSLDELERSLEELEKNPSEDALV ENNRLNVENNKIIVEVLRTIAEVLKINAKSDGSGIHGNVYITADKQKNGIKANFGLNSNVEDGSVQLADHYQQNT PIGDGPVLLPDNHYLSTQSALSKDPNEKRDHMVLLEFVTAAGITLGMDELYKGGTGGSMVSKGEELFTGVVPILV ELDGDVNGHKFSVRGEGEGDATNGKLTLKFISTTGKLPVPWPTLVTTLSWGVQSFARYPDHMKQHDFFKSAMPEG YVQERTIFFKDDGTYKTRAEVKFEGDTLVNRIELKGIDFKEDGNILGHKLEYGGSTKYELRRALEELEKALRELK KSLDELERSLEELEKNPSEDALVENNRLNVENNKIIVEVLRIIAEVLKINAKSD* Inactive control SB13(2 + 1)-cpmoxCerulean3_v2 (SEQ ID NO: 56) FQGSGSGSTKYELRRALEELEKALRELKKSLDELERSLEELEKNPSEDALVENNRLNVENNKIIVEVLRIIAEVL KINAKSDGSGSGSTKYELRRALEELEKALRELKKSLDELERSLEELEKNPSEDALVENNRLNVENNKIIVEVLRT IAEVLKINAKSDGSGIHGNVYITADKQKNGIKANFGLNSNVEDGSVQLADHYQQNTPIGDGPVLLPDNHYLSTQS ALSKDPNEKRDHMVLLEFVTAAGITLGMDELYKGGTGGSMVSKGEELFTGVVPILVELDGDVNGHKFSVRGEGEG DATNGKLTLKFISTTGKLPVPWPTLVTTLSWGVQSFARYPDHMKQHDFFKSAMPEGYVQERTIFFKDDGTYKTRA EVKFEGDTLVNRIELKGIDFKEDGNILGHKLEYGGSTKYELRRALEELEKALRELKKSLDELERSLEELEKNPSE DALVENNRLNVENNKIIVEVLRIIAEVLKINAKSD* Inactive control SB13(2 + 1)-cpmoxCerulean3_v2-cfSGFP2 (SEQ ID NO: 77) (MGSSHHHHHHSSGENLY)FQGSGSGSTKYELRRALEELEKALRELKKSLDELERSLEELEKNPSEDALVENNRL NVENNKIIVEVLRIIAEVLKINAKSDGSGSGSTKYELRRALEELEKALRELKKSLDELERSLEELEKNPSEDALV ENNRLNVENNKIIVEVLRIIAEVLKINAKSDGSGIHGNVYITADKQKNGIKANFGLNSNVEDGSVQLADHYQQNT PIGDGPVLLPDNHYLSTQSALSKDPNEKRDHMVLLEFVTAAGITLGMDELYKGGTGGSMVSKGEELFTGVVPILV ELDGDVNGHKFSVRGEGEGDATNGKLTLKFISTTGKLPVPWPTLVTTLSWGVQSFARYPDHMKQHDFFKSAMPEG YVQERTIFFKDDGTYKTRAEVKFEGDTLVNRIELKGIDFKEDGNILGHKLEYGGSTKYELRRALEELEKALRELK KSLDELERSLEELEKNPSEDALVENNRLNVENNKIIVEVLRIIAEVLKINAKSDMVSKGEELFTGVVPILVELDG DVNGHKFSVSGEGEGDATYGKLTLKFISTTGKLPVPWPTLVTTLTYGVQMFARYPDHMKQHDFFKSAMPEGYVQE RTIFFKDDGNYKTRAEVKFEGDTLVNRIELKGIDFKEDGNILGHKLEYNYNSHNVYITADKQKNGIKANFKIRHN IEDGGVQLADHYQQNTPIGDGPVLLPDNHYLSTQSKLSKDPNEKRDHMVLLEFVTAAGITLGMDELYK Inactive control SB13(2 + 1)-cpmoxCerulean3_v2-cfSGFP2 (SEQ ID NO: 57) FQGSGSGSTKYELRRALEELEKALRELKKSLDELERSLEELEKNPSEDALVENNRLNVENNKIIVEVLRIIAEVL KINAKSDGSGSGSTKYELRRALEELEKALRELKKSLDELERSLEELEKNPSEDALVENNRLNVENNKIIVEVLRI IAEVLKINAKSDGSGIHGNVYITADKQKNGIKANFGLNSNVEDGSVQLADHYQQNTPIGDGPVLLPDNHYLSTQS ALSKDPNEKRDHMVLLEFVTAAGITLGMDELYKGGTGGSMVSKGEELFTGVVPILVELDGDVNGHKFSVRGEGEG DATNGKLTLKFISTTGKLPVPWPTLVTTLSWGVQSFARYPDHMKQHDFFKSAMPEGYVQERTIFFKDDGTYKTRA EVKFEGDTLVNRIELKGIDFKEDGNILGHKLEYGGSTKYELRRALEELEKALRELKKSLDELERSLEELEKNPSE DALVENNRLNVENNKIIVEVLRIIAEVLKINAKSDMVSKGEELFTGVVPILVELDGDVNGHKFSVSGEGEGDATY GKLTLKFISTTGKLPVPWPTLVTTLTYGVQMFARYPDHMKQHDFFKSAMPEGYVQERTIFFKDDGNYKTRAEVKF