DATABASE REDISTRIBUTION UTILIZING VIRTUAL PARTITIONS
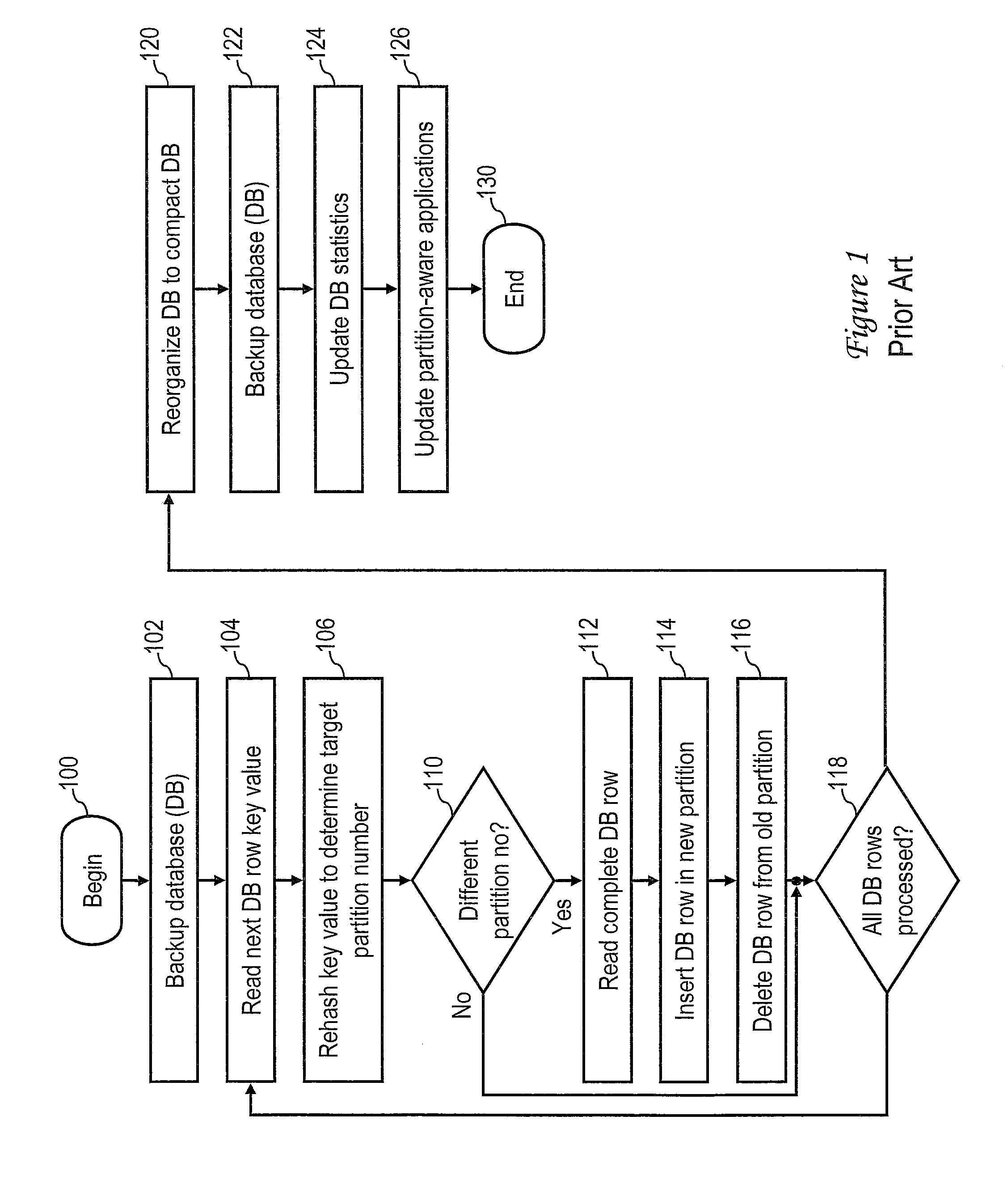
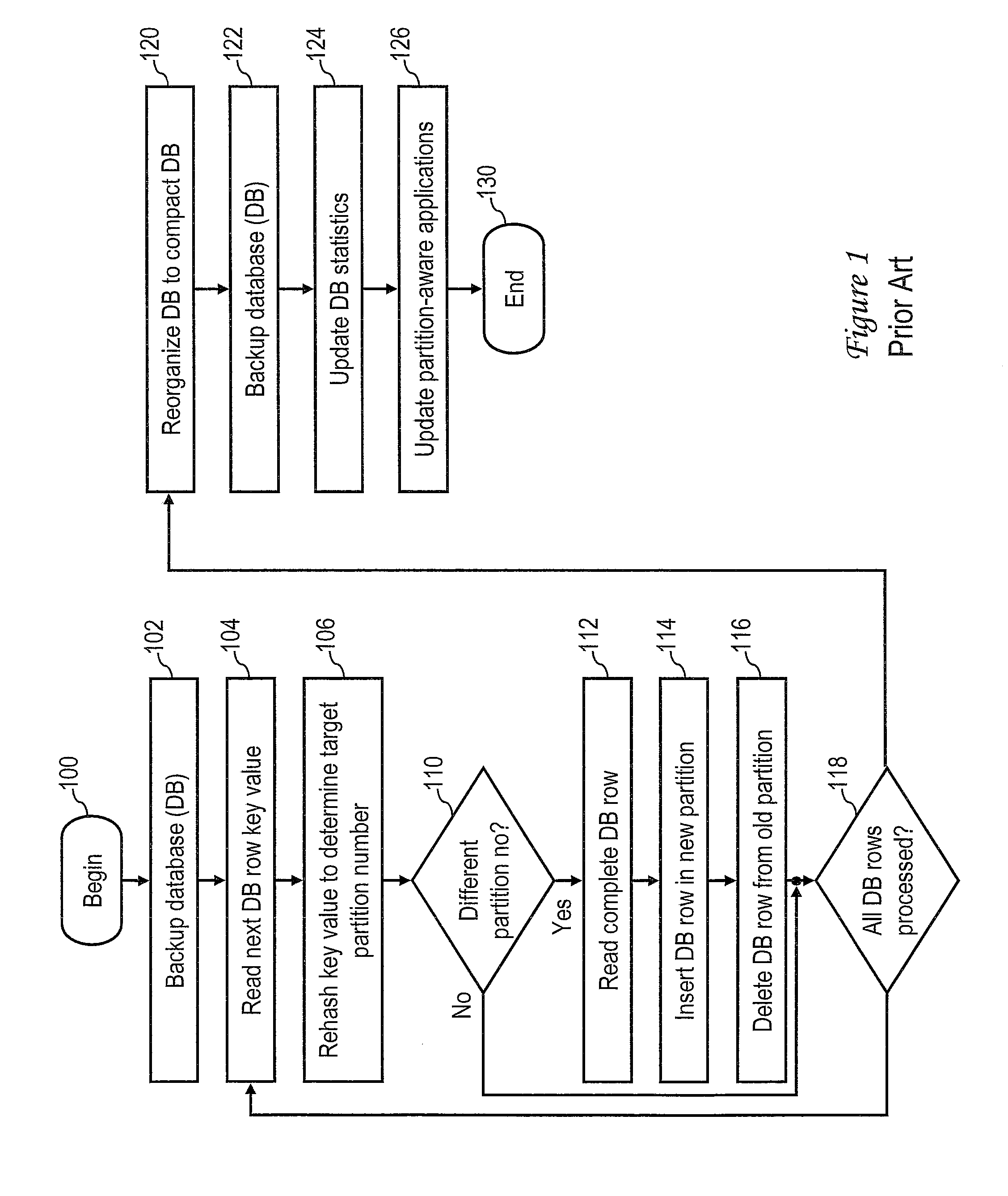
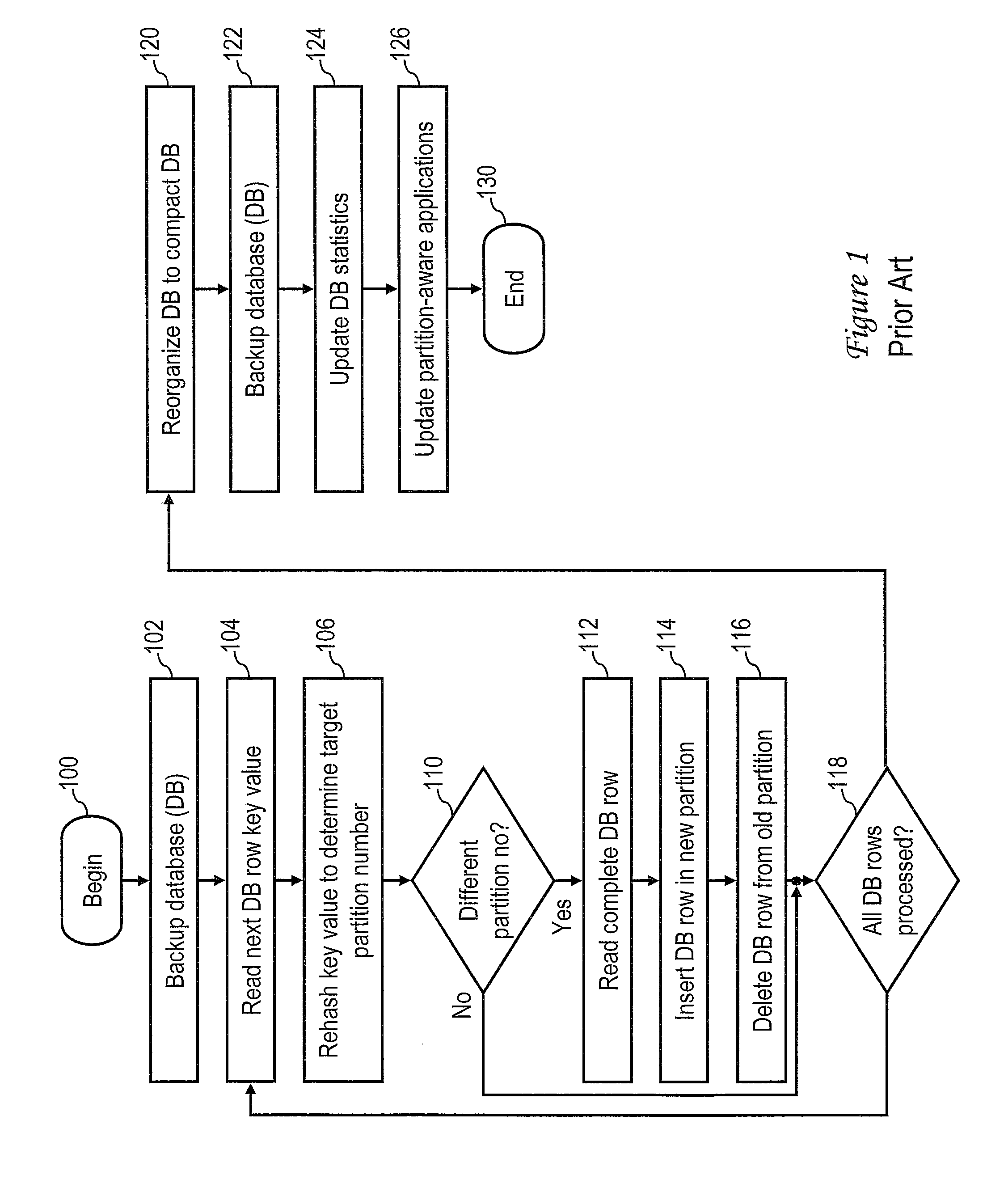
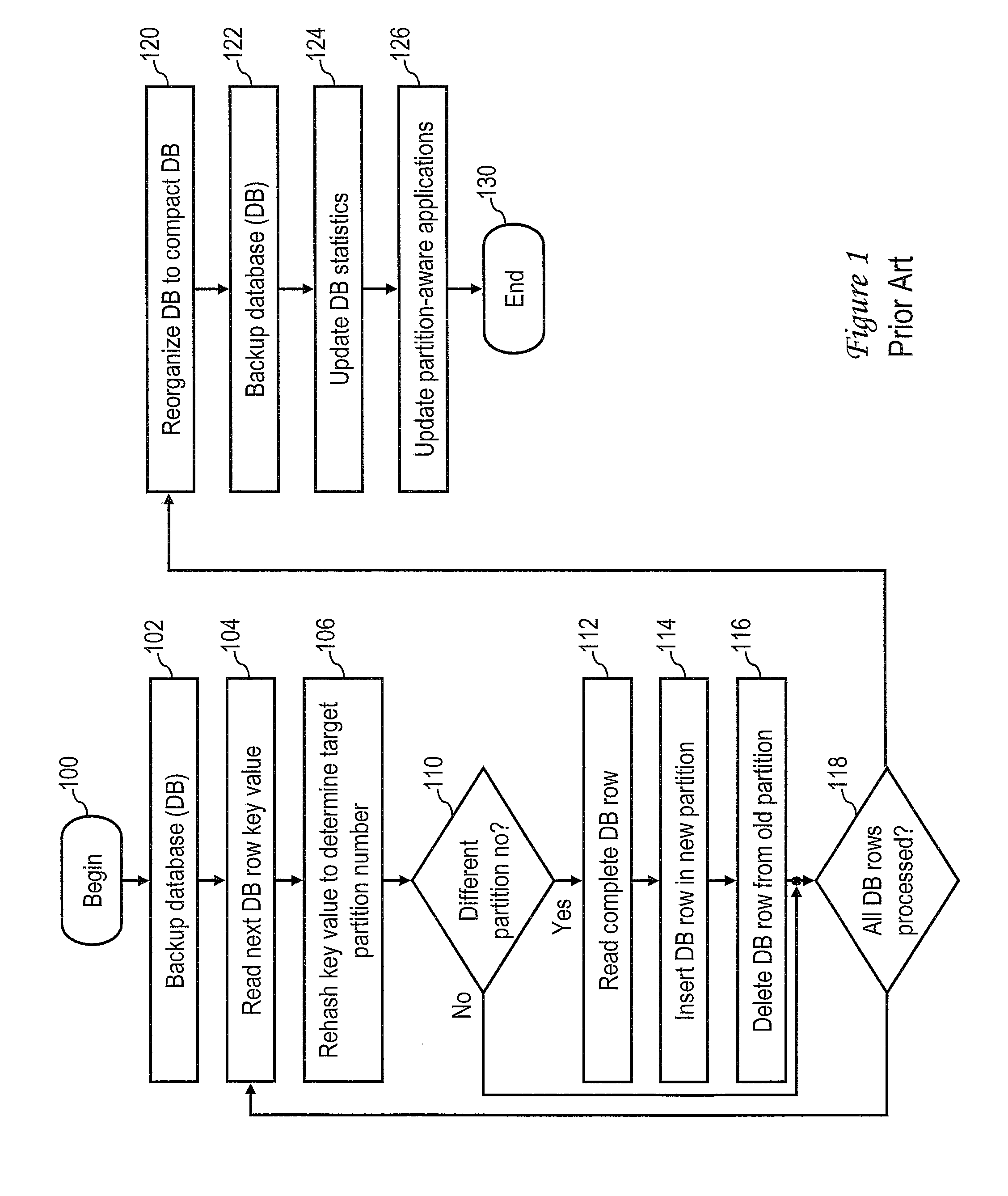
This application is a continuation of U.S. patent application Ser. No. 12/961,544 entitled “DATABASE REDISTRIBUTION UTILIZING VIRTUAL PARTITIONS” by Saurabh Jain et al. filed Dec. 7, 2010, the disclosure of which is hereby incorporated herein by reference in its entirety for all purposes. 1. Technical Field The present invention relates in general to data processing, and in particular, to redistribution of a partitioned database. 2. Description of the Related Art In computing environments in which a large volume of data is stored, the data are commonly managed by a relational database management system (RDBMS), which can be utilized to instantiate one or more databases for storing, accessing and manipulating the data. Each databases includes one or more table spaces, which in turn store table data in accordance with the relational data model. As implied by tabular organization, the table data is logically arranged in rows and columns, with each table row having an associated row key. To provide enhanced manageability, performance and/or availability, a relational database is commonly partitioned into multiple logical or physical partitions (hereinafter, simply referred to as a “partition” unless a more definite meaning is required), each having its own data, indexes, configuration files, and transaction logs. Table data of any given table can be located in one or more of the partitions, with the partition on which the table data resides typically being determined by a hash function. Because data is distributed across database partitions, the power of multiple processors, possibly on multiple computers, can be harnessed in tandem to store, retrieve, process and manage the data in the database. Enterprises that manage large data volumes, such as online transaction processing (OLTP) systems, data warehousing enterprises, insurance and financial companies, etc., are frequently required to expand their data storage and processing capacities as the volume of stored data grows. For example, an enterprise may add one or more additional servers and their associated storage nodes to the existing information technology (IT) infrastructure of the enterprise in order to handle an increased volume of data while avoiding a degradation in query response times. To make use of the additional servers, the RDBMS must redistribute and reorganize one or more database instances so that the database instance(s) reside not only on the storage nodes of the existing servers, but also on the storage nodes of the newly installed