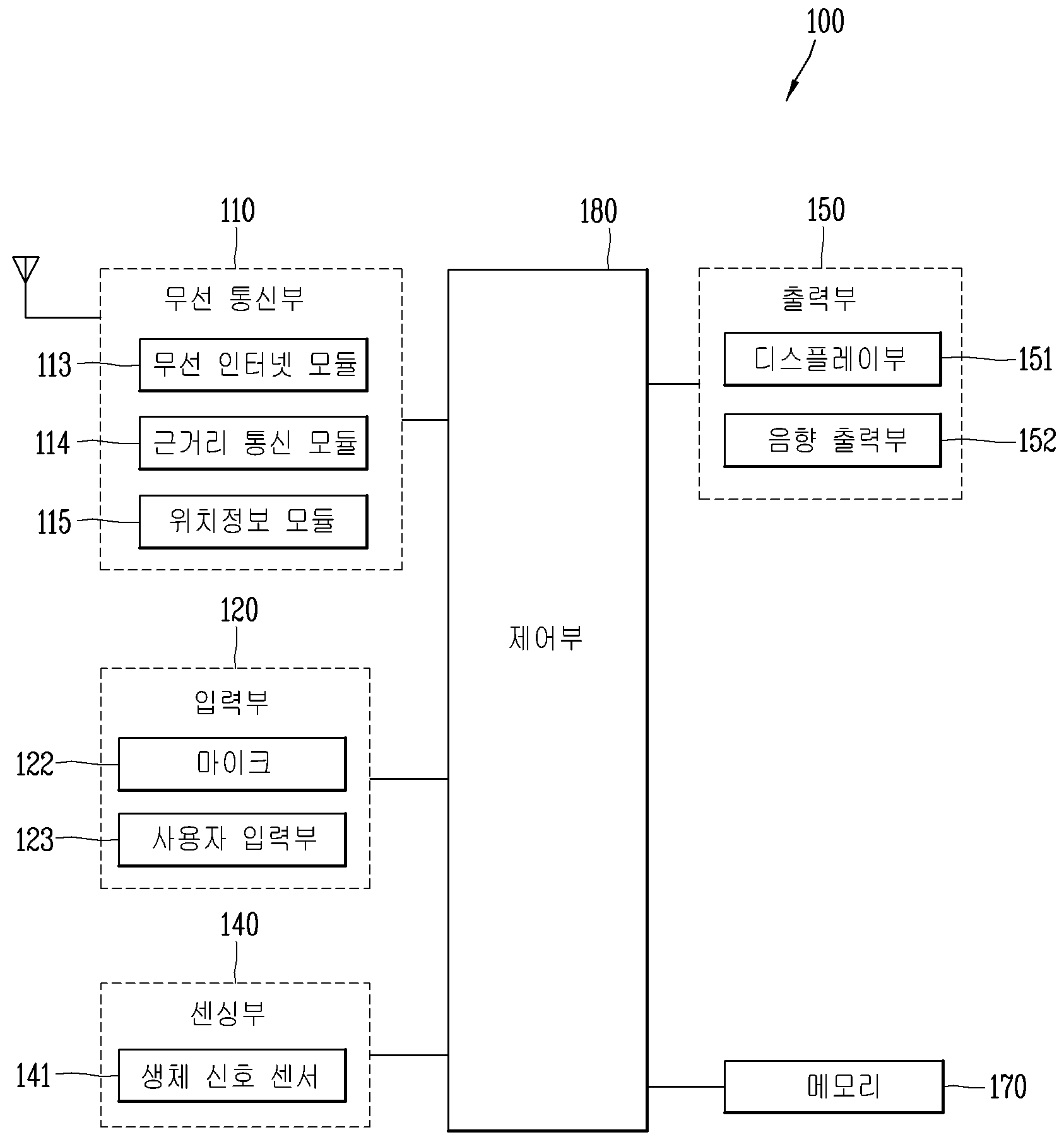
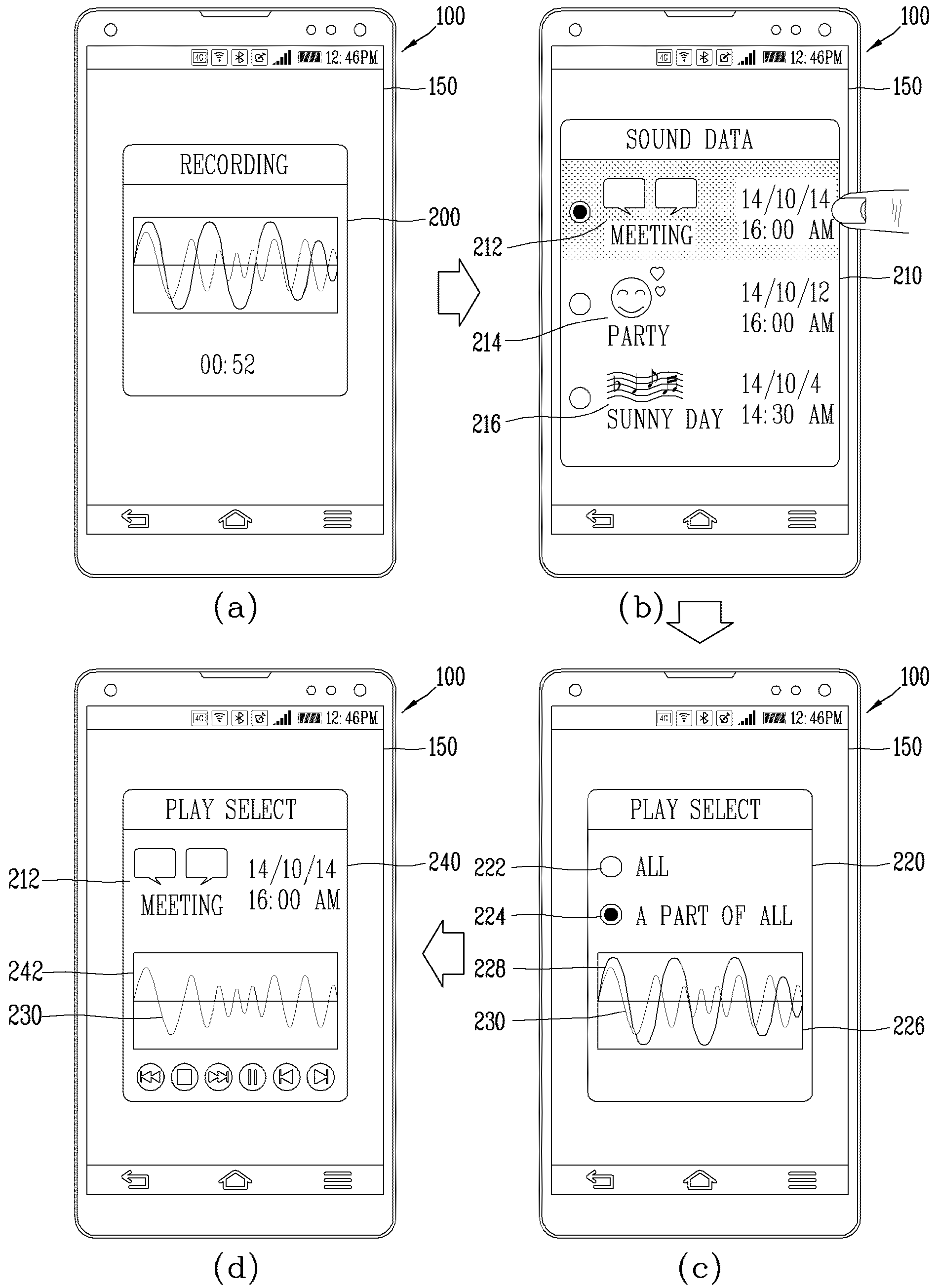
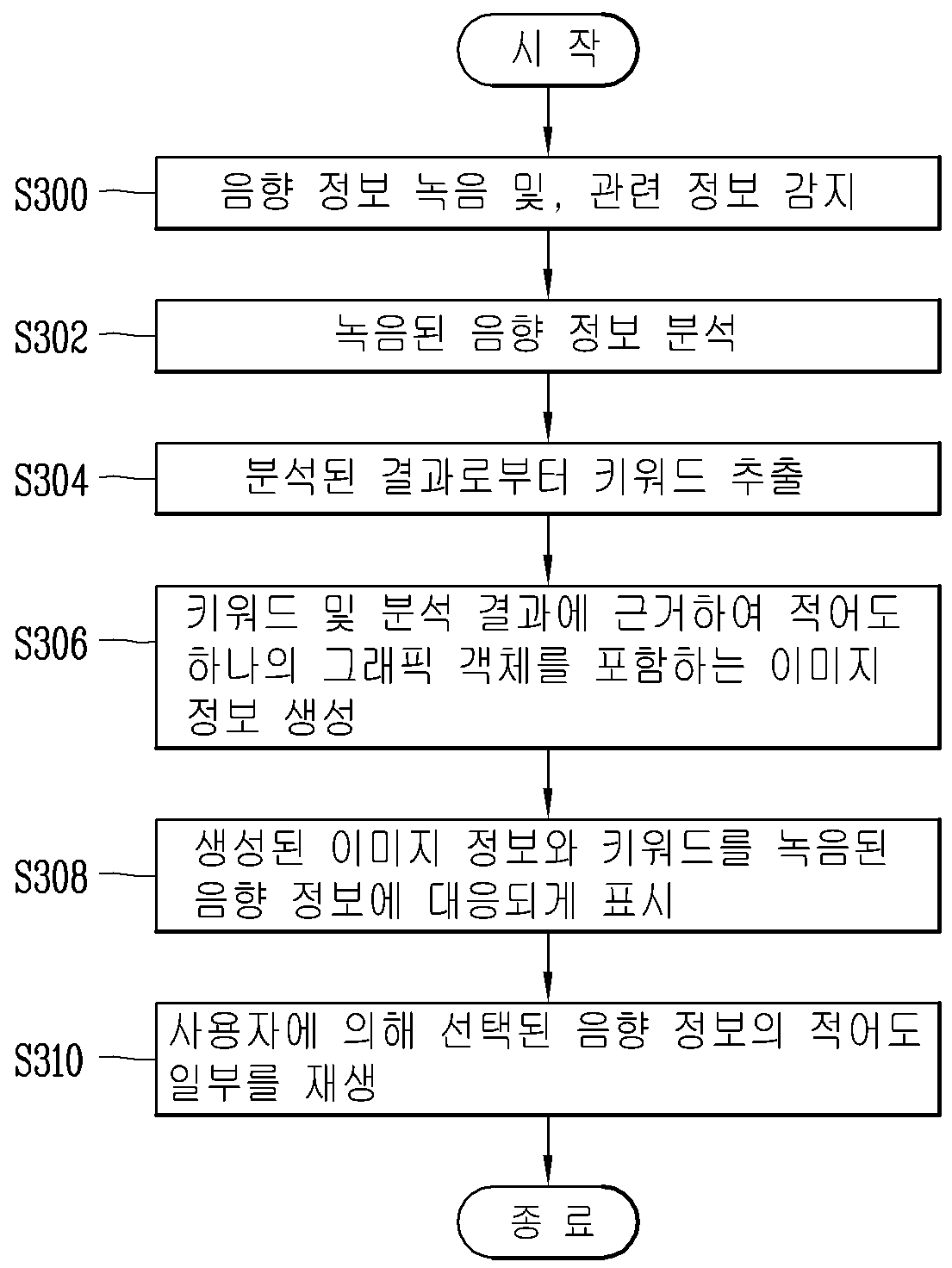
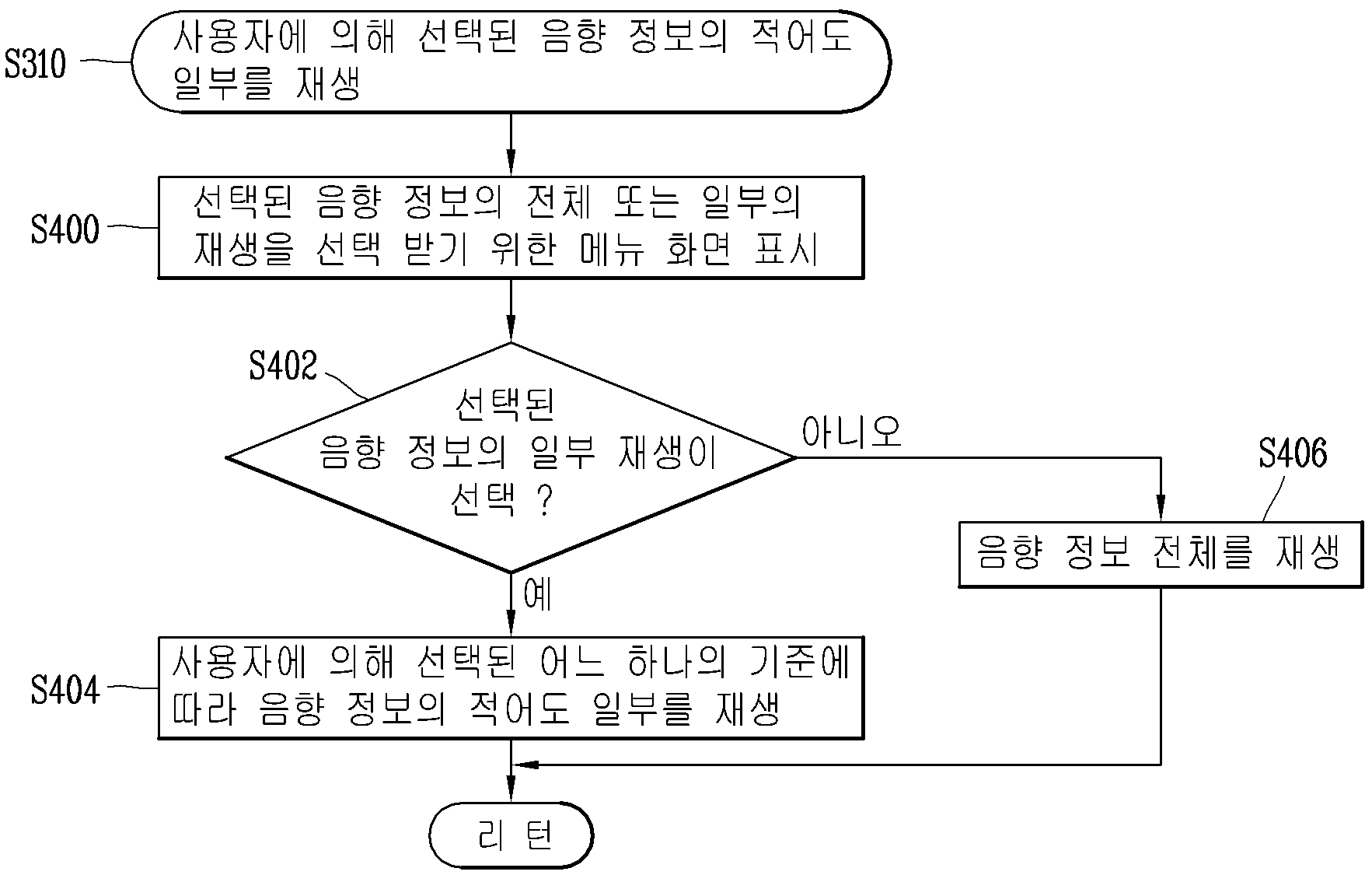
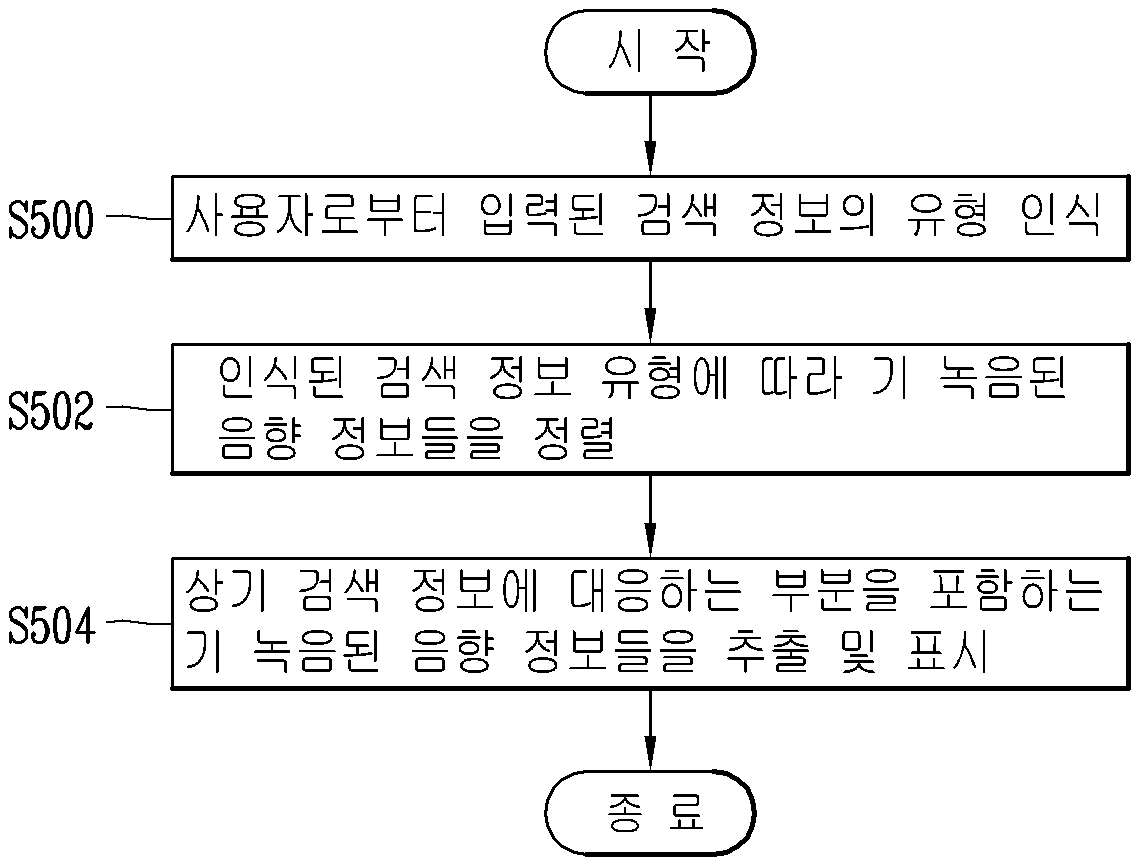
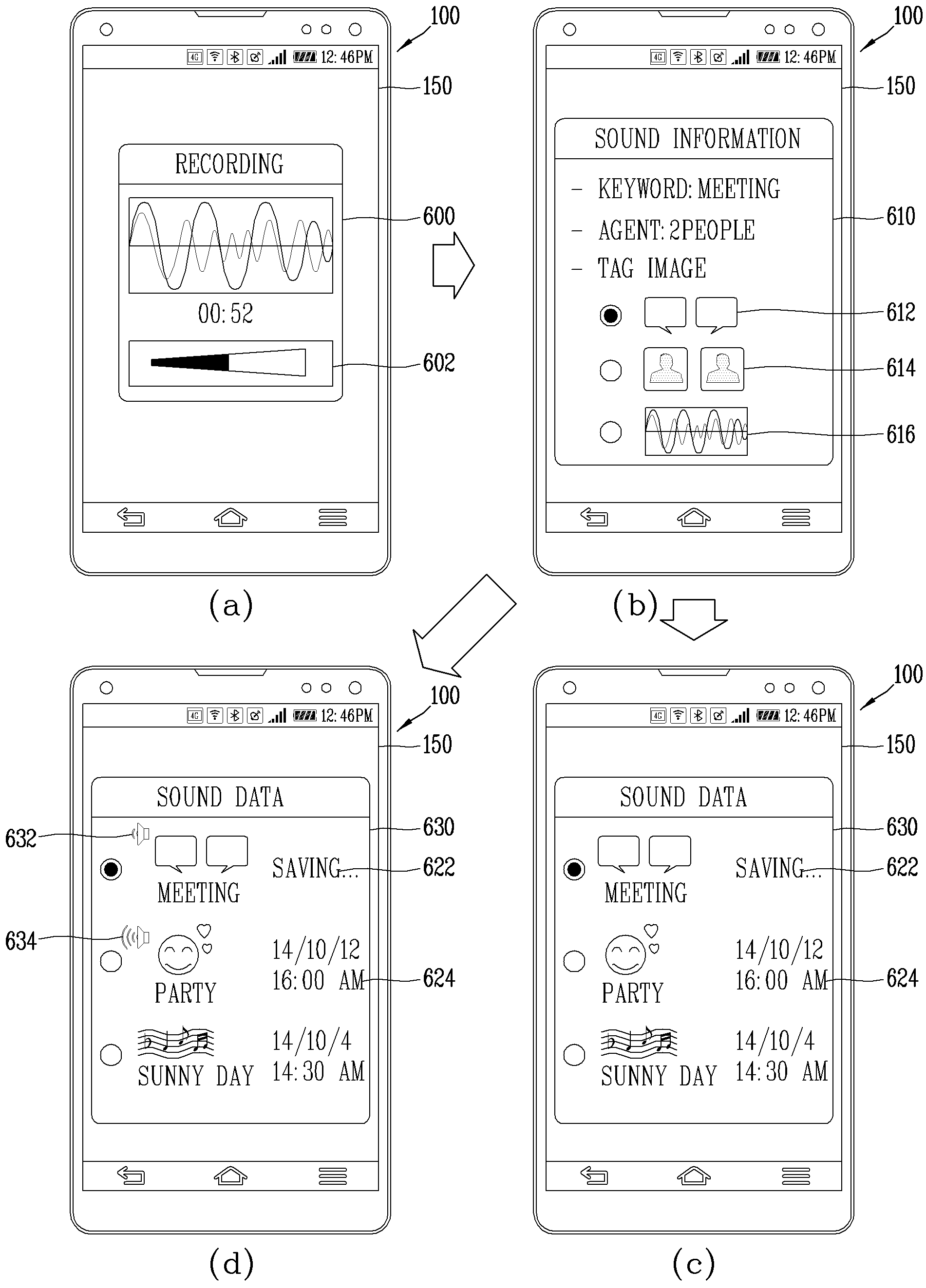
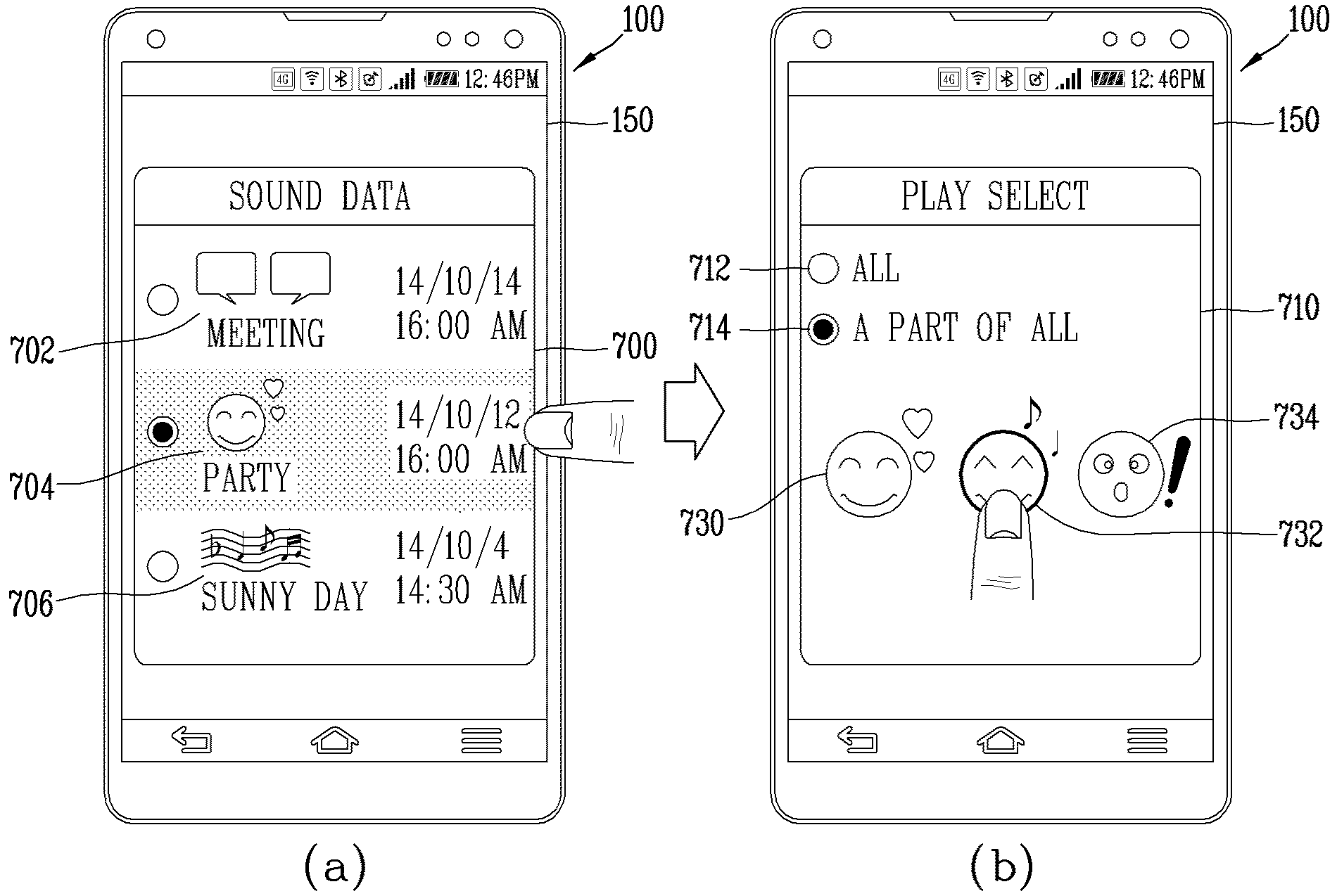
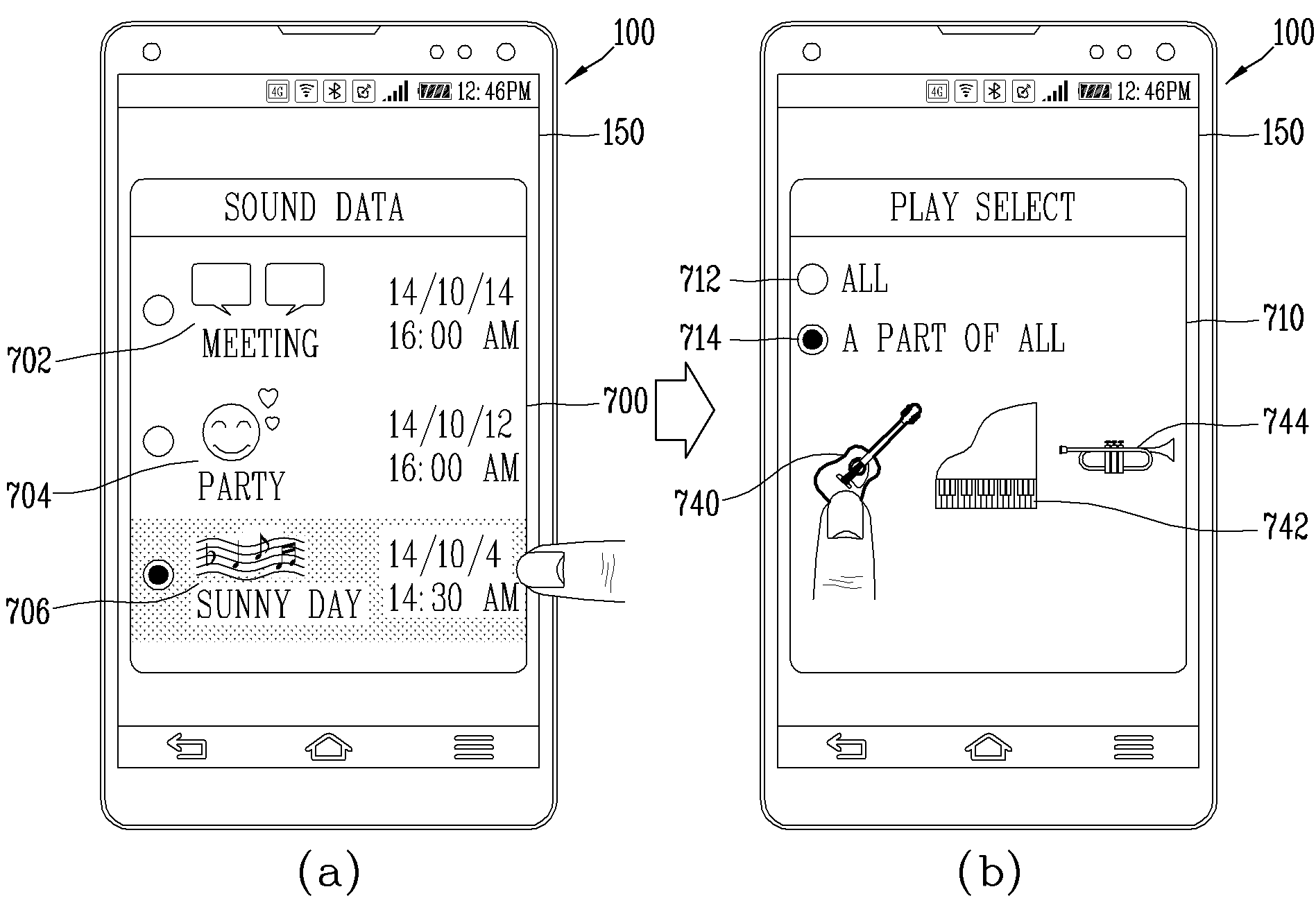
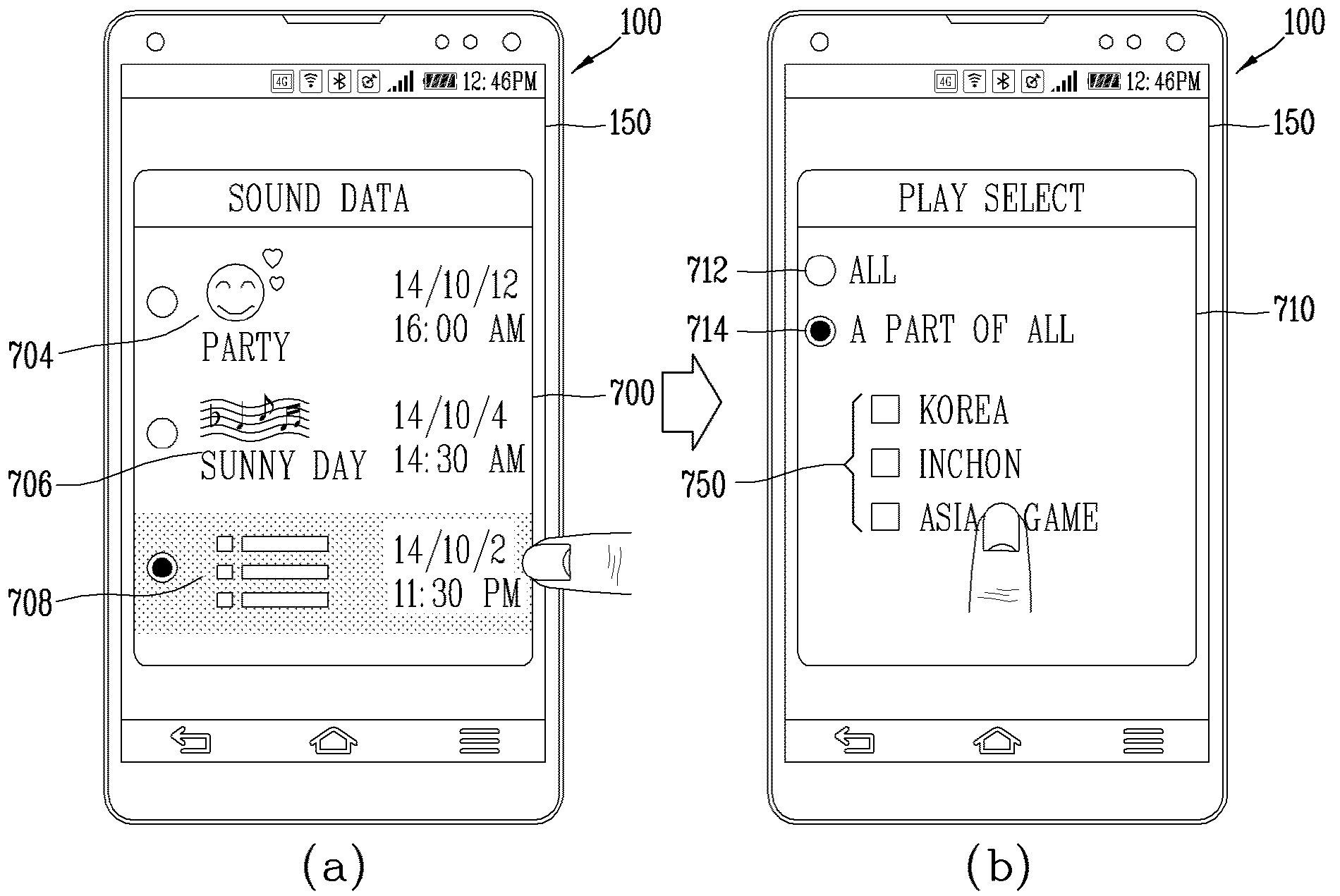
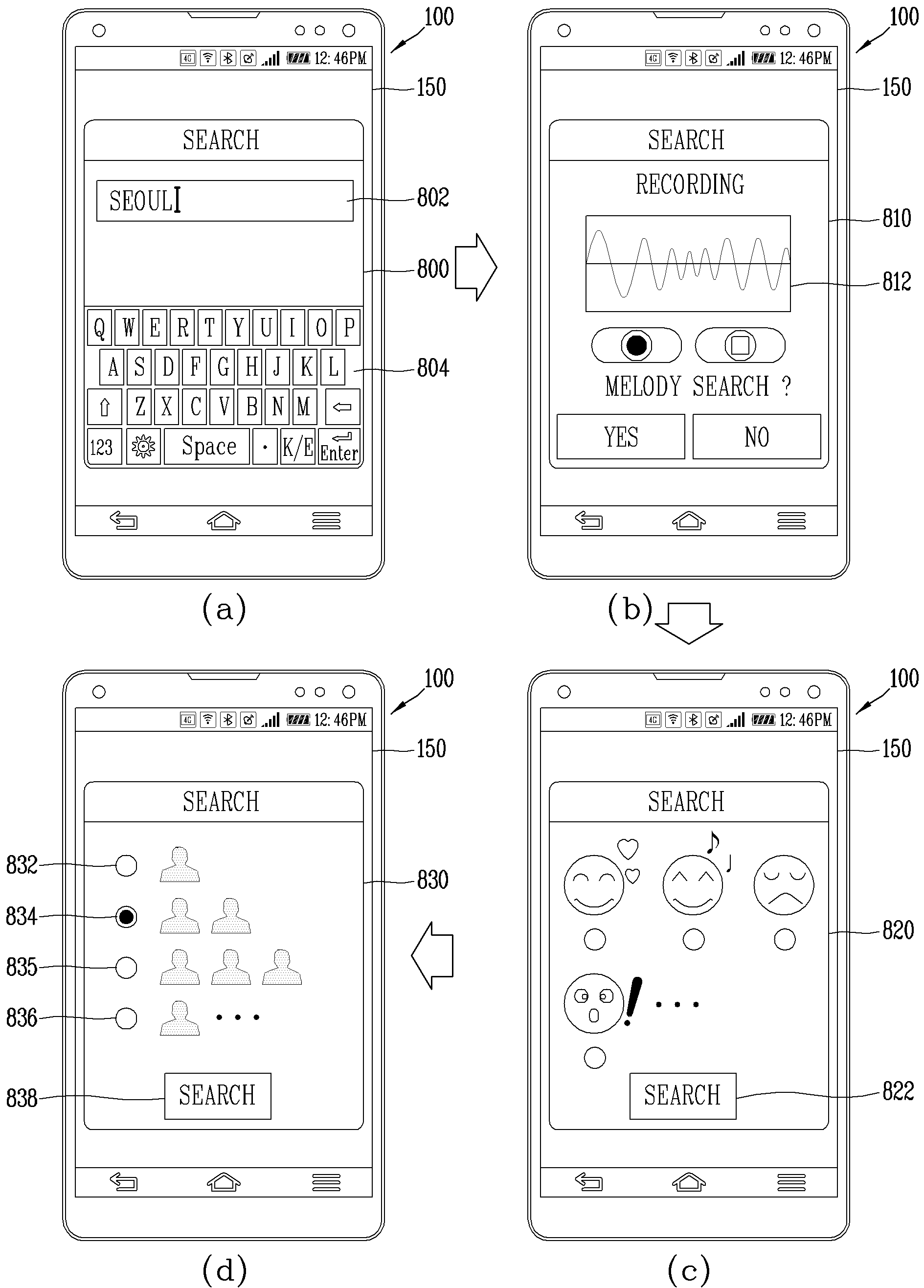
APPARATUS FOR RECORDING AUDIO INFORMATION AND METHOD FOR CONTROLLING SAME
본 발명은 음향 정보를 녹음 할 수 있는 장치 및 그 장치의 제어 방법에 관한 것이다. 현재에는 기술의 발달에 힘입어 다양한 멀티미디어 기능을 가지고 있는 다양한 기기들이 등장하고 있다. 예를 들어 사진이나 동영상의 촬영, 음악이나 동영상 파일의 재생, 게임, 방송의 수신 등의 복합적인 기능들을 갖춘 멀티미디어 기기(Multimedia player)들이 등장하고 있는 추세이다. 그리고 이러한 기기들은 사용자들을 보다 편리하게 하는 다양한 기능들을 가질 수 있다. 예를 들어 사용자가 회의등에서 중요한 내용을 메모하려고 하는 경우 이러한 기기들은 녹음 기능을 통해 사용자에게 보다 정확하고 편리한 음성 메모 기능을 제공할 수 있다. 이에 따라 사용자는 회의 내용이나 멜로디 등 언제 어디서건 자신이 원하는 음향 정보를 녹음 할 수 있으며, 녹음된 음향 정보를 보관할 수 있다. 따라서 사용자가, 보다 쉽고 빠르게 녹음된 음향 정보를 인식 및 검색할 수 있도록 하는 방법이 현재 활발하게 연구 중인 실정이다. 본 발명의 일 목적은, 사용자가, 녹음된 음향 정보의 내용을 직관적으로 인식하여 보다 빠르고 쉽게 사용자가 원하는 음향 정보를 검색할 수 있도록 하는 음향 정보 녹음 장치 및 그 장치의 제어 방법을 제공하는 것이다. 본 발명의 다른 목적은, 녹음된 음향 정보로부터 사용자가 원하는 부분만을 검색 및 선택하여 청취할 수 있도록 하는 음향 정보 녹음 장치 및 그 장치의 제어 방법을 제공하는 것이다. 상기 또는 다른 목적을 달성하기 위해 본 발명의 일 측면에 따르면, 본 발명의 실시 예에 따른 음향 정보 녹음 장치는, 디스플레이부와, 음향 정보를 입력받는 입력부와, 음향 정보를 출력하기 위한 출력부와, 주변 환경 및 생체 신호 중 적어도 하나를 감지하기 위한 감지부, 및, 입력된 음향 정보를 녹음 및, 녹음된 음향 정보로부터 키워드를 추출하고, 상기 녹음된 음향 정보를 분석한 결과 및 상기 감지부의 감지 결과 중 적어도 하나에 근거하여 이미지 정보를 생성하며, 상기 키워드와 상기 이미지 정보가 결합된 태그 정보를 상기 녹음된 음향 정보에 대응되도록 표시하는 제어부를 포함하며, 상기 제어부는, 상기 녹음된 음향 정보에 포함된 음향 신호를 발생시키는 주체들을 인식하고, 상기 음향 신호를 발생시키는 주체 별로 구분되는 적어도 하나의 서로 다른 그래픽 객체를 상기 디스플레이부 상에 표시 및, 상기 그래픽 객체들 중 선택된 어느 하나에 대응되는 주체로부터 발생되는 음향 신호를 상기 녹음된 음향 정보로부터 추출하여 출력하는 것을 특징으로 한다. 일 실시 예에 있어서, 상기 그래픽 객체는, 상기 녹음된 음향 정보가 복수의 사람 목소리를 포함하는 경우, 적어도 하나의 사람 모양의 그래픽 객체, 또는 적어도 하나의 말풍선 모양의 그래픽 객체, 또는 적어도 하나의 주파수 파형 형태의 그래픽 객체이며, 상기 제어부는, 상기 사람 모양의 그래픽 객체, 또는 상기 말풍선 모양의 그래픽 객체 또는 상기 주파수 파형 형태의 그래픽 객체 중 어느 하나가 선택되는 경우, 선택된 그래픽 객체에 대응되는 사람의 목소리만을 상기 음향 정보로부터 추출하여 출력하는 것을 특징으로 한다. 일 실시 예에 있어서, 상기 제어부는, 상기 음향 정보에 포함된 복수의 음향 신호 중 고유 음색 및 특징에 따라 상기 음향 신호를 발생시키는 주체를 서로 구분하고, 상기 음향 신호를 발생시키는 주체는, 상기 음향 신호의 고유 음색 음색 및 특징에 따라 각각 구분되는 목소리 또는 연주음을 발생시키는 적어도 하나의 사람 또는 악기임을 특징으로 한다. 일 실시 예에 있어서, 상기 제어부는, 상기 음향 정보를 분석한 결과에 따라 상기 녹음된 음향 정보의 유형에 따라 상기 키워드를 추출하는 방식을 서로 다르게 결정하는 것을 특징으로 한다. 일 실시 예에 있어서, 상기 제어부는, 상기 음향 정보를 분석한 결과, 상기 음향 정보가 일정한 리듬을 가지는 멜로디를 포함하는 경우, 음악 검색을 통해 상기 멜로디의 제목을 상기 음향 정보의 키워드로 추출하는 것을 특징으로 한다. 일 실시 예에 있어서, 상기 제어부는, 상기 음향 정보를 분석한 결과, 상기 음향 정보가 적어도 한 명의 사람 음성을 포함하는 경우, VTT(Voice To Text) 과정을 통해 상기 녹음된 음향 정보의 내용을 문자열로 인식하고, 상기 인식된 문자열을 통해 상기 키워드를 추출하는 것을 특징으로 한다. 일 실시 예에 있어서, 상기 제어부는, 상기 인식된 문자열 중 기 설정된 횟수 이상 반복된 단어 또는 상기 반복된 단어들 중 가장 많이 반복된 단어를 상기 키워드로 추출하는 것을 특징으로 한다. 일 실시 예에 있어서, 상기 제어부는, 기 설정된 특정 단어 또는 어구가 상기 인식된 문자열에 포함되어 있는 경우, 상기 특정 단어 또는 어구를 상기 키워드로 추출하는 것을 특징으로 한다. 일 실시 예에 있어서, 상기 제어부는, 미리 입력된 적어도 하나의 단어가 상기 인식된 문자열에 포함되어 있는 경우, 상기 적어도 하나의 단어에 대응되는 대표 단어를 상기 키워드로 추출하는 것을 특징으로 한다. 일 실시 예에 있어서, 상기 제어부는, 상기 음향 정보가 녹음된 시각과, 현재의 위치를 감지한 결과, 상기 녹음 시각 및 현재의 위치에 매칭되는 기 저장된 일정 정보에 근거하여 상기 키워드를 추출하는 것을 특징으로 한다. 일 실시 예에 있어서, 상기 제어부는, 상기 음향 정보를 분석한 결과, 상기 녹음된 음향 정보의 유형에 따라 서로 다른 적어도 하나의 그래픽 객체를 포함하는 이미지 정보를 생성하며, 상기 음향 정보의 유형은, 상기 음향 정보가 복수의 사람 음성을 포함하고 있는지 또는 일정한 리듬을 가지는 멜로디를 포함하고 있는지 여부에 따라 결정되는 것을 특징으로 한다. 일 실시 예에 있어서, 상기 제어부는, 상기 녹음된 음향 정보가 복수의 사람 목소리를 포함하는 경우, 적어도 하나의 사람 모양의 그래픽 객체, 또는 적어도 하나의 말풍선 모양의 그래픽 객체, 또는 적어도 하나의 주파수 파형 형태의 그래픽 객체를 포함하는 상기 이미지 정보를 생성하는 것을 특징으로 한다. 일 실시 예에 있어서, 상기 제어부는, 상기 녹음된 음향 정보로부터 인식되는 목소리의 주체의 개수에 대응되는 개수의 상기 그래픽 객체를 포함하는 상기 이미지 정보를 생성하는 것을 특징으로 한다. 일 실시 예에 있어서, 상기 제어부는, 상기 녹음된 음향 정보에 포함된 복수의 사람 목소리 중 인식 가능한 목소리가 있는 경우, 해당 목소리에 대응되는 인물을 인식하고 인식된 인물에 대응되는 이미지를 상기 그래픽 객체로 표시하는 것을 특징으로 한다. 일 실시 예에 있어서, 상기 제어부는, 상기 음향 정보가 녹음되는 동안 상기 감지부의 감지 결과를 이용하여 사용자의 정서 상태를 판단하고, 상기 이미지 정보는, 상기 판단된 사용자의 정서 상태에 대응되는 그래픽 객체를 포함하는 것을 특징으로 한다. 일 실시 예에 있어서, 상기 제어부는, 음향 정보가 녹음되면 현재 위치를 감지하고, 상기 위치와 관련된 정보를 상기 키워드로 추출 및, 상기 감지된 위치에 대응되는 그래픽 객체를 포함하는 상기 태그 정보를 상기 녹음된 음향 정보에 대응되도록 표시하는 것을 특징으로 한다. 일 실시 예에 있어서, 상기 제어부는, 검색 정보가 입력되면, 입력된 검색 정보에 대응되는 부분을 포함하는 음향 정보를 검색하며, 상기 검색 정보는, 텍스트 정보, 녹음된 음향 정보, 사용자의 정서 상태, 현재의 위치 중 어느 하나임을 특징으로 한다. 일 실시 예에 있어서, 상기 검색 정보는, 사람 목소리의 개수에 대한 정보를 더 포함하며, 상기 제어부는, 복수의 사람 목소리를 포함하는 기 저장된 음향 정보들 중, 상기 검색 정보에 근거하여 특정 수의 사람 목소리만이 포함된 음향 정보들을 검색하는 것을 특징으로 한다. 일 실시 예에 있어서, 상기 이미지 정보는, 상기 음향 정보의 녹음 볼륨 레벨을 표시하기 위한 그래픽 객체를 포함하는 것을 특징으로 한다. 상기 또는 다른 목적을 달성하기 위해 본 발명의 일 측면에 따르면, 본 발명의 실시 예에 따른 음향 정보 녹음 장치의 제어 방법은, 음향 정보를 녹음하는 장치에 있어서, 음향 정보를 녹음하고, 상기 음향 정보 녹음 장치의 주변 환경 및 생체 신호를 적어도 하나 감지하는 단계와, 상기 녹음된 음향 정보를 분석하여 키워드를 추출 및, 상기 음향 정보에 포함된 음향 신호의 발생 주체들을 인식하는 단계와, 상기 감지된 주변 환경, 상기 감지된 생체 신호 및, 상기 인식된 음향 신호의 발생 주체들 중 적어도 하나를 이용하여 이미지 정보를 생성하는 단계와, 상기 생성된 이미지 정보와 상기 추출된 키워드를 포함하는 태그 정보를 상기 녹음된 음향 정보에 대응되게 표시하는 단계, 및, 상기 태그 정보 중 어느 하나가 선택되면, 그에 대응되는 음향 정보를 출력하는 단계를 포함하며, 상기 음향 정보를 출력하는 단계는, 상기 인식된 음향 신호 발생 주체들 중 선택된 어느 하나에 대응되는 음향 신호를 상기 음향 정보로부터 추출하여 출력하는 단계를 포함하는 단계임을 특징으로 한다. 