EGDTLVNRIELKGIDFKEDGNILGHKLEYNYNSHNVYITADKQKNGIKANFKIRHNIEDGGVQLADHYQQNTPIG DGPVLLPDNHYLSTQSKLSKDPNEKRDHMVLLEFVTAAGITLGMDELYK Inactive control SB13.2(2 + 1)-cpmoxCerulean3_v2-cfSGFP2 (SEQ ID NO: 58) (MGSSHHHHHHSSGENLY)FQGSGSGSTKYELRRALEELEKALRELKKSLDELERSLEELEKNPSEDALVENNRL NVENNKIIVEVLRIIAEVLKINAKSDGSGSGSTKYELRRALEELEKALRELKKSLDELERSLEELEKNPSEDALV ENNRLNVENNKIIVEVLRIIAEVLKINAKEDGSGIHGNVYITADKQKNGIKANFGLNSNVEDGSVQLADHYQQNT PIGDGPVLLPDNHYLSTQSALSKDPNEKRDHMVLLEFVTAAGITLGMDELYKGGTGGSMVSKGEELFTGVVPILV ELDGDVNGHKFSVRGEGEGDATNGKLTLKFISTTGKLPVPWPTLVTTLSWGVQSFARYPDHMKQHDFFKSAMPEG YVQERTIFFKDDGTYKTRAEVKFEGDTLVNRIELKGIDFKEDGNILGHKLEYGSGSTKYELRRALEELEKALREL KKSLDELERSLEELEKNPSEDALVENNKIIVEVLRIIVEVLRIIAEVLKINAKSDMVSKGEELFTGVVPILVELD GDVNGHKFSVSGEGEGDATYGKLTLKFISTTGKLPVPWPTLVTTLTYGVQMFARYPDHMKQHDFFKSAMPEGYVQ ERTIFFKDDGNYKTRAEVKFEGDTLVNRIELKGIDFKEDGNILGHKLEYNYNSHNVYITADKQKNGIKANFKIRH NIEDGGVQLADHYQQNTPIGDGPVLLPDNHYLSTQSKLSKDPNEKRDHMVLLEFVTAAGITLGMDELYK Inactive control SB13.2(2 + 1)-cpmoxCerulean3_v2-cfSGFP2 (SEQ ID NO: 59) FQGSGSGSTKYELRRALEELEKALRELKKSLDELERSLEELEKNPSEDALVENNRLNVENNKIIVEVLRIIAEVL KINAKSDGSGSGSTKYELRRALEELEKALRELKKSLDELERSLEELEKNPSEDALVENNRLNVENNKIIVEVLRI IAEVLKINAKEDGSGIHGNVYITADKQKNGIKANFGLNSNVEDGSVQLADHYQQNTPIGDGPVLLPDNHYLSTQS ALSKDPNEKRDHMVLLEFVTAAGITLGMDELYKGGTGGSMVSKGEELFTGVVPILVELDGDVNGHKFSVRGEGEG DATNGKLTLKFISTTGKLPVPWPTLVTTLSWGVQSFARYPDHMKQHDFFKSAMPEGYVQERTIFFKDDGTYKTRA EVKFEGDTLVNRIELKGIDFKEDGNILGHKLEYGSGSTKYELRRALEELEKALRELKKSLDELERSLEELEKNPS EDALVENNKIIVEVLRIIVEVLRIIAEVLKINAKSDMVSKGEELFTGVVPILVELDGDVNGHKFSVSGEGEGDAT YGKLTLKFISTTGKLPVPWPTLVTTLTYGVQMFARYPDHMKQHDFFKSAMPEGYVQERTIFFKDDGNYKTRAEVK FEGDTLVNRIELKGIDFKEDGNILGHKLEYNYNSHNVYITADKQKNGIKANFKIRHNIEDGGVQLADHYQQNTPI GDGPVLLPDNHYLSTQSKLSKDPNEKRDHMVLLEFVTAAGITLGMDELYK Inactive control 163(2 + 1)-cpmoxCerulean3_v2 This embodiment shows pH-responsive fluorescence intensity modulation due to fused helical bundle pH-responsive conformational switching that is allosterically coupled to chromophore environment. (SEQ ID NO: 60) (MGSSHHHHHHSSGENLY)FQGSGSGSEALYELEKATRELKKATDELERATEELEKNPSEDALVEHNRLIAEHNK IIAEHNRIIAKVLKGSGSGSEALYELEKATRELKKATDELERATEELEKNPSEDALVEHNRLIAEHNKIIAEHNR IIAKVLKGSGIHGNVYITADKQKNGIKANFGLNSNVEDGSVQLADHYQQNTPIGDGPVLLPDNHYLSTQSALSKD PNEKRDHMVLLEFVTAAGITLGMDELYKGGTGGSMVSKGEELFTGVVPILVELDGDVNGHKFSVRGEGEGDATNG KLTLKFISTTGKLPVPWPTLVTTLSWGVQSFARYPDHMKQHDFFKSAMPEGYVQERTIFFKDDGTYKTRAEVKFE