servers. A conventional process by which a RDBMS redistributes and reorganizes a database in accordance with the prior art is depicted in The conventional process of redistributing and reorganizing a database begins at block 100 and thereafter proceeds to block 102, which depicts the RDBMS making a backup of the entire database that is to be redistributed. Depending upon the size of the database, making a backup of the database can consume significant processing time (e.g., days or weeks). The process then enters an iterative loop including blocks 104-118 in which the database is redistributed row by row across the existing and new storage nodes. The redistribution begins at block 104, which depicts the RDBMS reading a key value of the next database row to be processed. The RDBMS then rehashes the key value of the database row to determine a target partition number on which the database row will reside following the redistribution (block 106). At block 110, the RDBMS determines whether the target partition number is the same as the existing partition number, meaning that the database row will not be moved. If the target partition number matches the existing partition number, the process passes to block 118, which is described below. If, however, the target partition number does not match the existing partition number, the process proceeds to blocks 112-116. At blocks 112-116, the RDBMS reads the complete database row from the preexisting storage node, inserting the database row in a new partition on a newly added storage node, and then deleting the database row from the preexisting storage node. Thereafter, at block 118, the RDBMS determines whether or not all rows of the database have been processed. If not, the process returns to block 104, which has been described. If, however, RDBMS determines at block 118 that all rows of the database have been processed, the process proceeds to block 120. As will be appreciated, the movement of selected database rows from the preexisting storage nodes to the newly installed storage nodes via the redistribution depicted at block 104-118 leaves the preexisting storage nodes sparsely populated and thus inefficiently utilized. Consequently, at block 120 the RDBMS reorganizes the database rows in the preexisting storage nodes to return the database to a compact storage organization. If the reorganization completes successfully, the RDBMS then makes a second backup of the entire database at block 122. In addition, as depicted at block 124, the RDBMS executes a utility to gather statistics regarding the database, to recharacterize the table spaces, indexes, and partitions, and to record these statistics in a catalog. Finally, at block 126, the RDBMS notifies any partition-aware