본 발명에 따른 음향 정보 제공 장치 및 그 장치의 제어 방법의 효과에 대해 설명하면 다음과 같다. 본 발명의 실시 예들 중 적어도 하나에 의하면, 본 발명은 녹음된 음향 정보로부터 키워드를 추출하고, 추출된 키워드로부터 생성된 이미지 정보와 상기 키워드를 이용하여 상기 녹음된 음향 정보의 태그 정보를 생성함으로써, 사용자가 상기 녹음된 음향 정보를 직관적으로 인식할 수 있도록 한다는 장점이 있다. 또한, 본 발명의 실시예들 중 적어도 하나에 의하면, 본 발명은 녹음된 음향 정보를 기 설정된 기준에 따라 구분하여 사용자가 상기 녹음된 음향 정보로부터 원하는 적어도 일부만을 선택적으로 청취할 수 있도록 한다는 장점이 있다. 도 1은 본 발명과 관련된 음향 정보 녹음 장치를 설명하기 위한 블록도이다. 도 2는 본 발명의 실시 예에 따른 음향 정보 녹음 장치에서 음향 정보를 녹음하고, 사용자의 선택에 따라 재생하는 예를 도시한 예시도이다. 도 3은 본 발명의 실시 예에 따른 음향 정보 녹음 장치에서, 녹음된 음향 정보의 태그 정보를 생성 및 음향 정보를 재생하는 동작 과정을 도시한 흐름도이다. 도 4는 본 발명의 실시 예에 따른 음향 정보 녹음 장치에서, 사용자에 의해 선택된 음향 정보가 재생되는 동작 과정을 도시한 흐름도이다. 도 5는 본 발명의 실시 예에 따른 음향 정보 녹음 장치에서, 입력된 검색 정보에 따라 음향 정보가 검색되는 동작 과정을 도시한 흐름도이다. 도 6은 본 발명의 실시 예에 따른 음향 정보 녹음 장치에서, 녹음된 음향 정보가 이미지 정보와 함께 표시되는 예를 도시한 예시도이다. 도 7a, 도 7b, 도 7c 및 도 7d는 본 발명의 실시 예에 따른 음향 정보 녹음 장치에서, 녹음된 음향 정보의 일부분에 대응되는 그래픽 객체가 표시되고, 그에 따라 상기 녹음된 음향 정보의 일부의 재생이 선택되는 예를 도시한 예시도들이다. 도 8은 본 발명의 실시 예에 따른 음향 정보 녹음 장치에, 사용자에 의해 입력되는 검색 정보의 예를 도시한 예시도이다. 이하, 첨부된 도면을 참조하여 본 명세서에 개시된 실시 예를 상세히 설명하되, 동일하거나 유사한 구성요소에는 동일, 유사한 도면 부호를 부여하고 이에 대한 중복되는 설명은 생략하기로 한다. 이하의 설명에서 사용되는 구성요소에 대한 접미사 "모듈" 및 "부"는 명세서 작성의 용이함만이 고려되어 부여되거나 혼용되는 것으로서, 그 자체로 서로 구별되는 의미 또는 역할을 갖는 것은 아니다. 또한, 본 명세서에 개시된 실시 예를 설명함에 있어서 관련된 공지 기술에 대한 구체적인 설명이 본 명세서에 개시된 실시 예의 요지를 흐릴 수 있다고 판단되는 경우 그 상세한 설명을 생략한다. 또한, 첨부된 도면은 본 명세서에 개시된 실시 예를 쉽게 이해할 수 있도록 하기 위한 것일 뿐, 첨부된 도면에 의해 본 명세서에 개시된 기술적 사상이 제한되지 않으며, 본 발명의 사상 및 기술 범위에 포함되는 모든 변경, 균등물 내지 대체물을 포함하는 것으로 이해되어야 한다. 본 명세서에서 설명되는 음향 정보 녹음 장치에는 휴대폰, 스마트 폰(smart phone), 노트북 컴퓨터(laptop computer), 디지털방송용 단말기, PDA(personal digital assistants), PMP(portable multimedia player), 네비게이션, 슬레이트 PC(slate PC), 태블릿 PC(tablet PC), 울트라북(ultrabook), 웨어러블 디바이스(wearable device, 예를 들어, 워치형 단말기 (smartwatch), 글래스형 단말기 (smart glass), HMD(head mounted display)) 등이 포함될 수 있다. 그러나 본 명세서에 기재된 실시 예에 따른 구성은 이동 단말기에만 적용 가능한 경우를 제외하면, 디지털 TV, 데스크탑 컴퓨터, 디지털 사이니지 등과 같은 고정 단말기에도 적용될 수도 있음을 본 기술분야의 당업자라면 쉽게 알 수 있을 것이다. 도 1은 본 발명과 관련된 음향 정보 녹음 장치를 설명하기 위한 블록도이다. 상기 음향 정보 녹음 장치(100)는 입력부(120), 감지부(140), 출력부(150), 메모리(170) 및 제어부(180) 등을 포함할 수 있다. 그리고 무선 통신부(110)를 더 포함하여 구성될 수도 있다. 도 1a에 도시된 구성요소들은 본 발명의 실시 예에 따른 음향 정보 녹음 장치(100)를 구현하는데 있어서 필수적인 것은 아니어서, 위에서 열거된 구성요소들 보다 많거나, 또는 적은 구성요소들을 가질 수 있다. 보다 구체적으로, 상기 구성요소들 중 센싱부(140)는, 사용자의 생체 신호를 센싱하기 위한 적어도 하나의 센서를 포함할 수 있다. 예를 들어, 센싱부(140)는 사용자의 심박수를 측정하기 위한 심박 센서, 사용자의 체온을 체크하기 위한 체온계 및, 혈압 등 사용자의 혈류량을 측정하기 위한 혈압계 등의 센서들 중 적어도 하나를 포함할 수 있다. 또한 제어부(180)는 상기 센싱부(140)의 센서들 중 적어도 둘 이상의 센서에서 센싱되는 정보들을 조합하여 활용할 수 있다. 출력부(150)는 청각 및 시각과 관련된 출력을 발생시키기 위한 것으로, 디스플레이부(151), 음향 출력부(152)를 포함할 수 있다. 디스플레이부(151)는 터치 센서와 상호 레이어 구조를 이루거나 일체형으로 형성됨으로써, 터치 스크린을 구현할 수 있다. 이러한 터치 스크린은, 음향 정보 녹음 장치(100)와 사용자 사이의 입력 인터페이스를 제공하는 사용자 입력부(123)로써 기능함과 동시에, 음향 정보 녹음 장치(100)와 사용자 사이의 출력 인터페이스를 제공할 수 있다. 그리고 음향 출력부(150)는 음향 정보를 출력하기 위한 구성 요소(예를 들어 스피커)를 포함할 수 있다. 그리고 음향 정보가 재생되는 경우, 상기 음향 정보를 상기 구성 요소를 통해 가청음으로 출력할 수 있다. 입력부(120)는, 오디오 신호 입력을 위한 마이크로폰(microphone, 122), 또는 오디오 입력부, 사용자로부터 정보를 입력받기 위한 사용자 입력부(123, 예를 들어, 터치키(touch key), 푸시키(mechanical key) 등)를 포함할 수 있다. 입력부(120)에서 수집한 음성 데이터나 이미지 데이터는 분석되어 사용자의 제어명령으로 처리될 수 있다. 또한 입력부(120)는 음향 정보(또는 신호), 데이터, 또는 사용자로부터 입력되는 정보의 입력을 위한 것으로서, 마이크로폰(122)은 외부의 음향 신호를 전기적인 음성 데이터로 처리한다. 처리된 음성 데이터는 음향 정보 녹음 장치(100)에서 수행 중인 기능(또는 실행 중인 응용 프로그램)에 따라 다양하게 활용될 수 있다. 한편, 마이크로폰(122)에는 외부의 음향 신호를 입력 받는 과정에서 발생되는 잡음(noise)을 제거하기 위한 다양한 잡음 제거 알고리즘이 구현될 수 있다. 사용자 입력부(123)는 사용자로부터 정보를 입력받기 위한 것으로서, 사용자 입력부(123)를 통해 정보가 입력되면, 제어부(180)는 입력된 정보에 대응되도록 음향 정보 녹음 장치(100)의 동작을 제어할 수 있다. 이러한, 사용자 입력부(123)는 기계식 (mechanical) 입력수단 및 터치식 입력수단을 포함할 수 있다. 또한, 메모리(170)는 음향 정보 녹음 장치(100)의 다양한 기능을 지원하는 데이터를 저장한다. 메모리(170)는 음향 정보 녹음 장치(100)에서 구동되는 다수의 응용 프로그램(application program 또는 애플리케이션(application)), 음향 정보 녹음 장치(100)의 동작을 위한 데이터들, 명령어들을 저장할 수 있다. 이러한 응용 프로그램 중 적어도 일부는, 무선 통신을 통해 외부 서버로부터 다운로드 될 수 있다. 또한 이러한 응용 프로그램 중 적어도 일부는, 음향 정보 녹음 장치(100)의 기본적인 기능(예를 들어, 음향 정보 녹음 기능)을 위하여 출고 당시부터 음향 정보 녹음 장치(100)상에 존재할 수 있다. 한편, 응용 프로그램은, 메모리(170)에 저장되고, 음향 정보 녹음 장치(100) 상에 설치되어, 제어부(180)에 의하여 상기 음향 정보 녹음 장치(100)의 동작(또는 기능)을 수행하도록 구동될 수 있다. 제어부(180)는 상기 응용 프로그램과 관련된 동작 외에도, 통상적으로 음향 정보 녹음 장치(100)의 전반적인 동작을 제어한다. 제어부(180)는 위에서 살펴본 구성요소들을 통해 입력 또는 출력되는 신호, 데이터, 정보 등을 처리하거나 음향 정보 녹음 장치(100)에 저장된 응용 프로그램을 구동함으로써, 사용자가 원하는 시간 동안 입력되는 음향 신호를 녹음하거나 사용자에게 적절한 정보(예를 들어 기 녹음된 음향 정보) 또는 기능을 제공 또는 처리할 수 있다. 또한, 제어부(180)는 메모리(170)에 저장된 응용 프로그램을 구동하기 위하여, 도 1과 함께 살펴본 구성요소들 중 적어도 일부를 제어할 수 있다. 