GDTLVNRIELKGIDFKEDGNILGHKLEYGGSEALYELEKATRELKKATDELERATEELEKNPSEDALVEHNRLTA EHNKIIAEHNRIIAKVLK 163(2 + 1)-cpmoxCerulean3_v2: This embodiment shows pH-responsive fluorescence intensity modulation due to fused helical bundle pH-responsive conformational switching that is allosterically coupled to chromophore environment. (SEQ ID NO: 61) FQGSGSGSEALYELEKATRELKKATDELERATEELEKNPSEDALVEHNRLIAEHNKIIAEHNRIIAKVLKGSGSG SEALYELEKATRELKKATDELERATEELEKNPSEDALVEHNRLIAEHNKIIAEHNRIIAKVLKGSGIHGNVYITA DKQKNGIKANFGLNSNVEDGSVQLADHYQQNTPIGDGPVLLPDNHYLSTQSALSKDPNEKRDHMVLLEFVTAAGI TLGMDELYKGGTGGSMVSKGEELFTGVVPILVELDGDVNGHKFSVRGEGEGDATNGKLTLKFISTTGKLPVPWPT LVTTLSWGVQSFARYPDHMKQHDFFKSAMPEGYVQERTIFFKDDGTYKTRAEVKFEGDTLVNRIELKGIDFKEDG NILGHKLEYGGSEALYELEKATRELKKATDELERATEELEKNPSEDALVEHNRLTAEHNKIIAEHNRIIAKVLK 163.2(2 + 1)-cpmoxCerulean3_v2: This embodiment shows pH-responsive fluorescence intensity modulation due to fused helical bundle pH-responsive conformational switching that is allosterically coupled to chromophore environment. (SEQ ID NO: 62) (MGSSHHHHHHSSGENLY)FQGSGSGSEALYELEKATRELKKATDELERATEELEKNPSEDALVEHNRLIAEHNK IIAEHNRIIAKVLKGSGSGSEALYELEKATRELKKATDELERATEELEKNPSEDALVEHNPLIAEHNKIIAEHNR IIAKVLKGSGIHGNVYITADKQKNGIKANFGLNSNVEDGSVQLADHYQQNTPIGDGPVLLPDNHYLSTQSALSKD PNEKRDHMVLLEFVTAAGITLGMDELYKGGTGGSMVSKGEELFTGVVPILVELDGDVNGHKFSVRGEGEGDATNG KLTLKFISTTGKLPVPWPTLVTTLSWGVQSFARYPDHMKQHDFFKSAMPEGYVQERTIFFKDDGTYKTRAEVKFE GDTLVNRIELKGIDFKEDGNILGHKLEYGSGSEALYELEKATRELKKATDELERATEELEKNPSEDALVEHNRLI AEHNKIIAEHNRIIAKVLK 163.2(2 + 1)-cpmoxCerulean3_v2: This embodiment shows pH-responsive fluorescence intensity modulation due to fused helical bundle pH-responsive conformational switching that is allosterically coupled to chromophore environment. (SEQ ID NO: 63) FQGSGSGSEALYELEKATRELKKATDELERATEELEKNPSEDALVEHNRLIAEHNKIIAEHNRIIAKVLKGSGSG SEALYELEKATRELKKATDELERATEELEKNPSEDALVEHNPLIAEHNKIIAEHNRIIAKVLKGSGIHGNVYITA DKQKNGIKANFGLNSNVEDGSVQLADHYQQNTPIGDGPVLLPDNHYLSTQSALSKDPNEKRDHMVLLEFVTAAGI TLGMDELYKGGTGGSMVSKGEELFTGVVPILVELDGDVNGHKFSVRGEGEGDATNGKLTLKFISTTGKLPVPWPT LVTTLSWGVQSFARYPDHMKQHDFFKSAMPEGYVQERTIFFKDDGTYKTRAEVKFEGDTLVNRIELKGIDFKEDG NILGHKLEYGSGSEALYELEKATRELKKATDELERATEELEKNPSEDALVEHNRLIAEHNKIIAEHNRIIAKVLK (I56V)163.2(2 + 1)-cpmoxCerulean3_v2: This embodiment shows pH-responsive fluorescence intensity modulation due to fused helical bundle pH-responsive conformational switching that is allosterically coupled to chromophore environment. (SEQ ID NO: 