applications (e.g., Microsoft® Internet Information Services (IIS)) of the reorganization of the database across the newly added storage nodes. Thereafter, the conventional process for redistributing and reorganizing the database ends at block 130. In the example depicted in In some embodiments, a partitioned database is stored in a plurality of logical or physical partitions on at least a logical or physical first data storage node, and a subset of a first partition among the plurality of logical partitions is configured as a virtual partition. An input indicating an allocation of a second physical data storage node to store the partitioned database is received. A second partition is configured on the second data storage node. In response to the input, the partitioned database is redistributed over the first and second data storage nodes by moving data within the virtual partition on the first partition to the second partition. With reference now to the figures and with particular reference to The communication between devices 302 Still referring to In the depicted embodiment, data storage 330 stores an operating system (OS) 332 that manages the hardware resources of server 312 In various embodiments, database manager 340 and/or OS 332 may include code to support communication of server 312 It should be appreciated that the contents of data storage 330 can be localized on server 312 It will be appreciated upon review of the foregoing description that the form in which data processing enterprise 312 is realized can vary between embodiments based upon one or more factors, for example, the type of organization, the size of database 350, the number of devices 302 In accordance with the present disclosure, database manager 340 assigns a subset of data blocks B0-B15 to virtual partitions. For example, database manager 340 may assign each of data blocks B8-B15 to a respective one of eight virtual partitions numbered VP8-VP15. In various scenarios, each virtual partition can include one or more data blocks, which preferably all reside on a common logical partition. As discussed further below with reference to With reference now to In an exemplary embodiment, each configuration entry 500 of partition configuration data structure 352 comprises a number of fields, including a node number field 502, a hostname field 504, a logical partition number field 506, and a virtual partition flag 508. Node number field 502 specifies an integer number uniquely identifying a partition of database 350. In contrast to conventional partitioned databases that restrict node numbers to logical partitions, node number field 502 preferably contains a unique node number for each logical and virtual partition of database 350. Hostname field 504 