나아가, 제어부(180)는 상기 응용 프로그램의 구동을 위하여, 이동 단말기(100)에 포함된 구성요소들 중 적어도 둘 이상을 서로 조합하여 동작시킬 수 있다. 한편 무선 통신부(110)는, 이동 단말기(100)와 무선 통신 시스템 사이, 이동 단말기(100)와 다른 이동 단말기(100) 사이, 또는 이동 단말기(100)와 외부서버 사이의 무선 통신을 가능하게 하는 하나 이상의 모듈을 포함할 수 있다. 또한, 상기 무선 통신부(110)는, 이동 단말기(100)를 하나 이상의 네트워크에 연결하는 하나 이상의 모듈을 포함할 수 있다. 이러한 무선 통신부(110)는, 무선 인터넷 모듈(113), 근거리 통신 모듈(114), 위치정보 모듈(115) 중 적어도 하나를 포함할 수 있다. 여기서 무선 인터넷 모듈(113)은 무선 인터넷 접속을 위한 모듈을 말하는 것으로, 이동 단말기(100)에 내장되거나 외장될 수 있다. 무선 인터넷 모듈(113)은 무선 인터넷 기술들에 따른 통신망에서 무선 신호를 송수신하도록 이루어진다. 그리고 무선 인터넷 기술로는, 예를 들어 WLAN(Wireless LAN), Wi-Fi(Wireless-Fidelity), Wi-Fi(Wireless Fidelity) Direct, DLNA(Digital Living Network Alliance), WiBro(Wireless Broadband) 등이 있으며, 상기 무선 인터넷 모듈(113)은 상기에서 나열되지 않은 인터넷 기술까지 포함한 범위에서 적어도 하나의 무선 인터넷 기술에 따라 데이터를 송수신하게 된다. 위치정보 모듈(115)은 이동 단말기의 위치(또는 현재 위치)를 획득하기 위한 모듈로서, 그의 대표적인 예로는 GPS(Global Positioning System) 모듈 또는 WiFi(Wireless Fidelity) 모듈이 있다. 예를 들어, 이동 단말기는 GPS모듈을 활용하면, GPS 위성에서 보내는 신호를 이용하여 이동 단말기의 위치를 획득할 수 있다. 다른 예로서, 이동 단말기는 Wi-Fi모듈을 활용하면, Wi-Fi모듈과 무선신호를 송신 또는 수신하는 무선 AP(Wireless Access Point)의 정보에 기반하여, 이동 단말기의 위치를 획득할 수 있다. 필요에 따라서, 위치정보모듈(115)은 치환 또는 부가적으로 이동 단말기의 위치에 관한 데이터를 얻기 위해 무선 통신부(110)의 다른 모듈 중 어느 기능을 수행할 수 있다. 위치정보모듈(115)은 이동 단말기의 위치(또는 현재 위치)를 획득하기 위해 이용되는 모듈로, 이동 단말기의 위치를 직접적으로 계산하거나 획득하는 모듈로 한정되지는 않는다. 상기 각 구성요소들 중 적어도 일부는, 이하에서 설명되는 다양한 실시 예들에 따른 음향 정보 녹음 장치(100)의 동작, 제어, 또는 제어방법을 구현하기 위하여 서로 협력하여 동작할 수 있다. 또한, 상기 음향 정보 녹음 장치(100)의 동작, 제어, 또는 제어방법은 상기 메모리(170)에 저장된 적어도 하나의 응용 프로그램의 구동에 의하여 음향 정보 녹음 장치(100) 상에서 구현될 수 있다. 한편 본 발명의 실시 예에 따른 음향 정보 녹음 장치(100)의 제어부(180)는 사용자의 제어에 따라 마이크(122)를 통해 입력되는 음향 정보를 녹음할 수 있다. 그리고 녹음된 음향 정보를 분석하여, 키워드를 추출하고 추출된 키워드에 대응되는 이미지 정보를 생성할 수 있다. 그리고 제어부(180)는 상기 이미지 정보를 포함하는 태그 정보를 생성하여 상기 녹음된 음향 정보에 대응되게 표시할 수 있다. 도 2는 이러한 본 발명의 실시 예에 따른 음향 정보 녹음 장치에서 음향 정보를 녹음하고, 사용자의 선택에 따라 재생하는 예를 보이고 있는 것이다. 도 2의 (a)에서 보이고 있는 것과 같이, 사용자의 제어에 따라 음향 정보가 녹음되면, 제어부(180)는 상기 녹음된 음향 정보로부터 추출된 키워드를 이용하여 도 2의 (b)에서 보이고 있는 것과 같이 키워드 및 이미지 정보로서 상기 녹음된 음향 정보를 표시할 수 있다. 예를 들어 상기 키워드는, 상기 녹음된 음향 정보의 텍스트 인식(VTT : Voice To Text) 과정을 통해 인식된 텍스트로부터 추출될 수 있다. 일 예로 제어부(180)는 일정 개수 이상 반복되는 단어를 상기 키워드로 추출하거나, 또는 사용자에 의해 미리 설정된 단어들이 상기 인식된 텍스트에 기 설정된 개수 이상 포함되어 있는 경우, 상기 단어들에 대응되도록 미리 설정된 대표 단어가 상기 키워드로 추출될 수도 있다. 또는 특정 단어가 포함되어 있는 경우 그에 대응되는 다른 단어가 상기 키워드로 추출될 수도 있다. 또는 제어부(180)는 기 설정된 사용자의 일정이 있는 경우, 그 일정 정보로부터 추출될 수도 있다. 뿐만 아니라 상기 키워드 정보는, 상기 녹음되는 음향 정보가 일정한 박자와 음정을 가지는 멜로디(melody)인 경우, 음악 검색 결과를 통해 검색되는 상기 멜로디의 제목일 수도 있다. 한편 이미지 정보는, 다양하게 결정될 수 있다. 예를 들어 상기 이미지 정보는, 상기 키워드와 관련된 것일 수 있다. 예를 들어 상기 키워드가 ‘미팅’ 또는 ‘회의’인 경우, 이미지 정보는 상기 ‘미팅’ 또는 ‘회의’에 대응되는 그래픽 객체들(예를 들어 말풍선 형태의 그래픽 객체 : 212)을 적어도 하나 포함하는 형태로 생성될 수 있다. 또는 상기 이미지 정보는 상기 녹음된 음향 정보가, 멜로디를 포함하고 있는 경우, 그에 대응되는 그래픽 객체(예를 들어 음표 및 오선지 형태의 그래픽 객체 : 216)를 포함할 수도 있다. 또는 상기 이미지 정보는, 음향 정보 녹음 장치(100)의 주변을 감지한 감지 결과에 따라 결정될 수도 있다. 예를 들어 상기 이미지 정보는 음향 정보 녹음 장치(100)의 센싱부(140)의 감지 결과, 즉, 사용자의 생체 신호를 감지한 결과를 이용하여, 판단되는 사용자의 정서 상태에 대응되는 그래픽 객체(예를 들어 웃는 얼굴에 대응되는 그래픽 객체 : 214)를 포함할 수 있다. 또는 상기 이미지 정보는 현재 사용자의 위치 정보에 대응되는 그래픽 객체를 포함할 수도 있음은 물론이다. 이러한 이미지 정보들은 녹음된 음향 정보로부터 추출된 키워드, 또는 음향 정보의 유형이나 기 설정된 우선순위 등에 따라 생성될 수 있다. 예를 들어 제어부(180)는 녹음된 음향 정보로부터 키워드가 추출되는 경우 그에 대응되는 그래픽 객체를 검색하고, 검색된 그래픽 객체를 포함하는 이미지 정보를 생성할 수 있다. 그리고 상기 추출된 키워드와 상기 이미지 정보를 결합하여 상기 녹음된 음향 정보에 대한 태그 정보를 생성할 수 있다. 따라서 만약 상기 추출된 키워드가 ‘미팅’인 경우, 제어부(180)는 도 2의 (b)에서 보이고 있는 것과 같이, 상기 ‘미팅’에 대응되는 말풍선 모양의 그래픽 객체를 포함하는 이미지 정보를 생성할 수 있다. 그리고 제어부(180)는 상기 키워드 ‘미팅’과 상기 생성된 이미지 정보를 포함하는 제1 태그 정보(212)를 생성할 수 있다. 한편, 상기 녹음된 음향 정보가 일정한 음정과 박자를 가지는 멜로디인 경우, 제어부(180)는 음악 검색을 통해 검색된 상기 멜로디의 제목‘Sunny Day’를 키워드로 추출할 수 있다. 이러한 경우 제어부(180)는 상기 음향 정보를 오선지 및 상기 오선지위에 표시되는 음표 모양의 그래픽 객체들을 포함하는 이미지 정보를 생성할 수 있다. 그리고 제어부(180)는 상기 키워드 ‘Sunny day’와 상기 생성된 이미지 정보를 포함하는 제3 태그 정보(216)를 생성할 수 있다. 한편 상술한 설명에 의하면, 본 발명의 실시 예에 따른 음향 정보 녹음 장치(100)는 상기 녹음된 음향 정보에 대응되는 이미지 정보로서, 사용자의 정서 상태를 표시할 수도 있음은 물론이다. 예를 들어 제어부(180)는 센싱부(140)의 센서들로부터 감지되는 사용자의 심박수와 체온, 그리고 혈류량 등으로부터 사용자가 정서 상태를 판단할 수 있다. 이러한 경우 제어부(180)는 상기 음향 정보가 녹음되는 동안 판단된 사용자의 정서 상태들 중, 가장 지배적인 정서 상태(예를 들어 가장 많은 시간동안 감지되었던 정서 상태)에 대응되는 그래픽 객체를 이미지 정보로 표시할 수 있다. 한편 제어부(180)는 기 설정된 우선순위 또는 사용자의 선택에 따라 상기 녹음된 음향 정보에 대응되는 이미지 정보의 유형이 결정되도록 할 수도 있다. 예를 들어 제어부(180)는 상기 음향 정보를, 상기 음향 정보가 녹음된 상황에 따라 최우선적으로 분류할 수 있고, 상기 음향 정보가 녹음된 상황이 기 설정된 특정 상황이 아닌 경우 멜로디를 포함하고 있는지 여부 또는 사용자의 정서 상태에 따라 상기 이미지 정보의 유형이 결정되도록 할 수도 있다. 이러한 경우 제어부(180)는 상기 녹음된 음향 정보를 분석한 결과, 상기 음향 정보가 녹음된 상황이 ‘미팅(Meeting)’ 이나 ‘회의’인 경우, 멜로디가 포함되거나, 사용자의 정서 상태가 특정 상태인 경우라고 할지라도, 상기 녹음된 음향 정보에 대해, 키워드를 ‘미팅’으로 추출할 수 있으며 그에 따른 이미지 정보를 생성할 수 있다. 반면, 제어부(180)는 상기 녹음된 음향 정보를 분석한 결과, 상기 음향 정보가 녹음된 상황이 특정 상황(예를 들어 미팅이나 회의 중)이 아닌 경우, 멜로디를 포함하고 있는지 여부를 검출할 수 있다. 그리고 멜로디를 포함하고 있는 경우에 상기 녹음된 음향 정보가 멜로디라고 판단할 수도 있다. 이러한 경우 제어부(180)는 상기 녹음된 음향 정보에 대해 상기 제3 태그 정보(216)에서 보이고 있는 것과 같은 이미지 정보가 대응되게 표시할 수도 있다. 