64) (MGSSHHHHHHSSGENLY)FQGSGSGSEALYELEKATRELKKATDELERATEELEKNPSEDALVEHNRLIAEHNK IVAEHNRIIAKVLKGSGSGSEALYELEKATRELKKATDELERATEELEKNPSEDALVEHNRLIAEHNKIVAEHNR IIAKVLKGSGIHGNVYITADKQKNGIKANFGLNSNVEDGSVQLADHYQQNTPIGDGPVLLPDNHYLSTQSALSKD PNEKRDHMVLLEFVTAAGITLGMDELYKGGTGGSMVSKGEELFTGVVPILVELDGDVNGHKFSVRGEGEGDATNG KLTLKFISTTGKLPVPWPTLVTTLSWGVQSFARYPDHMKQHDFFKSAMPEGYVQERTIFFKDDGTYKTRAEVKFE GDTLVNRIELKGIDFKEDGNILGHKLEYGSGSEALYELEKATRELKKATDELERATEELEKNPSEDALVEHNRLI AEHNKIVAEHNRIIAKVLK (I56V)163.2(2 + 1)-cpmoxCerulean3_v2: This embodiment shows pH-responsive fluorescence intensity modulation due to fused helical bundle pH-responsive conformational switching that is allosterically coupled to chromophore environment. (SEQ ID NO: 65) FQGSGSGSEALYELEKATRELKKATDELERATEELEKNPSEDALVEHNRLIAEHNKIVAEHNRIIAKVLKGSGSG SEALYELEKATRELKKATDELERATEELEKNPSEDALVEHNRLIAEHNKIVAEHNRIIAKVLKGSGIHGNVYITA DKQKNGIKANFGLNSNVEDGSVQLADHYQQNTPIGDGPVLLPDNHYLSTQSALSKDPNEKRDHMVLLEFVTAAGI TLGMDELYKGGTGGSMVSKGEELFTGVVPILVELDGDVNGHKFSVRGEGEGDATNGKLTLKFISTTGKLPVPWPT LVTTLSWGVQSFARYPDHMKQHDFFKSAMPEGYVQERTIFFKDDGTYKTRAEVKFEGDTLVNRIELKGIDFKEDG NILGHKLEYGSGSEALYELEKATRELKKATDELERATEELEKNPSEDALVEHNRLIAEHNKIVAEHNRIIAKVLK 163.2(2 + 1)-cpmoxCerulean3_v2-cfSGFP2: This embodiment shows pH-responsive fluorescence intensity modulation due to fused helical bundle pH-responsive conformational switching that is allosterically coupled to chromophore environment. (SEQ ID NO: 66) MGSGSEALYELEKATRELKKATDELERATEELEKNPSEDALVEHNRLIAEHNKIIAEHNRIIAKVLKGSGSGSEA LYELEKATRELKKATDELERATEELEKNPSEDALVEHNRLIAEHNKIIAEHNRIIAKVLKGSGIHGNVYITADKQ KNGIKANFGLNSNVEDGSVQLADHYQQNTPIGDGPVLLPDNHYLSTQSALSKDPNEKRDHMVLLEFVTAAGITLG MDELYKGGTGGSMVSKGEELFTGVVPILVELDGDVNGHKFSVRGEGEGDATNGKLTLKFISTTGKLPVPWPTLVT TLSWGVQSFARYPDHMKQHDFFKSAMPEGYVQERTIFFKDDGTYKTRAEVKFEGDTLVNRIELKGIDFKEDGNIL GHKLEYGSGSEALYELEKATRELKKATDELERATEELEKNPSEDALVEHNRLIAEHNKIIAEHNRIIAKVLKMVS KGEELFTGVVPILVELDGDVNGHKFSVSGEGEGDATYGKLTLKFISTTGKLPVPWPTLVTTLTYGVQMFARYPDH MKQHDFFKSAMPEGYVQERTIFFKDDGNYKTRAEVKFEGDTLVNRIELKGIDFKEDGNILGHKLEYNYNSHNVYI TADKQKNGIKANFKIRHNIEDGGVQLADHYQQNTPIGDGPVLLPDNHYLSTQSKLSKDPNEKRDHMVLLEFVTAA GITLGMDELYK Control fusion of cpmoxCerulean3_v2 (a novel cpFP) and cfSGFP2 (SEQ ID NO: 67) (MGSSHHHHHHSSGENLY)FQGSGSGIHGNVYITADKQKNGIKANFGLNSNVEDGSVQLADHYQQNTPIGDGPVL LPDNHYLSTQSALSKDPNEKRDHMVLLEFVTAAGITLGMDELYKGGTGGSMVSKGEELFTGVVPILVELDGDVNG HKFSVRGEGEGDATNGKLTLKFISTTGKLPVPWPTLVTTLSWGVQSFARYPDHMKQHDFFKSAMPEGYVQERTIF