identifies the TCP/IP hostname (e.g., “ServerA”) of the database partition identified in node number field 502. In addition, logical port field 506 specifies the logical port (e.g., logical partition) assigned to the database partition identified in node number field 502, and virtual partition flag 508 identifies whether or not the partition specified in node number field 502 is a virtual partition. It should be appreciated that configuration entries 500 may include one or more additional fields providing additional configuration information, such as a communication path to a logical partition and/or operating system-specific information. Given the exemplary embodiment of partition configuration data structure 352 depicted in With reference now to With reference now to The process depicted in The process proceeds from block 704 to block 710, which depicts database manager 340 determining whether or not an input has been received indicating that database 350 is to be redistributed over an expanded physical storage capacity. As will be appreciated, the expanded physical storage capacity available to store database 350 may become available through the addition of a server 312 to data processing enterprise 310, the addition of an additional data storage node 370 to SAN 360, and/or the reallocation of existing data storage node(s) of data processing enterprise 310 to store database 350. If database manager 340 does not detect an input indicating that database 350 is to be redistributed over an expanded physical storage capacity, the process remains at block 710. While the process remains at block 710, database manager 340 performs conventional database processing, including providing data responsive to structured query language (SQL) queries of database 350 and performing any requested management or configuration functions, etc., as is known in the art. In response to a determination by database manager 340 at block 710 that an input (e.g., a user command) has been received indicating that database 350 is to be redistributed over an expanded physical storage capacity, the process passes to block 712. Block 712 depicts database manager 340 establishing logical partitions on the new physical storage node(s) allocated to store database 350. The process then enters a loop including blocks 720-730 in which virtual partitions are redistributed from the preexisting logical partitions to the new logical partitions established at block 712. Referring first to block 720, database manager 340 determines, for example, by reference to partition configuration data structure 352, whether or not all virtual partitions of database 350 have been processed. In response to database manager 350 determining at block 720 that all virtual partitions