그리고 제어부(180)는 상기 음향 정보에 멜로디도 포함되어 있지 않다고 판단되는 경우, 또는 비록 멜로디가 포함되어 있다 하더라도 멜로디가 포함된 시간이 기 설정된 시간 미만이거나, 녹음된 다른 음향 신호에 비해 포함된 멜로디 음향 신호의 크기가 기 설정된 수준미만으로 약할 경우, 상기 음향 정보가 멜로디에 대한 것이 아니라고 판단할 수 있다. 이러한 경우 제어부(180)는 도 2의 (b)의 제2 태그 정보(214)에서 보고 있는 것처럼 사용자의 정서 상태에 대응되는 그래픽 객체를 이미지 정보로 표시할 수 있다. 한편 위에서 설명한 바와 같이, 음향 정보가 녹음된 상황, 멜로디의 포함 여부, 음향 정보가 녹음될 당시의 감지된 사용자의 정서 상태 외에, 제어부(180)는 얼마든지 더 다양한 기준에 근거하여 상기 음향 정보에 표시할 이미지 정보의 유형을 결정할 수도 있음은 물론이다. 한편 제어부(180)는, 음향 정보가 녹음될 당시에, 상기 음향 정보를 분석하여 다양한 기준에 따라 분류할 수 있다. 예를 들어 제어부(180)는 상기 음향 정보를 주체별로 각각 구분하여 인식할 수 있다. 즉, 제어부(180)는 ‘미팅’에 참석한 사람들의 목소리를, 각각의 목소리의 주파수 및 목소리의 고저 등과 같은 특징을 기준으로 상기 음향 정보로부터 상기 미팅의 각 참석자들 별 목소리를 구분할 수 있다. 이와 유사하게 제어부(180)는 기 저장된 다양한 악기들의 고유 음색을 이용하여‘멜로디’로부터 다양한 악기들의 소리를 각각 구분할 수 있다. 또는 제어부(180)는 음향 정보를 녹음하는 동안 판단된 사용자의 정서 상태를 기준으로 상기 녹음된 음향 정보를 복수의 구간으로 구분하여 인식할 수도 있다. 이에 따라 제어부(180)는 상기 이미지 정보에 포함되는 그래픽 객체들을, 상기 인식된 주체들의 개수를 반영하여 표시할 수도 있다. 즉, 예를 들어 상기 ‘미팅’에 참가한 사람, 즉 목소리의 주체(에이전트)가 두 명이상인 경우, 그에 대응되는 그래픽 객체들, 즉 두 개의 말풍선을 포함하는 이미지 정보가, 도 2의 (b)에서 보이고 있는 제1 태그 정보(212)에서 보이고 있는 것과 같이 표시될 수 있다. 이에 따라 사용자는 녹음된 음향 정보의 태그 정보만 확인하더라도, 직관적으로 키워드 및, 상기 ‘미팅’에 참석한 사람들(에이전트)의 수를 알 수 있다. 한편 제어부(180)는 녹음된 음향 정보들 중 어느 하나가 선택되는 경우, 상기 선택된 음향 정보를 재생할 수 있다. 이러한 경우 제어부(180)는 사용자의 선택에 따라 선택된 음향 정보 전체를 재생하거나 또는 음향 정보의 일부만을 재생할 수도 있다. 여기서 음향 정보의 일부는, 특정 주체로부터 발생한 음향 정보(예를 들어 특정 사람의 목소리 또는 특정 악기)일 수도 있고, 또는 사용자의 특정 감정 상태에 대응되는 구간일 수도 있다. 도 2의 (c) 및 (d)는 사용자로부터 선택된 음향 정보가, ‘미팅’상황에서 녹음된 음향 정보가 재생되는 예를 보이고 있는 것이다. 예를 들어 제어부(180)는 상기 음향 정보의 재생이 선택되면, 도 2의 (c)에서 보이고 있는 것과 같이, 사용자가 전체 재생(222) 또는 일부의 재생(224)을 선택 및, 사용자가 일부의 재생(224)을 선택하는 경우에, 상기 음향 정보에 포함된 목소리들이 주체별로, 즉 사람별(228, 230)로 서로 구분되게 표시되는 그래픽 객체(226)를 디스플레이부(151) 상에 표시할 수 있다. 이러한 경우 제어부(180)는 상기 그래픽 객체(226)를 통해 사용자로부터 특정 주체의 목소리만을 선택받을 수 있으며, 이러한 경우 제어부(180)는 상기 음향 정보로부터 사용자가 선택한 사람의 목소리만 추출하여 재생할 수 있다. 도 2의 (d)는 이러한 경우에서 사용자로부터 선택된 특정 사람에 대응되는 목소리(230)만이, 사용자로부터 선택된 제1 태그 정보(212)에 대응되는 음향 정보로부터 추출되어 재생되는 예를 보이고 있는 것이다. 한편, 이하에서 다양한 실시 예는 예를 들어, 소프트웨어, 하드웨어 또는 이들의 조합된 것을 이용하여 컴퓨터 또는 이와 유사한 장치로 읽을 수 있는 기록매체 내에서 구현될 수 있다. 이하에서는 이와 같이 구성된 이동 단말기에서 구현될 수 있는 제어 방법과 관련된 실시 예들에 대해 첨부된 도면을 참조하여 살펴보겠다. 본 발명은 본 발명의 정신 및 필수적 특징을 벗어나지 않는 범위에서 다른 특정한 형태로 구체화될 수 있음은 당업자에게 자명하다. 도 3은 본 발명의 실시 예에 따른 음향 정보 녹음 장치에서, 녹음된 음향 정보의 태그 정보를 생성 및 음향 정보를 재생하는 동작 과정을 도시한 흐름도이다. 도 3을 참조하여 살펴보면, 본 발명의 실시 예에 따른 음향 정보 녹음 장치(100)의 제어부(180)는 사용자로부터 음향 정보의 녹음이 선택되는 경우 입력되는 음향 정보를 녹음 및, 관련된 정보를 감지한다(S300). 여기서 상기 관련된 정보라는 것은 다양한 것이 될 수 있다. 예를 들어 상기 관련 정보는 현재의 시각 및 위치에 대한 것일 될 수 있다. 이러한 경우 제어부(180)는 현재의 시각 및 위치에 대한 정보에 근거하여, 기 저장된 사용자의 일정 정보로부터 현재 사용자의 상황을 인식할 수 있다. 즉, 현재 감지된 시각과 사용자의 위치가, 상기 일정 정보에 포함된 일정에 대응되는 시각 및 장소인 경우, 제어부(180)는 사용자가 상기 기 설정된 일정에 따른 상황에 있는 것으로 판단할 수 있다. 이러한 경우 제어부(180)는 상기 기 설정된 일정에 관련된 정보를 상기 관련 정보로서 감지할 수 있다. 한편 상기 관련 정보는, 사용자의 생체 신호에 관련된 정보일 수도 있다. 즉 상기 관련 정보는 사용자의 심박수, 체온, 혈류량, 호흡의 세기 및 호흡수 중 적어도 하나 일 수 있으며, 제어부(180)는 이러한 사용자의 생체 신호 감지 결과에 근거하여 사용자의 다양한 정서 상태를 판단할 수 있다. 예를 들어 제어부(180)는 이러한 사용자의 생체 신호를 감지한 결과에 근거하여, 사용자가 즐거워하는 상태인지, 침울해하는 상태인지, 또는 흥분 또는 집중하고 있는 상태인지를 판단할 수 있다. 한편 상기 S300 단계에서 음향 정보의 녹음과 함께 관련 정보가 감지되면, 제어부(180)는 상기 관련된 정보를 바탕으로 상기 음향 정보를 분석할 수 있다(S302). 예를 들어 상기 S300 단계에서 제어부(180)는 상기 녹음된 음향 정보의 유형을 분석할 수 있다. 즉, 제어부(180)는 상기 녹음된 음향 정보에 멜로디가 기 설정된 수준 이상 포함되어 있는 경우, 상기 음향 정보를 멜로디로 판단할 수 있으며, 사람의 목소리로 판별되는 음향 신호들이 포함되어 있는 경우 이를 회의, 미팅 등 음성을 녹음한 음향 정보라고 판단할 수 있다. 한편, 제어부(180)는 상기 S302 단계에서 상기 녹음된 음향 정보를 음향 신호의 발생 주체를 기준으로 상기 음향 정보에 포함된 음향 신호들을 분류할 수 있다. 예를 들어 상기 음향 정보가 복수의 사람 목소리를 포함하는 경우, 제어부(180)는 상기 음향 정보로부터 음향 신호의 발생 주체, 즉 ‘사람’을 기준으로 목소리들을 분류할 수 있다. 또는 제어부(180)는 상기 음향 정보가 멜로디인 경우, 상기 음향 정보로부터 상기 멜로디를 연주한 악기 별 음색을 구분하여 각 악기 별 음향 신호를 분류할 수도 있다. 여기서 상기 악기별 음색에 대한 정보는 메모리(170)에 기 저장되어 있을 수 있다. 이러한 음향 신호의 주체는, 상기 녹음된 음향 정보에 일정 수준 이상의 세기를 가진 음향 신호들에 한해 구분될 수도 있음은 물론이다. 예를 들어 제어부(180)는 대화 내용을 녹음한 음향 정보의 경우, 상기 음향 정보에 포함된 목소리들 중 기 설정된 크기 이상의 목소리에 대응되는 사람들만을 음향 신호의 발생 주체로 인식할 수도 있다. 또한 이와 유사하게 제어부(180)는 상기 음향 정보가 멜로디를 녹음한 것인 경우, 상기 멜로디에 포함된 악기 소리들 중 에 일정 수준 이상의 시간 또는 크기를 가지는 악기 소리만을 음향 신호의 발생 주체로 인식하고, 인식된 악기들에 대한 소리만을 따로 구분하여 인식할 수도 있음은 물론이다. 한편 제어부(180)는 음향 신호의 발생 주체 뿐만 아니라, 상기 음향 정보가 녹음되는 동안 판단된 사용자의 정서 상태에 근거하여 상기 음향 정보를 복수개의 음향 정보로 구분할 수도 있다. 즉, 제어부(180)는 상기 음향 정보가 녹음되는 동안 판단된 사용자의 정서 상태를 상기 음향 정보의 각 시간 구간에 매칭하여, 상기 음향 정보의 시간 구간마다 대응되는 사용자의 정서 상태에 따라 상기 음향 정보를 구분하여 인식할 수도 있다. 한편 상기 관련 정보는 사용자의 위치 정보를 포함할 수 있다. 이러한 경우, 제어부(180)는 상기 음향 정보가 녹음되는 동안 감지된 사용자의 위치 상태를 상기 음향 정보의 각 시간 구간에 매칭할 수 있다. 그리고 상기 음향 정보가 녹음되는 동안 사용자의 위치가 이동되는 경우, 상기 음향 정보의 시간 구간마다 대응되는 사용자의 위치를 인식할 수도 있음은 물론이다. 한편 S302 단계에서, 상기 감지된 관련 정보에 근거하여 상기 녹음된 음향 정보가 분석되면, 제어부(180)는 상기 녹음된 음향 정보로부터 키워드를 추출할 수 있다. 여기서 키워드는 다양한 방법으로 추출될 수 있다. 예를 들어 제어부(180)는 상기 녹음된 음향 정보의 VTT(Voice To Text) 인식 결과를 바탕으로 상기 키워드를 추출할 수 있다. 