FKDDGTYKTRAEVKFEGDTLVNRIELKGIDFKEDGNILGHKLEYGSGSGMVSKGEELFTGVVPILVELDGDVNGH KFSVSGEGEGDATYGKLTLKFISTTGKLPVPWPTLVTTLTYGVQMFARYPDHMKQHDFFKSAMPEGYVQERTIFF KDDGNYKTRAEVKFEGDTLVNRIELKGIDFKEDGNILGHKLEYNYNSHNVYITADKQKNGIKANFKIRHNIEDGG VQLADHYQQNTPIGDGPVLLPDNHYLSTQSKLSKDPNEKRDHMVLLEFVTAAGITLGMDELYK Inactive control Control fusion of cpmoxCerulean3_v2 (a novel cpFP) and cfSGFP2 (SEQ ID NO: 68) FQGSGSGIHGNVYITADKQKNGIKANFGLNSNVEDGSVQLADHYQQNTPIGDGPVLLPDNHYLSTQSALSKDPNE KRDHMVLLEFVTAAGITLGMDELYKGGTGGSMVSKGEELFTGVVPILVELDGDVNGHKFSVRGEGEGDATNGKLT LKFISTTGKLPVPWPTLVTTLSWGVQSFARYPDHMKQHDFFKSAMPEGYVQERTIFFKDDGTYKTRAEVKFEGDT LVNRIELKGIDFKEDGNILGHKLEYGSGSGMVSKGEELFTGVVPILVELDGDVNGHKFSVSGEGEGDATYGKLTL KFISTTGKLPVPWPTLVTTLTYGVQMFARYPDHMKQHDFFKSAMPEGYVQERTIFFKDDGNYKTRAEVKFEGDTL VNRIELKGIDFKEDGNILGHKLEYNYNSHNVYITADKQKNGIKANFKIRHNIEDGGVQLADHYQQNTPIGDGPVL LPDNHYLSTQSKLSKDPNEKRDHMVLLEFVTAAGITLGMDELYK Inactive control pH-reponsive cpFP pH sensor with optimized linker, with C-terminal cfSGFP2. This embodiment shows pH-responsive fluorescence intensity modulation due to fused helical bundle pH-responsive conformational switching that is allosterically coupled to chromophore environment. (SEQ ID NO: 69) (MGSSHHHHHHSSGENLY)FQGSGSGDDEDIDRVLEELRRITEELDRITKDLERLTQELRRNPSVDALVKHNNAI VRHNEIIVEHNRIILEVLELLLRSIGSGSGDREEIKKVLDELREATERLERATEELRRLTEELKKNPAVEVLVRH NTIIVKHNKIIVDHNRIIVRVLELLEKTIGSGIHGNVYITADKQKNGIKANFGLNSNVEDGSVQLADHYQQNTPI GDGPVLLPDNHYLSTQSALSKDPNEKRDHMVLLEFVTAAGITLGMDELYKGGTGGSMVSKGEELFTGVVPILVEL DGDVNGHKFSVRGEGEGDATNGKLTLKFISTTGKLPVPWPTLVTTLSWGVQSFARYPDHMKQHDFFKSAMPEGYV QERTIFFKDDGTYKTRAEVKFEGDTLVNRIELKGIDFKEDGNILGHKLEYGSGDKYEIRKVLKELKDITEELRNM TKNLTDLTEELKRNPSVEILVKHNILIVEHNKIIVEHNRIIVDVLELIRKAIMVSKGEELFTGVVPILVELDGDV NGHKFSVSGEGEGDATYGKLTLKFISTTGKLPVPWPTLVTTLTYGVQMFARYPDHMKQHDFFKSAMPEGYVQERT IFFKDDGNYKTRAEVKFEGDTLVNRIELKGIDFKEDGNILGHKLEYNYNSHNVYITADKQKNGIKANFKIRHNIE DGGVQLADHYQQNTPIGDGPVLLPDNHYLSTQSKLSKDPNEKRDHMVLLEFVTAAGITLGMDELYK pH-reponsive cpFP pH sensor with optimized linker, with C-terminal cfSGFP2. This embodiment shows pH-responsive fluorescence intensity modulation due to fused helical bundle pH-responsive conformational switching that is allosterically coupled to chromophore environment. (SEQ ID NO: 70) FQGSGSGDDEDIDRVLEELRRITEELDRITKDLERLTQELRRNPSVDALVKHNNAIVRHNEIIVEHNRIILEVLE LLLRSIGSGSGDREEIKKVLDELREATERLERATEELRRLTEELKKNPAVEVLVRHNTIIVKHNKIIVDHNRIIV