of database 350 have been processed, the process proceeds from block 720 to block 740, which is described below. If, however, database manager 350 determines at block 720 that not all virtual partitions of database 350 have been processed, database manager 350 selects a virtual partition for processing, for example, the next virtual partition listed in partition configuration data structure 352 (block 722). At block 724, database manager 350 determines whether or not to move the virtual partition selected for processing, for example, by determining whether or not the virtual partition number matches a logical partition number assigned to one of the logical partitions established on the newly allocated storage node(s). In response to a determination not to move the currently selected virtual partition, the process returns to block 720, which has been described. If, however, database manager 350 determines at block 724 that the selected virtual partition is to be moved, the process passes to block 726. Block 726 depicts database manager 350 moving the data of the virtual partition using sequential access operations from the existing logical partition to the logical partition having a matching logical partition number. Database manager 350 then updates the metadata stored in association with the moved partition on the data storage node (block 728) and clears the virtual partition flag 508 of the associated configuration entry 500 in partition configuration data structure 352 (block 730). As a result, the moved partition is no longer a virtual partition and is converted into a data block of one of the logical partitions on the newly allocated data storage node. The process returns from block 730 to block 720, which depicts database manager 340 processing the next virtual partition, if any. In response to database manager 340 determining at block 720 that all virtual partitions have been processed, database manager 340 updates partition map 354 to reflect the modified relationship between hash values and logical and virtual partition numbers (block 740). Following block 740, the process depicted in The physical data storage capacity of data processing environment 310 available to house database 350 is then expanded to include an additional data storage node 800. As noted with respect to block 712, database manager 340 configures data storage node 800 with eight logical partitions numbered LP8-LP15. In addition, in accordance with blocks 720-730 of Assuming data storage node 800 resides on a server 312 having the hostname “ServerB,” database manager 340 updates partition configuration data structure 352 from the state summarized above in Table I to that given in Table III below. It should be noted by comparison of