이러한 경우 제어부(180)는 상기 음향 정보의 VTT 인식 결과 생성된 문자열에 포함된 단어들을 기준으로 상기 키워드를 추출할 수도 있다. 일 예로 제어부(180)는 상기 문자열 중 기 설정된 횟수 이상 반복되는 단어가 있는 경우 이를 상기 키워드로 추출하거나, 또는 가장 많이 반복된 단어를 상기 키워드로 추출할 수도 있다. 또는 제어부(180)는 기 설정된 특정 단어(예를 들어 ‘훈화’, ‘훈시’, ‘사장님’, ‘소장님’ 등) 또는 어구(예를 들어 ‘사장님 훈화 말씀이 있겠습니다.’, ‘소장님 훈시 말씀이 있겠습니다.’) 있는 경우, 상기 특정 단어 또는 특정 어구를 상기 문자열에 대한 키워드로 추출할 수도 있다. 또는 제어부(180)는 사용자로부터 기 설정된 단어가 포함되어 있는 경우 이에 대응되는 대표 단어로 상기 문자열의 키워드를 추출할 수도 있다. 이러한 단어와 대응되는 대표 단어의 예는 하기 표 1에서 보이고 있는 것과 같다. 표 1 상기 표 1에서 보이고 있는 것과 같이, 사용자는 미리 특정 단어들(발명, 특허, 발명자 등)을 설정하여 둘 수 있다. 그리고 그 대표 단어로서 ‘특허 미팅’을 설정할 수 있다. 이러한 경우 제어부(180)는 현재 녹음된 음향 정보의 VTT 결과 생성된 문자열에, 상기 단어들, 즉 발명, 특허, 발명자, 특허권, 청구항 등의 단어가 포함 또는 일정 수준 이상 반복되는 경우, 상기 녹음된 음향 정보에 대응되는 키워드를 ‘특허 미팅’으로 추출할 수 있다. 또는 제어부(180)는 상기 음향 정보의 키워드를 추출하기 위해, 기 설정된 사용자의 일정 정보를 이용할 수도 있다. 이러한 경우 제어부(180)는 현재 시각 및 현재 사용자의 위치가 상기 일정 정보에 포함된 장소 및 시각 정보에 일치하는 경우, 사용자가 상기 일정 정보에 대응되는 일정 중에 있다고 판단할 수 있다. 그리고 제어부(180)는 상기 일정 정보에 근거하여 상기 녹음된 음향 정보에 대응되는 키워드를 추출할 수 있다. 한편 상기 S302 단계에서, 현재 녹음된 음향 정보에 대한 키워드가 추출되면, 제어부(180)는 상기 추출된 키워드에 대응되는 이미지 정보를 생성할 수 있다(S306). 그리고 이러한 이미지 정보는 상기 녹음된 음향 정보의 유형에 따라 결정될 수 있다. 예를 들어 상기 음향 정보가 복수의 사람 목소리를 포함하는 형태인 경우라면 제어부(180)는 상기 사람들의 목소리에 대응되는 그래픽 객체(예를 들어 말풍선)를 포함하는 이미지 정보를 생성할 수 있다. 또는 상기 음향 정보가 멜로디인 경우라면, 제어부(180)는 상기 멜로디에 대응되는 그래픽 객체(예를 들어 오선지, 및 복수의 음표)들을 포함하는 이미지 정보를 생성할 수 있다. 여기서 상기 이미지 정보는, 적어도 하나의 서로 다른 그래픽 객체를 포함할 수 있으며, 상기 그래픽 객체는, 각각 서로 다른 음향 신호의 발생 주체의 개수를 반영할 수 있다. 예를 들어 상기 녹음된 음향 정보가 복수의 사람들의 목소리를 포함하는 경우라면, 상기 이미지 정보에 포함되는 그래픽 객체는 상기 목소리의 주체, 즉 사람들의 수만큼 표시될 수 있다. 이에 따라 만약 상기 음향 정보가, 두 사람의 회의 내용을 녹음한 경우라면, 상기 제어부(180)는 두 개의 말풍선을 포함하는 이미지 정보가 생성될 수 있다. 한편 이러한 이미지 정보가 생성되면, 제어부(180)는 상기 생성된 이미지 정보와 상기 키워드를 이용하여 상기 녹음된 음향 정보에 대응되는 태그 정보를 생성할 수 있다(S308). 예를 들어 상술한 바와 같이, 상기 음향 정보가, 두 사람의 회의 내용을 녹음한 경우라면, 상기 제어부(180)는 두 개의 말풍선을 포함하는 이미지 정보와, 상기 회의 내용에 대응되는 키워드(예를 들어 ‘특허 미팅’)를 상기 녹음된 음향 정보에 대응되는 태그 정보로서 생성할 수 있다. 그리고 상기 태그 정보를 상기 녹음된 음향 정보에 대응되게 디스플레이부(151) 상에 표시할 수 있다. 이처럼 녹음된 음향 정보에 대한 태그 정보가 생성 및, 상기 태그 정보가 디스플레이부(151) 상에 표시되는 예를 하기 도 6을 참조하여 살펴보기로 한다. 이처럼 녹음된 음향 정보에 대응되는 태그 정보가 표시되면, 제어부(180)는 사용자의 선택에 따른 음향 정보를 재생할 수 있다. 이러한 경우 제어부(180)는 상기 사용자의 선택에 따라 상기 녹음된 음향 정보의 전체 뿐만 아니라 일부를 재생할 수도 있음은 물론이다(S310). 도 4는 이러한 본 발명의 실시 예에 따른 음향 정보 녹음 장치에서, 사용자에 의해 선택된 음향 정보가 재생되는 동작 과정, S310 단계를 보다 자세하게 도시한 것이다. 도 4를 참조하여 살펴보면, 본 발명의 실시 예에 따른 음향 정보 녹음 장치(100)의 제어부(180)는 사용자로부터 재생될 음향 정보가 선택되는 경우, 선택된 음향 정보의 전체 또는 일부의 재생을 선택받기 위한 메뉴 화면을 표시할 수 있다(S400). 그리고 제어부(180)는 사용자가 상기 선택된 음향 정보의 일부 재생을 선택하였는지를 감지할 수 있다(S402). 그리고 사용자가 상기 음향 정보의 전체 재생을 선택한 경우, 상기 녹음된 음향 정보의 전체를 재생할 수 있다(S406). 한편 만약 사용자가 상기 S402 단계에서 음향 정보의 일부 재생을 선택한 경우, 제어부(180)는 사용자로부터 상기 녹음된 음향 정보의 일부 재생을 위한 기준을 선택받을 수 있다, 이러한 경우 상기 선택된 기준과 관련된 복수의 그래픽 객체가 디스플레이부(151) 상에 표시될 수 있다. 그리고 상기 표시된 그래픽 객체를 통해 선택된 기준에 따라 상기 녹음된 음향 정보의 일부를 재생할 수 있다(S404). 예를 들어 제어부(180)는 사용자로부터 특정 음향 신호의 발생 주체를 상기 일부 재생을 위한 기준으로 선택받을 수 있다. 즉, 상기 도 2의 (c)에서 보이고 있는 것처럼, 제어부(180)는 상기 선택된 음향 정보를 분석한 결과에 근거하여 각 음향 신호의 발생 주체별로 또는, 기 설정된 구분 기준에 따라 구분된 상태를 적어도 하나의 그래픽 객체를 이용하여 표시할 수 있다. 그리고 상기 구분된 상태에 대응되는 적어도 하나의 그래픽 객체에 대한 사용자의 선택에 근거하여 상기 음향 정보의 일부에 대응되는 음향 정보를 재생할 수 있다. 이에 따라 본 발명에서는, 상기 녹음된 음향 정보가, 복수의 사람 목소리를 포함하는 경우, 사용자의 선택에 따라 특정 사람의 목소리만을 추출하여 재생되도록 할 수 있다. 또한 이와 유사하게, 상기 녹음된 음향 정보가 멜로디인 경우, 상기 멜로디를 연주한 악기들 중 특정 악기에 대한 음향 정보만이 선택적으로 재생되도록 할 수도 있다. 한편 이와는 달리, 제어부(180)는 어느 하나의 음향 정보가 선택되는 경우, 사용자의 정서 상태 또는 사용자의 위치 감지 결과를 상기 일부 재생을 위한 기준으로 선택받을 수도 있다. 이러한 경우 제어부(180)는 상기 음향 정보가 녹음되는 동안 판단된 사용자의 정서 상태 또는 사용자의 위치 정보에 대응되는 그래픽 객체들을 디스플레이부(151) 상에 표시할 수 있다. 그리고 제어부(180)는 특정 정서 상태 또는 특정 위치를 상기 그래픽 객체를 통해 사용자로부터 선택받을 수 있다. 이러한 경우 본 발명의 실시 예에 따른 음향 정보 녹음 장치(100)에서는 사용자가 특정 정서 상태에 있거나 또는 사용자가 특정 위치에 있을 때에 녹음된 일부 구간의 음향 정보가 재생될 수도 있다. 한편, 제어부(180)는 상기 음향 정보에 포함된 복수의 단어들을 기준으로 일부의 음향 정보가 재생되도록 할 수도 있음은 물론이다. 예를 들어 제어부(180)는 상기 S302 단계의 분석 결과, 기 설정된 횟수 이상 반복되는 단어에 대응되는 적어도 하나의 그래픽 객체들을 디스플레이부(151) 상에 표시할 수 있다. 그리고 제어부(180)는 상기 단어들 중 어느 하나가 선택되면, 상기 녹음된 음향 정보 중, 상기 선택된 단어에 대응되는 음향 신호가 포함된 일정 구간(예를 들어 상기 단어에 대응되는 음향 신호가 녹음된 시점을 기준으로 전후 각 5초에 대응되는 구간)이 재생되도록 할 수도 있다. 이에 따라 본 발명에서는 사용자가 상기 음향 정보로부터 특정 사람의 목소리나, 특정 악기 또는 자신의 특정 정서 상태나 자신의 위치 또는 특정 단어들을 기준으로 필요한 부분만을 청취할 수 있도록 한다. 이하 도 7a, 도 7b, 도 7c, 및 도 7d를 참조하여, 사용자로부터 상기 녹음된 음향 정보의 일부를 재생하기 위한 기준을 선택받는 예를 보다 자세히 살펴보기로 한다. 한편, 본 발명의 실시 예에 따른 음향 정보 녹음 장치(100)의 제어부(180)는 상기 녹음된 음향 정보의 분석 결과를 이용하여, 사용자로부터 입력되는 검색 정보에 따라 상기 음향 정보에 대한 검색을 수행할 수도 있다. 이러한 경우 제어부(180)는 키워드 뿐만 아니라, 특정 악기나 특정 사람, 또는 특정 정서 상태, 또는 녹음된 멜로디등에 근거하여 기 녹음된 음향 정보들에 대한 검색을 수행할 수도 있다. 도 5는 본 발명의 실시 예에 따른 음향 정보 녹음 장치에서, 입력된 검색 정보에 따라 음향 정보가 검색되는 동작 과정을 도시한 것이다. 도 5를 참조하여 살펴보면, 본 발명의 실시 예에 따른 음향 정보 녹음 장치(100)의 제어부(180)는 사용자로부터 입력된 검색 정보의 유형을 인식한다(S500). 여기서 상기 검색 정보는 사용자로부터 입력되는 문자열일 수 있으며, 또는 사용자의 제어에 따라 녹음된 음향 정보(예를 들어 멜로디)일 수 있다. 