RVLELLEKTIGSGIHGNVYITADKQKNGIKANFGLNSNVEDGSVQLADHYQQNTPIGDGPVLLPDNHYLSTQSAL SKDPNEKRDHMVLLEFVTAAGITLGMDELYKGGTGGSMVSKGEELFTGVVPILVELDGDVNGHKFSVRGEGEGDA TNGKLTLKFISTTGKLPVPWPTLVTTLSWGVQSFARYPDHMKQHDFFKSAMPEGYVQERTIFFKDDGTYKTRAEV KFEGDTLVNRIELKGIDFKEDGNILGHKLEYGSGDKYEIRKVLKELKDITEELRNMTKNLTDLTEELKRNPSVEI LVKHNILIVEHNKIIVEHNRIIVDVLELIRKAIMVSKGEELFTGVVPILVELDGDVNGHKFSVSGEGEGDATYGK LTLKFISTTGKLPVPWPTLVTTLTYGVQMFARYPDHMKQHDFFKSAMPEGYVQERTIFFKDDGNYKTRAEVKFEG DTLVNRIELKGIDFKEDGNILGHKLEYNYNSHNVYITADKQKNGIKANFKIRHNIEDGGVQLADHYQQNTPIGDG PVLLPDNHYLSTQSKLSKDPNEKRDHMVLLEFVTAAGITLGMDELYK pH-responsive cpFP pH sensor with optimized linker using heterodimer ZCON133, with C-terminal cfSGFP2. This embodiment shows pH-responsive fluorescence intensity modulation due to fused helical bundle pH-responsive conformational switching that is allosterically coupled to chromophore environment. (SEQ ID NO: 71) (MGSSHHHHHHSSGENLY)FQGSGSGSDKEYKLDRILRRLDELIKQLSRILEEIERLVDELEREPLDDKEVQDVT ERIVELIDEHLELLKEYIKLLEEYIKTTKGSGTHGNVYITADKQKNGIKANFGLNSNVEDGSVQLADHYQQNTPI GDGPVLLPDNHYLSTQSALSKDPNEKRDHMVLLEFVTAAGITLGMDELYKGGTGGSMVSKGEELFTGVVPILVEL DGDVNGHKFSVRGEGEGDATNGKLTLKFISTTGKLPVPWPTLVTTLSWGVQSFARYPDHMKQHDFFKSAMPEGYV QERTIFFKDDGTYKTRAEVKFEGDTLVNRIELKGIDFKEDGNILGHKLEYGSGSPSKEYQEKSAERQKELLHEYE KLVRHLRELVEKLQRRELDKEEVLRRLVEILERLKDLHKKIEDAHRKNEEAHKENKMVSKGEELFTGVVPILVEL DGDVNGHKFSVSGEGEGDATYGKLTLKFISTTGKLPVPWPTLVTTLTYGVQMFARYPDHMKQHDFFKSAMPEGYV QERTIFFKDDGNYKTRAEVKFEGDTLVNRIELKGIDFKEDGNILGHKLEYNYNSHNVYITADKQKNGIKANFKIR HNIEDGGVQLADHYQQNTPIGDGPVLLPDNHYLSTQSKLSKDPNEKRDHMVLLEFVTAAGITLGMDELYK pH-responsive cpFP pH sensor with optimized linker using heterodimer ZCON133, with C-terminal cfSGFP2. This embodiment shows pH-responsive fluorescence intensity modulation due to fused helical bundle pH-responsive conformational switching that is allosterically coupled to chromophore environment. (SEQ ID NO: 72) FQGSGSGSDKEYKLDRILRRLDELIKQLSRILEEIERLVDELEREPLDDKEVQDVTERIVELIDEHLELLKEYIK LLEEYIKTTKGSGTHGNVYITADKQKNGIKANFGLNSNVEDGSVQLADHYQQNTPIGDGPVLLPDNHYLSTQSAL SKDPNEKRDHMVLLEFVTAAGITLGMDELYKGGTGGSMVSKGEELFTGVVPILVELDGDVNGHKFSVRGEGEGDA TNGKLTLKFISTTGKLPVPWPTLVTTLSWGVQSFARYPDHMKQHDFFKSAMPEGYVQERTIFFKDDGTYKTRAEV KFEGDTLVNRIELKGIDFKEDGNILGHKLEYGSGSPSKEYQEKSAERQKELLHEYEKLVRHLRELVEKLQRRELD KEEVLRRLVEILERLKDLHKKIEDAHRKNEEAHKENKMVSKGEELFTGVVPILVELDGDVNGHKFSVSGEGEGDA TYGKLTLKFISTTGKLPVPWPTLVTTLTYGVQMFARYPDHMKQHDFFKSAMPEGYVQERTIFFKDDGNYKTRAEV KFEGDTLVNRIELKGIDFKEDGNILGHKLEYNYNSHNVYITADKQKNGIKANFKIRHNIEDGGVQLADHYQQNTP