With reference to The process depicted in In response to a determination by database manager 340 at block 910 that an input has been received indicating that database 350 is to be redistributed over an expanded physical storage capacity, the process passes to block 912. Block 912 depicts database manager 340 establishing logical partitions on the new physical storage node(s) allocated to store database 350. The process then enters a loop including blocks 920-930 in which virtual partitions are backed up from the preexisting logical partitions established at block 912. Referring first to block 920, database manager 340 determines, for example, by reference to partition configuration data structure 352 whether or not all virtual partitions of database 350 have been processed. In response to database manager 350 determining at block 920 that all virtual partitions of database 350 have been processed, the process proceeds from block 920 to block 940, which is described below. If, however, database manager 350 determines at block 920 that not all virtual partitions of database 350 have been processed, database manager 350 selects a virtual partition for processing, for example, the next virtual partition listed in partition configuration data structure 352 (block 922). Next, database manager 350 makes a backup of the selected virtual partition, but preferably excludes from the backup the remainder of the logical partition hosting the virtual partition (block 926). Database manager 350 then clears the virtual partition flag 508 associated with the selected virtual partition in partition configuration data structure 352 (block 930). The process returns from block 930 to block 920, which depicts database manager 340 processing the next virtual partition, if any. In response to database manager 340 determining at block 920 that all virtual partitions of database 350 on the preexisting physical data storage node(s) have been processed, database manager 340 restores each of the virtual partitions from the backup made at block 926 to a respective logical partition of the newly allocated physical storage node(s) of data processing enterprise 310 (e.g., the logical partition having a logical partition number matching the virtual partition number of the backed up virtual partition). As a result, the moved partition is no longer a virtual partition and is converted into a data block on a logical partition of the newly allocated data storage node(s). Database manager 350 then updates the metadata stored in association with the restored partition on the data storage node (block 942) and deletes the moved partitions from the preexisting physical storage node(s) (block 944). Database manager 340 additionally updates partition map 354, if