또는 사용자의 특정 정서 상태나, 대화에 참여한 사람 수에 대한 정보일 수도 있다. 제어부(180)는 S500 단계에서, 상기 입력된 검색 정보에 유형을 인식한 결과에 따라 기 저장된 음향 정보들을 정렬할 수 있다(S502). 예를 들어 제어부(180)는 상기 입력된 검색 정보가 문자열인 경우, 키워드를 중심으로 상기 기 저장된 음향 정보들을 정렬할 수 있으며, 상기 입력된 검색 정보가 녹음된 멜로디인 경우, 상기 음향 정보들 중 멜로디를 포함하는 음향 정보들만을 추출할 수도 있다. 또는 제어부(180)는 상기 입력된 검색 정보가, 사용자의 정서 상태나 또는 사용자의 위치 정보인 경우, 상기 기 저장된 음향 정보들을 사용자의 정서 상태 또는 위치 정보에 따라 정렬할 수 있다. 예를 들어 제어부(180)는 상기 음향 정보들 각각을 지배적인 정서 상태에 따라 정렬할 수 있다. 여기서 지배적인 정서 상태라는 것은, 상기 음향 정보들이 녹음되는 동안 가장 많은 시간 동안 감지된 사용자의 정서 상태를 의미할 수 있다. 즉, 예를 들어 10분 길이에 해당되는 음향 정보를 녹음할 당시에 판단된 사용자의 정서 상태가 ‘즐거운 상태’가 8분, ‘우울한 상태’가 2분인 경우, 상기 음향 정보에 대응되는 지배적인 사용자의 정서 상태는 ‘즐거운 상태’가 될 수 있다. 이와 유사하게 제어부(180)는 음향 정보가 녹음되는 동안 사용자의 위치가 변경된 경우, 가장 많은 시간동안 감지된 사용자의 위치를 기준으로 상기 음향 정보에 대응되는 사용자의 주요 위치를 결정할 수 있다. 그리고 제어부(180)는 상기 지배적인 정서 상태 또는 사용자의 주요 위치에 따라 상기 기 저장된 음향 정보들을 정렬할 수 있다. 이처럼 기 저장된 음향 정보들이 정렬되면, 제어부(180)는 상기 정렬된 음향 정보들로부터 상기 검색 정보에 대응되는 부분을 포함하는 음향 정보들을 추출 및 표시할 수 있다(S504). 이에 따라 제어부(180)는 사용자가 선택한 검색 정보(키워드, 사람 수, 악기, 정서 상태 또는 위치 등)에 대응되는 부분을 적어도 일부 포함하는 음향 정보가 검색되어 디스플레이부(151) 상에 표시될 수 있다. 한편, 제어부(180)는 음성 인식 기능을 이용한 인물 검색 기능을 제공할 수도 있음은 물론이다. 예를 들어 제어부(180)는 특정 인물의 음성에 대한 음성 인식이 가능한 경우, 메모리(170)에 기 저장된 프로파일 정보 또는 인명록이나 전화번호부 등으로부터 상기 인식된 음성에 대한 인물의 이미지를 검색할 수 있다. 이러한 경우 제어부(180)는 사용자로부터 전화번호부 또는 인명록이나 프로파일 정보등에서 추출된 인물의 이미지 정보들 중 어느 하나를 사용자로부터 상기 검색 정보로 입력받을 수 있다. 그리고 사용자로부터 특정 인물이 선택되는 경우, 그 인물의 음성이 녹음된 음향 정보를 검색하여 상기 디스플레이부(151) 상에 표시할 수도 있음은 물론이다. 한편 이상의 설명에서는 본 발명의 실시 예에 따른 음향 정보 녹음 장치(100)의 동작 과정을 흐름도를 참조하여 자세하게 살펴보았다. 이하의 설명에서는 본 발명의 실시 예에 따른 음향 정보 녹음 장치(100)에서, 본 발명의 실시 예에 따라 녹음된 음향 정보를 표시하는 예 및 녹음된 음향 정보가 재생 또는 검색되는 예를 예시도를 참조하여 보다 자세하게 살펴보기로 한다. 이하의 설명에서, 본 발명의 실시 예에 따른 음향 정보 녹음 장치(100)는 스마트 폰과 같은 이동 단말기임을 가정하여 설명하기로 한다. 그러나 본 발명이 이에 한정되는 것이 아님은 물론이다. 즉, 본 발명은스마트 폰이 아니라 다른 이동 단말기에서도 얼마든지 구현될 수 있음은 물론이며, 이동 단말기 뿐만 아니라 고정 단말기에서도 구현될 수 있음은 무론이다. 도 6은 본 발명의 실시 예에 따른 음향 정보 녹음 장치에서, 녹음된 음향 정보가 이미지 정보와 함께 표시되는 예를 도시한 예시도이다. 본 발명의 실시 예에 따른 음향 정보 녹음 장치(100)는 사용자의 제어에 따라 수신되는 음향 정보를 녹음할 수 있다. 도 6의 (a)는 이러한 경우에 본 발명의 실시 예에 따른 음향 정보 녹음 장치(100)의 디스플레이부(151) 상에 표시되는 화면의 예를 보이고 있는 것이다. 이러한 경우 제어부(180)는 도 6의 (a)에서 보이고 있는 것과 같이, 녹음되는 음향 정보의 주파수 파형 등에 관련된 그래픽 객체(600)를 디스플레이부(151) 상에 표시할 수 있으며, 이와 더불어, 사용자가 녹음되는 음향 정보의 볼륨을 조정할 수 있도록 볼륨 조절과 관련된 그래픽 객체(602)를 디스플레이부(151) 상에 표시할 수도 있다. 그리고 이처럼 음향 정보가 녹음되는 경우 제어부(180)는 사용자의 정서 상태나 위치등 다양한 관련 정보를 함께 감지할 수도 있음은 물론이다. 한편 이처럼 음향 정보가 녹음되면, 제어부(180)는 녹음된 음향 정보를 분석할 수 있다. 이러한 경우 제어부(180)는 도 6의 (b)에서 보이고 있는 것과 같이 상기 녹음된 음향 정보에 대해 분석된 결과에 관련된 화면(610)를 디스플레이부(151) 상에 표시할 수도 있다. 이 경우 상기 결과 화면(610)에는 현재 음향 정보로부터 추출된 키워드 및 상기 음향 정보로부터 인식된 음향 신호 발생 주체(agent)의 수 등이 표시될 수 있다. 예를 들어 상기 음향 정보가 두 명의 사람이 회의를 하던 중에 녹음된 경우, 제어부(180)는 상기 녹음된 내용에 따라 키워드를 ‘Meeting'으로 추출할 수 있으며, 음향 신호의 주체로서 ‘2명의 사람(2 People)’을 인식하여 표시할 수 있다. 도 6의 (b)는 이러한 예를 보이고 있는 것이다. 한편 상기 결과 화면(610)은, 상기 음향 신호의 주체를 표시하기 위한 방식을 사용자로부터 선택받을 수 있다. 예를 들어 상기 음향 신호의 주체가 2명의 사람인 경우라면, 제어부(180)는 사용자에게 도 6의 (b)에서 보이고 있는 것과 같이, 말풍선 모양의 그래픽 객체들(612), 사람 인물 모양의 그래픽 객체들(614), 서로 다른 사람의 목소리에 대응되는 복수의 파형을 포함하는 그래픽 객체(616) 중 어느 하나를 사용자로부터 선택받을 수 있다. 여기서 상기 그래픽 객체들은 상기 음향 신호의 행위 주체의 개수를 반영할 수도 있음은 물론이다. 즉, 상기 도 6의 (b)에서 보이고 있는 것과 같이 주체가 2인 경우, 말풍선이나 인물 이미지 또는 주파수 파형이 2개로 표시될 수 있으나, 상기 목소리의 주체가 한 명이거나, 또는 세 명 이상인 경우 이에 따라 하나 또는 셋 이상의 말 풍선, 인물 모양의 이미지, 또는 주파수 파형을 포함하는 그래픽 객체가 디스플레이부(151) 상에 표시되고, 사용자로부터 선택될 수 있음은 물론이다. 한편 이러한 그래픽 객체들(612, 614, 616) 중 어느 하나가 사용자로부터 선택되는 경우, 제어부(180)는 상기 사용자로부터 선택된 방식에 따라 상기 녹음된 음향 정보에 대응되는 이미지 정보를 생성할 수 있다. 도 6의 (c) 및 (d)는 이러한 경우의 예를 보이고 있는 것이다. 즉, 도 6의 (b)에서 보이고 있는 것과 같이, 사용자가 말풍선 모양의 그래픽 객체(612)를 선택하는 경우, 제어부(180)는 말풍선 모양의 그래픽 객체를 적어도 하나 포함하는 이미지 정보를 생성할 수 있다. 그리고 상기 추출된 키워드 'Meeting'와 상기 생성된 이미지 정보를 포함하는 태그 정보(622)를 생성하여 현재 녹음된 음향 정보에 대응되도록 표시할 수 있다. 도 6의 (c)는 이러한 경우의 예를 보이고 있는 것이다. 한편, 도 6의 (c)에서 보이고 있는 것과 같이 표시하는 것 외에, 제어부(180)는 상기 음향 정보가 녹음된 볼륨 레벨을 표시하기 위한 별도의 그래픽 객체(볼륨 그래픽 객체)를 더 표시할 수 있다. 이러한 경우 제어부(180)는 생성된 태그 정보의 주변에 볼륨 그래픽 객체를 표시할 수 있으며, 상기 볼륨 그래픽 객체들은 음향 정보의 녹음 볼륨 레벨에 따라 서로 다른 형태로 표시될 수 있다. 즉, 도 6의 (d)에서 보이고 있는 것처럼, 제1 태그 정보(622)와 제2 태그 정보(624)에 각각 대응되는 볼륨 그래픽 객체들(632, 634)이 서로 다른 경우, 이는 상기 제1 태그 정보(622)와 제2 태그 정보(624)에 대응되는 음향 정보의 녹음 볼륨 레벨이 서로 다른 것을 표시할 수 있다. 이에 따라 도 6의 (d)와 같이 표시되는 경우, 사용자는 제1 태그 정보(622)에 대응되는 음향 정보보다 제2 태그 정보(624)에 대응되는 음향 정보의 녹음 볼륨 레벨이 더 큰 것을 인식할 수 있다. 한편 도 7a, 도 7b, 도 7c 및 도 7d는 본 발명의 실시 예에 따른 음향 정보 녹음 장치에서, 녹음된 음향 정보의 일부분에 대응되는 그래픽 객체가 표시되고, 그에 따라 상기 녹음된 음향 정보의 일부의 재생이 선택되는 예를 도시한 예들이다. 우선 도 7a는 사용자가, 기 저장된 음향 정보들 중, 미팅 또는 회의 중에 녹음된 음향 정보의 일부 재생을 선택하는 경우를 보이고 있는 것이다. 예를 들어 도 7a의 (a)에서 보이고 있는 것과 같이, 사용자가 미팅 또는 회의 중에 녹음된 음향 정보를 선택하는 경우, 즉 복수의 사람 목소리를 포함하는 음향 정보를 선택하는 경우, 제어부(180)는 도 7a의 (b)에서 보이고 있는 것과 같이 상기 선택된 음향 정보의 전체 또는 일부를 선택받기 위한 메뉴 화면(710)을 표시할 수 있다. 