IGDGPVLLPDNHYLSTQSKLSKDPNEKRDHMVLLEFVTAAGITLGMDELYK pH-responsive cpFP pH sensor with optimized linker using heterodimer ZCON133 with subunits in reverse order in primary sequence, with C-terminal cfSGFP2. This embodiment shows pH-responsive fluorescence intensity modulation due to fused helical bundle pH-responsive conformational switching that is allosterically coupled to chromophore environment. (SEQ ID NO: 73) (MGSSHHHHHHSSGENLY)FQGSGSGSPSKEYQEKSAERQKELLHEYEKLVRHLRELVEKLQRRELDKEEVLRRL VEILERLKDLHKKIEDAHRKNEEAHKENKGSGIHGNVYITADKQKNGIKANFGLNSNVEDGSVQLADHYQQNTPI GDGPVLLPDNHYLSTQSALSKDPNEKRDHMVLLEFVTAAGITLGMDELYKGGTGGSMVSKGEELFTGVVPILVEL DGDVNGHKFSVRGEGEGDATNGKLTLKFISTTGKLPVPWPTLVTTLSWGVQSFARYPDHMKQHDFFKSAMPEGYV QERTIFFKDDGTYKTRAEVKFEGDTLVNRIELKGIDFKEDGNILGHKLEYGSGSDKEYKLDRILRRLDELIKQLS RILEEIERLVDELEREPLDDKEVQDVIERIVELIDEHLELLKEYIKLLEEYIKTTKMVSKGEELFTGVVPILVEL DGDVNGHKFSVSGEGEGDATYGKLTLKFISTTGKLPVPWPTLVTTLTYGVQMFARYPDHMKQHDFFKSAMPEGYV QERTIFFKDDGNYKTRAEVKFEGDTLVNRIELKGIDFKEDGNILGHKLEYNYNSHNVYITADKQKNGIKANFKIR HNIEDGGVQLADHYQQNTPIGDGPVLLPDNHYLSTQSKLSKDPNEKRDHMVLLEFVTAAGITLGMDELYK pH-responsive cpFP pH sensor with optimized linker heterodimer ZCON133 with subunits in reverse order in primary sequence, with C-terminal cfSGFP2. This embodiment shows pH-responsive fluorescence intensity modulation due to fused helical bundle pH-responsive conformational switching that is allosterically coupled to chromophore environment. (SEQ ID NO: 74) FQGSGSGSPSKEYQEKSAERQKELLHEYEKLVRHLRELVEKLQRRELDKEEVLRRLVEILERLKDLHKKIEDAHR KNEEAHKENKGSGIHGNVYITADKQKNGIKANFGLNSNVEDGSVQLADHYQQNTPIGDGPVLLPDNHYLSTQSAL SKDPNEKRDHMVLLEFVTAAGITLGMDELYKGGTGGSMVSKGEELFTGVVPILVELDGDVNGHKFSVRGEGEGDA TNGKLTLKFISTTGKLPVPWPTLVTTLSWGVQSFARYPDHMKQHDFFKSAMPEGYVQERTIFFKDDGTYKTRAEV KFEGDTLVNRIELKGIDFKEDGNILGHKLEYGSGSDKEYKLDRILRRLDELIKQLSRILEEIERLVDELEREPLD DKEVQDVIERIVELIDEHLELLKEYIKLLEEYIKTTKMVSKGEELFTGVVPILVELDGDVNGHKFSVSGEGEGDA TYGKLTLKFISTTGKLPVPWPTLVTTLTYGVQMFARYPDHMKQHDFFKSAMPEGYVQERTIFFKDDGNYKTRAEV KFEGDTLVNRIELKGIDFKEDGNILGHKLEYNYNSHNVYITADKQKNGIKANFKIRHNIEDGGVQLADHYQQNTP IGDGPVLLPDNHYLSTQSKLSKDPNEKRDHMVLLEFVTAAGITLGMDELYK Examples
Tuning of pH Set Point and Cooperativity
Tuning pH Set Point (FIG. 3C-D Top)
Tuning Cooperativity (FIG. 3C-D Bottom)
Context-Dependence
Conclusions
REFERENCES
Materials and Methods
Computational Design Methods
Protein Expression and Purification
Buffets for Varying pH