present, to reflect the modified relationship between hash values and logical and virtual partition numbers (block 946). Following block 946, the process depicted in The physical data storage capacity of data processing environment 310 allocated to house database 350 is then expanded to include an additional data storage node 800, on which database manager 340 configures eight logical partitions numbered LP8-LP15. In accordance with blocks 920-930 of As has been described, in at least some embodiments a partitioned database is stored in a plurality of logical or physical partitions on at least a logical or physical first data storage node, and a subset of a first partition among the plurality of logical partitions is configured as a virtual partition. An input indicating an allocation of a second physical data storage node to store the partitioned database is received. A second partition is configured on the second data storage node. In response to the input, the partitioned database is redistributed over the first and second data storage nodes by moving data within the virtual partition on the first partition to the second partition. While the present invention has been particularly shown as described with reference to one or more preferred embodiments, it will be understood by those skilled in the art that various changes in form and detail may be made therein without departing from the spirit and scope of the invention. For example, although aspects have been described with respect to a computer system executing program code that directs the functions of the present invention, it should be understood that present invention may alternatively be implemented as a program product including a tangible, non-transient data storage medium (e.g., an optical or magnetic disk or memory) storing program code that can be processed by a data processing system to perform the functions of the present invention. In some embodiments, a partitioned database is stored in a plurality of logical or physical partitions on at least a logical or physical first data storage node, and a subset of a first partition among the plurality of logical partitions is configured as a virtual partition. An input indicating an allocation of a second physical data storage node to store the partitioned database is received. A second partition is configured on the second data storage node. In response to the input, the partitioned database is redistributed over the first and second data storage nodes by moving data within the virtual partition on the first partition to the second partition. 1. A method of data processing, comprising:
storing a partitioned database in a plurality of partitions on at least a first data storage node of a data processing system; configuring a subset of a first partition among the plurality of partitions as a virtual partition; receiving an input indicating an allocation of a second data storage node to store the partitioned database; configuring a second partition of the partitioned database on the second data storage node; and in response to the input, redistributing the partitioned database over the first and second data storage nodes by moving data within the virtual partition on the first partition to the second partition. 2. The method of 3. The method of 4. The method of the method includes establishing a partition configuration data structure associating the virtual partition and the first partition; and the redistributing includes updating the partition configuration data structure to indicate that the data moved to the second partition does not reside in a virtual partition. 5. The method of the method includes establishing a partition map mapping data within the partitioned database to particular ones of the plurality of partitions and the virtual partition; and the redistributing includes updating the partition map to indicate that data moved to the second partition is not mapped to a virtual partition. 6. The method of creating a backup of the data within the virtual partition; restoring the data from the backup to the second partition. 7. The method of the data within the virtual partition is first data; prior to the redistributing, the first partition stores the first data and second data that is not within the virtual partition; and creating the backup comprises creating a backup including the first data and excluding the second data. BACKGROUND OF THE INVENTION
SUMMARY OF THE INVENTION
BRIEF DESCRIPTION OF THE DRAWINGS
DETAILED DESCRIPTION OF ILLUSTRATIVE EMBODIMENT
0 ServerA 0 — 1 ServerA 1 — 2 ServerA 2 — 3 ServerA 3 — 4 ServerA 4 — 5 ServerA 5 — 6 ServerA 6 — 7 ServerA 7 — 8 ServerA 0 V 9 ServerA 1 V 10 ServerA 2 V 11 ServerA 3 V 12 ServerA 4 V 13 ServerA 5 V 14 ServerA 6 V 15 ServerA 7 V 0 — 0 1 — 1 2 — 2 3 — 3 . . . . . . . . . 7 — 7 8 8 0 9 9 1 10 10 2 . . . . . . . . . 15 15 7 16 — 0 . . . . . . . . . 23 — 7 24 8 0 . . . . . . . . . 31 15 7 . . . . . . . . . 4095 — 7 0 ServerA 0 — 1 ServerA 1 — 2 ServerA 2 — 3 ServerA 3 — 4 ServerA 4 — 5 ServerA 5 — 6 ServerA 6 — 7 ServerA 7 — 8 ServerB 0 — 9 ServerB 1 — 10 ServerB 2 — 11 ServerB 3 — 12 ServerB 4 — 13 ServerB 5 — 14 ServerB 6 — 15 ServerB 7 —
In addition, database manager 350 updates partition map 354 from the state summarized above in Table II to that given in Table IV below.
0 — 0 1 — 1 2 — 2 3 — 3 . . . . . . . . . 7 — 7 8 — 0 9 — 1 10 — 2 . . . . . . . . . 15 — 7 16 — 0 . . . . . . . . . 23 — 7 24 — 0 . . . . . . . . . 31 — 7 . . . . . . . . . 4095 — 7