그리고 만약 상기 메뉴 화면(710)에서 사용자가 일부(A part of all)의 재생을 선택하는 경우라면, 제어부(180)는 상기 음향 정보로부터 인식되는 각 주체들, 즉 사람들에 각각 대응되는 그래픽 객체들(720, 722, 724)을 디스플레이부(151) 상에 표시할 수 있다. 여기서 상기 그래픽 객체들(720, 722, 724)은 각각 서로 다른 음향 신호의 주체에 대응될 수 있다. 즉, 현재 선택된 음향 정보가 세 사람(사람 A, 사람 B, 사람 C)의 목소리가 포함된 것이라면, 제어부(180)는 각각의 목소리의 주체에 따라 서로 다른 3개의 그래픽 객체들(720, 722, 724)을 디스플레이부(151) 상에 표시할 수 있다. 이러한 경우 제어부(180)는 어느 하나의 그래픽 객체를 사용자로부터 선택받을 수 있으며, 도 7a의 (b)에서 보이고 있는 것과 같이 제1 그래픽 객체(720)가 선택되면 제어부(180)는 상기 제1 그래픽 객체(720)에 대응되는 주체, 즉 사람 A의 목소리만을 상기 음향 정보로부터 추출하여 재생할 수 있다. 한편 도 7b는 사용자의 정서 상태가 이미지 정보로 표시되는 그래픽 객체가 선택되는 예를 보이고 있는 것이다. 이러한 경우 제어부(180)는 도 7b의 (b)에서 보이고 있는 것과 같이 상기 선택된 음향 정보의 전체 또는 일부를 선택받기 위한 메뉴 화면(710)을 표시할 수 있다. 그리고 만약 상기 메뉴 화면(710)에서 사용자가 일부(A part of all)의 재생을 선택하는 경우라면, 제어부(180)는 상기 음향 정보가 녹음되는 동안 인식된 사용자의 정서 상태들에 각각 대응되는 그래픽 객체들(730, 732, 734)을 디스플레이부(151) 상에 표시할 수 있다. 이러한 경우 제어부(180)는 어느 하나의 그래픽 객체를 사용자로부터 선택받을 수 있다. 그리고 도 7b의 (b)에서 보이고 있는 것과 같이 제2 그래픽 객체(732)가 선택되면, 제어부(180)는 상기 제2 그래픽 객체(732)에 대응되는 사용자의 정서 상태, 즉 사용자의 상태가‘즐거움’상태에 매칭되는 상기 음향 정보의 일부의 구간만을 추출하여 재생할 수 있다. 한편 도 7c는 사용자가, 기 저장된 음향 정보들 중, 멜로디를 녹음한 음향 정보의 일부 재생을 선택하는 경우를 보이고 있는 것이다. 예를 들어 도 7c의 (a)에서 보이고 있는 것과 같이, 사용자가 멜로디가 녹음된 음향 정보를 선택하는 경우, 제어부(180)는 도 7c의 (b)에서 보이고 있는 것과 같이 상기 선택된 음향 정보의 전체 또는 일부를 선택받기 위한 메뉴 화면(710)을 표시할 수 있다. 그리고 만약 상기 메뉴 화면(710)에서 사용자가 일부(A part of all)의 재생을 선택하는 경우라면, 제어부(180)는 상기 음향 정보로부터 인식되는 각 주체들에 대응되는 그래픽 객체들(740, 742, 744)을 디스플레이부(151) 상에 표시할 수 있다. 여기서 상기 음향 신호의 주체는 악기가 될 수 있으며, 이에 따라 도 7c의 (b)에서 보이고 있는 것과 같이 각기 서로 다른 악기에 대응되는 그래픽 객체들(740, 742, 744)이 디스플레이부(151) 상에 표시될 수 있다. 이러한 경우 제어부(180)는 어느 하나의 그래픽 객체를 사용자로부터 선택받을 수 있다. 그리고 도 7c의 (b)에서 보이고 있는 것과 같이 제1 그래픽 객체(740)가 선택되면 제어부(180)는 상기 제1 그래픽 객체(740)에 대응되는 주체, 즉 악기 A에 대응되는 소리만을 상기 음향 정보로부터 추출하여 재생할 수 있다. 한편 도 7d는 목록 형태의 이미지 정보에 대응되는 음향 정보가 선택되는 예를 보이고 있는 것이다. 예를 들어 제어부(180)는 녹음된 음향 정보의 분석 결과, 기 설정된 횟수 이상 반복되는 단어들 또는 사용자가 미리 지정한 중요 단어가 상기 음향 정보에 포함되어 있는 경우, 도 7d의 (a)에서 보이고 있는 것처럼, 목록 형태의 이미지 정보를 생성할 수 있다. 그리고 제어부(180)는 상기 기 설정된 횟수 이상 반복된 단어들 또는 사용자가 미리 지정한 특정 단어가 포함된 구간들만을 음향 정보로부터 추출하여 재생할 수도 있다. 도 7d의 (b)는 이러한 예를 보이고 있는 것이다. 즉, 도 7d의 (b)에서 보이고 있는 것처럼, 제어부(180)는 선택된 음향 정보의 전체 또는 일부를 선택받기 위한 메뉴 화면(710)을 표시할 수 있다. 그리고 만약 상기 메뉴 화면(710)에서 사용자가 일부(A part of all)의 재생을 선택하는 경우라면, 제어부(180)는 상기 음향 정보로부터 인식되는 특정 단어들(750)을 디스플레이부(151) 상에 표시할 수 있다. 이러한 경우 제어부(180)는 상기 단어들 중 어느 하나를 사용자로부터 선택받을 수 있으며, 사용자로부터 어느 하나의 단어가 선택되는 경우, 선택된 단어에 대응되는 음향 신호의 재생 시점을 기준으로 상기 음향 정보의 일부 구간이 추출 및 재생될 수 있다. 이러한 경우 예를 들어 상기 사용자로부터 선택된 단어에 대응되는 음향 정보의 재생 시점을 전후로 기 설정된 시간(예를 들어 전후 각 5초)에 대응되는 구간들이 재생될 수 있다. 이에 따라 본 발명에서는 사용자에 의해 미리 설정되거나, 중요한 단어(예를 들어 기 설정된 횟수 이상 반복)의 경우, 해당 단어를 포함하는 음향 정보의 일부 구간들만을 선택적으로 사용자가 청취할 수 있다. 한편 도 8은 본 발명의 실시 예에 따른 음향 정보 녹음 장치에, 사용자에 의해 입력되는 검색 정보의 예를 도시한 것이다. 도 8을 참조하여 살펴보면, 도 8은 사용자가 입력할 수 있는 다양한 검색 정보의 예를 보이고 있다. 예를 들어 상기 검색 정보는 도 8의 (a)에서 보이고 있는 것과 같이 텍스트 정보일 수 있다. 이러한 경우 제어부(180)는 사용자로부터 입력된 텍스트 정보를 포함하는 기 저장된 음향 정보를 검색할 수 있다. 예를 들어 제어부(180)는 기 저장된 음향 정보의 키워드들 중 상기 검색 정보로 입력된 텍스트 정보를 포함하는 음향 정보를 검색할 수 있다. 또는 제어부(180)는 기 저장된 음향 정보의 VTT 결과 인식된 문자열 중에서 상기 검색 정보로 입력된 텍스트 정보를 포함하는 음향 정보를 검색할 수도 있다. 뿐만 아니라 특정인의 이름이나, 또는 특정 장소와 같은 명칭이 상기 텍스트 정보의 형태로 입력될 수도 있다. 이러한 경우 제어부(180)는 상기 입력된 텍스트 정보에 대응되는 특정인의 이름 또는 장소 명칭에 대응되는 음향 정보를 검색할 수도 있다. 이러한 경우 제어부(180)는 음향 정보와 관련된 정보로 함께 감지된 사용자의 위치 정보를, 상기 입력된 텍스트 정보와 비교하여, 상기 텍스트 정보에 대응되는 장소에서 녹음된 음향 정보를 검색할 수도 있음은 물론이다. 한편, 제어부(180)는 텍스트 정보 뿐만 아니라, 사용자의 제어에 따라 녹음된 음향 신호를 상기 검색 정보로 사용할 수도 있음은 물론이다. 도 8의 (b)는 이러한 예를 보이고 있는 것이다. 예를 들어 도 8의 (a)에서 보이고 있는 것과 같이, 제어부(180)는 사용자의 제어에 따라 입력되는 음향 신호를 녹음할 수 있다. 그리고 제어부(180)는 기 저장된 음향 정보들 중에서, 상기 녹음된 음향 신호를 포함하는 정보를 검색할 수 있다. 즉, 예를 들어 제어부(180)는, 상기 검색 정보로 녹음된 음향 신호가 일정한 리듬을 가지는 멜로디인 경우, 기 저장된 멜로디를 포함하는 음향 정보들 중에서, 상기 검색 정보에 해당되는 멜로디를 포함하는 음향 정보를 검색할 수 있다. 한편, 제어부(180)는 상기 녹음된 음향 신호를 VTT 인식한 결과를 이용할 수도 있음은 물론이다. 이러한 경우 제어부(180)는 상기 녹음된 음향 신호로부터 인식된 텍스트 정보를 이용하여 음향 정보를 검색할 수 있다. 여기서 상기 텍스트 정보를 이용하여 음향 정보를 검색하는 과정은, 상기 사용자로부터 직접 텍스트 문자를 입력받은 경우와 유사할 수 있다. 또한 제어부(180)는 사용자의 정서 상태를 기준으로 음향 정보를 검색할 수도 있음은 물론이다. 이러한 경우 제어부(180)는 도 8의 (c)에서 보이고 있는 것처럼, 사용자의 다양한 감정 상태에 각각 대응되는 그래픽 객체들을 포함하는 메뉴 화면(820)을 디스플레이부(151) 상에 표시할 수 있다. 그리고 기 저장된 음향 정보들 중, 사용자로부터 선택된 그래픽 객체에 대응되는 사용자의 감정 상태에서 녹음된 음향 정보를 검색할 수 있다. 예를 들어 제어부(180)는 기 저장된 음향 정보들 각각에 대해 지배적인 감정 상태를 판단하고, 상기 지배적인 감정 상태를 이용하여 상기 검색을 수행할 수 있다. 뿐만 아니라 제어부(180)는 음향 정보에 포함된 음향 신호의 주체의 개수를 기준으로 검색을 수행할 수도 있다. 여기서 상기 음향 신호의 주체는, 예를 들어 미팅 또는 회의와 같이 복수의 사람 목소리가 포함된 음향 정보의 경우에는 사람의 수가 될 수 있으며, 멜로디를 포함하는 음향 정보의 경우 상기 멜로디를 연주하는 악기가 될 수도 있다. 이러한 경우 제어부(180)는 음향 신호의 주체의 개수를 사용자로부터 선택받기 위한 메뉴 화면을 디스플레이부(151) 상에 표시할 수 있다. 즉, 예를 들어 사용자가 사람의 수를 선택하는 경우, 메뉴 화면(830)은 도 8의 (d)에서 보이고 있는 것과 같이, 각각 서로 다른 사람 수를 표시하는 그래픽 객체들을 포함하는 항목들을 포함할 수 있다. 