Circular Dichroism (CD)
Native Mass Spectrometry
Small-Angle X-Ray Scattering (SAXS)
X-Ray Crystallography
X-Ray Data Collection and Structure Determination
Liposomes Preparation and Characterization
Fluorescence Dequenching Liposome Leakage Assay
Cryo-EM Specimen Preparation and Imaging
Cell Culture, Plating, and Transfection
Live Cell Experiments
Confocal Microscopy
Visualization and Figure
Theoretical Modeling and Fitting to Native Mass Spectrometry Data
X-ray crystallography data collection and refinement statistics. pRO-2.3 (6MSQ) pRO-2.5 (6MSR) Wavelength 0.9999 1 Resolution range 43.79-1.28 (1.326-1.28) 28.7-1.55 (1.605-1.55) Space group P 63 C 121 Unit cell 50.5663 50.5663 130.753 90 57.618 33.281 114.455 90 90 120 99.557 90 Total reflections 429120 (15514) 142682 (14317) Unique reflections 48463 (4882) 31393 (3139) Multiplicity 8.8 (6.4) 4.5 (4.6) Completeness (%) 99.8 (100.0) 95.36 (89.40) Mean I/sigma(I) 7.83 (0.5) 9.97 (1.49) Wilson B-factor 16.44 24.47 R-merge 0.117 (3.554) 0.07484 (1.027) R-meas 0.125 (3.880) 0.08526 (1.164) R-pim 0.042 (1.536) 0.04017 (0.5402) CC1/2 0.998 (0.428) 0.995 (0.728) CC* 1 (0.701) 0.999 (0.918) Reflections used 48462 (2888) 31393 (2808) in refinement Reflections 1657 (115) 1407 (129) used for R-free R-work 0.1726 (0.5196) 0.2424 (0.3852) R-free 0.1944 (0.5228) 0.2639 (0.3803) CC(work) 0.961 (0.276) 0.954 (0.770) CC(free) 0.965 (0.253) 0.966 (0.803) Number of 1423 1916 non-hydrogen atoms macromolecules 1172 1755 solvent 251 161 Protein residues 152 228 RMS(bonds) 0.007 0.005 RMS(angles) 0.73 0.83 Ramachandran 100.00 100.00 favored (%) Ramachandran 0.00 0.00 allowed (%) Ramachandran 0.00 0.00 outliers (%) Rotamer 0.00 2.40 outliers (%) Clashscore 0.84 3.16 Average B-factor 26.70 43.57 macromolecules 24.47 43.33 solvent 37.08 46.19 Number or TLS 6 groups Statistics for the highest-resolution shell are shown in parentheses. SAXS data collection and analysis. Perod Concent I(0) (cm−1) Rg(Å) I(0) (cm−1) Rg(Å) volume ration [from [from [from [from Dmax estimate Design name (mg ml−1) P(r)] P(r)] Guinier] Guinier] (Å) (Å3) Rc Ps pRO-2 5.0 1570 21.66 1670 21.97 72 50287 14.2 3.4 pRO-2-noHis 3.8 1070 21.54 1090 21.36 70 46442 13.7 3.5 REFERENCES
X1-X2-X3-X4-X5-X6-X7-X8-X9-X10-X11-X12-X13-X14-X15-X16-X17, wherein:
X6-X7-X8-X9-X10-X11-X12, wherein; (I)
X4-X5-X6-X7-X8-X9-X10-X11-X12-X13-X14, wherein: (II)
X2-X3-X4-X5-X6-X7-X8-X9-X10-X11-X12-X13-X14-X15-X16, wherein; (III)