즉, 도 8의 (d)에서 보이고 있는 것과 같이, 사람 모양의 그래픽 객체가 1개인 제1 항목(832)의 경우 한 사람을, 사람 모양의 그래픽 객체가 2개인 제2 항목(834)의 경우 두 사람을, 사람 모양의 그래픽 객체가 3개인 제3 항목(835)의 경우 세 사람을, 그리고 제4 항목(836)의 경우 네 사람 이상의 사람들을 표시하는 것일 수 있다. 이러한 경우에 만약 사용자가 상기 도 8의 (d)에서 보이고 있는 것과 같이 제2 항목(834)을 선택하는 경우 제어부(180)는 제 2 항목(834)에 대응되는 사람 수, 즉 두 사람의 목소리가 포함된 음향 정보를, 기 저장된 음향 정보들로부터 검색할 수 있다. 이에 따라 본 발명에서는 특정 수의 사람이 참석한 회의 또는 미팅에서 녹음된 음향 정보만을 보다 손쉽게 검색할 수 있다. 또한 이와 유사하게 제어부(180)는 특정 개수의 악기들로 연주되는 멜로디가 녹음된 음향 정보를 검색할 수도 있다. 한편 상술한 설명에서는, 상기 녹음된 음향 정보가 복수의 사람 목소리를 포함하고 있는 경우, ‘사람’별로 목소리를 추출하는 것만을 언급하였으나, 이 뿐만 아니라 상기 추출된 목소리를 인식하여 상기 목소리의 주체를 인식할 수도 있음은 물론이다. 예를 들어 제어부(180)는 상기 음향 정보로부터 추출된 사람의 음성을 인식하여, 상기 음성의 주체를 인식할 수 있다. 이러한 경우 제어부(180)는 기 저장된 인명록이나 전화번호부 또는 프로파일 정보등으로부터 상기 음성의 주체에 대응되는 이미지 정보를 검색하고, 상기 검색된 정보를 디스플레이부(151) 상에 표시할 수도 있음은 물론이다. 이러한 경우 본 발명에서는 대화 내용이 녹음되는 경우, 상기 대화 내용의 참가자들에 대한 이미지가 상기 녹음된 음향 정보에 대응되는 이미지 정보로 생성될 수 있으며, 이에 따라 사용자는 상기 이미지 정보를 이용하여 보다 쉽고 빠르게 상기 녹음된 음향 정보를 인식할 수 있다. 전술한 본 발명은, 프로그램이 기록된 매체에 컴퓨터가 읽을 수 있는 코드로서 구현하는 것이 가능하다. 컴퓨터가 읽을 수 있는 매체는, 컴퓨터 시스템에 의하여 읽혀질 수 있는 데이터가 저장되는 모든 종류의 기록장치를 포함한다. 컴퓨터가 읽을 수 있는 매체의 예로는, HDD(Hard Disk Drive), SSD(Solid State Disk), SDD(Silicon Disk Drive), ROM, RAM, CD-ROM, 자기 테이프, 플로피 디스크, 광 데이터 저장 장치 등이 있으며, 또한 캐리어 웨이브(예를 들어, 인터넷을 통한 전송)의 형태로 구현되는 것도 포함한다. 또한, 상기 컴퓨터는 단말기의 제어부(180)를 포함할 수도 있다. 따라서 상기의 상세한 설명은 모든 면에서 제한적으로 해석되어서는 아니되고 예시적인 것으로 고려되어야 한다. 본 발명의 범위는 첨부된 청구항의 합리적 해석에 의해 결정되어야 하고, 본 발명의 등가적 범위 내에서의 모든 변경은 본 발명의 범위에 포함된다. The present invention relates to an apparatus capable of recording audio information and a method for controlling the apparatus, the apparatus comprising: a display unit; an input unit for receiving an input of audio information; a detection unit for detecting at least one of a surrounding environment and a bio-signal; and a control unit for recording inputted audio information, extracting a keyword from the recorded audio information, generating image information on the basis of at least one of an analysis result of the recorded audio information and the detection result of the detection unit, and displaying tag information, in which the keyword and the image information are combined, so as to correspond to the recorded audio information. 디스플레이부; 음향 정보를 입력받는 입력부; 음향 정보를 출력하기 위한 출력부; 주변 환경 및 생체 신호 중 적어도 하나를 감지하기 위한 감지부; 및, 입력된 음향 정보를 녹음 및, 녹음된 음향 정보로부터 키워드를 추출하고, 상기 녹음된 음향 정보를 분석한 결과 및 상기 감지부의 감지 결과 중 적어도 하나에 근거하여 이미지 정보를 생성하며, 상기 키워드와 상기 이미지 정보가 결합된 태그 정보를 상기 녹음된 음향 정보에 대응되도록 표시하는 제어부를 포함하며, 상기 제어부는, 상기 녹음된 음향 정보에 포함된 음향 신호를 발생시키는 주체들을 인식하고, 상기 음향 신호를 발생시키는 주체 별로 구분되는 적어도 하나의 서로 다른 그래픽 객체를 상기 디스플레이부 상에 표시 및, 상기 그래픽 객체들 중 선택된 어느 하나에 대응되는 주체로부터 발생되는 음향 신호를 상기 녹음된 음향 정보로부터 추출하여 출력하는 것을 특징으로 하는 음향 정보 녹음 장치. 제1항에 있어서, 상기 그래픽 객체는, 상기 녹음된 음향 정보가 복수의 사람 목소리를 포함하는 경우, 적어도 하나의 사람 모양의 그래픽 객체, 또는 적어도 하나의 말풍선 모양의 그래픽 객체, 또는 적어도 하나의 주파수 파형 형태의 그래픽 객체이며, 상기 제어부는, 상기 사람 모양의 그래픽 객체, 또는 상기 말풍선 모양의 그래픽 객체 또는 상기 주파수 파형 형태의 그래픽 객체 중 어느 하나가 선택되는 경우, 선택된 그래픽 객체에 대응되는 사람의 목소리만을 상기 음향 정보로부터 추출하여 출력하는 것을 특징으로 하는 음향 정보 녹음 장치. 제1항에 있어서, 상기 제어부는, 상기 음향 정보에 포함된 복수의 음향 신호 중 고유 음색 및 특징에 따라 상기 음향 신호를 발생시키는 주체를 서로 구분하고, 상기 음향 신호를 발생시키는 주체는, 상기 음향 신호의 고유 음색 음색 및 특징에 따라 각각 구분되는 목소리 또는 연주음을 발생시키는 적어도 하나의 사람 또는 악기임을 특징으로 하는 음향 정보 녹음 장치. 제1항에 있어서, 상기 제어부는, 상기 음향 정보를 분석한 결과에 따라 상기 녹음된 음향 정보의 유형에 따라 상기 키워드를 추출하는 방식을 서로 다르게 결정하는 것을 특징으로 하는 음향 정보 녹음 장치. 제4항에 있어서, 상기 제어부는, 상기 음향 정보를 분석한 결과, 상기 음향 정보가 일정한 리듬을 가지는 멜로디를 포함하는 경우, 음악 검색을 통해 상기 멜로디의 제목을 상기 음향 정보의 키워드로 추출하는 것을 특징으로 하는 음향 정보 녹음 장치. 제4항에 있어서, 상기 제어부는, 상기 음향 정보를 분석한 결과, 상기 음향 정보가 적어도 한 명의 사람 음성을 포함하는 경우, VTT(Voice To Text) 과정을 통해 상기 녹음된 음향 정보의 내용을 문자열로 인식하고, 상기 인식된 문자열을 통해 상기 키워드를 추출하는 것을 특징으로 하는 음향 정보 녹음 장치. 제6항에 있어서, 상기 제어부는, 상기 인식된 문자열 중 기 설정된 횟수 이상 반복된 단어 또는 상기 반복된 단어들 중 가장 많이 반복된 단어를 상기 키워드로 추출하는 것을 특징으로 하는 음향 정보 녹음 장치. 제6항에 있어서, 상기 제어부는, 기 설정된 특정 단어 또는 어구가 상기 인식된 문자열에 포함되어 있는 경우, 상기 특정 단어 또는 어구를 상기 키워드로 추출하는 것을 특징으로 하는 음향 정보 녹음 장치. 제6항에 있어서, 상기 제어부는, 미리 입력된 적어도 하나의 단어가 상기 인식된 문자열에 포함되어 있는 경우, 상기 적어도 하나의 단어에 대응되는 대표 단어를 상기 키워드로 추출하는 것을 특징으로 하는 음향 정보 녹음 장치. 제1항에 있어서, 상기 제어부는, 상기 음향 정보가 녹음된 시각과, 현재의 위치를 감지한 결과, 상기 녹음 시각 및 현재의 위치에 매칭되는 기 저장된 일정 정보에 근거하여 상기 키워드를 추출하는 것을 특징으로 하는 음향 정보 녹음 장치. 제1항에 있어서, 상기 제어부는, 상기 음향 정보를 분석한 결과, 상기 녹음된 음향 정보의 유형에 따라 서로 다른 적어도 하나의 그래픽 객체를 포함하는 이미지 정보를 생성하며, 상기 음향 정보의 유형은, 상기 음향 정보가 복수의 사람 음성을 포함하고 있는지 또는 일정한 리듬을 가지는 멜로디를 포함하고 있는지 여부에 따라 결정되는 것을 특징으로 하는 음향 정보 녹음 장치. 제11항에 있어서, 상기 제어부는, 상기 녹음된 음향 정보가 복수의 사람 목소리를 포함하는 경우, 적어도 하나의 사람 모양의 그래픽 객체, 또는 적어도 하나의 말풍선 모양의 그래픽 객체, 또는 적어도 하나의 주파수 파형 형태의 그래픽 객체를 포함하는 상기 이미지 정보를 생성하는 것을 특징으로 하는 음향 정보 녹음 장치. 제12항에 있어서, 상기 제어부는, 상기 녹음된 음향 정보로부터 인식되는 목소리의 주체의 개수에 대응되는 개수의 상기 그래픽 객체를 포함하는 상기 이미지 정보를 생성하는 것을 특징으로 하는 음향 정보 녹음 장치. 제12항에 있어서, 상기 제어부는, 상기 녹음된 음향 정보에 포함된 복수의 사람 목소리 중 인식 가능한 목소리가 있는 경우, 해당 목소리에 대응되는 인물을 인식하고 인식된 인물에 대응되는 이미지를 상기 그래픽 객체로 표시하는 것을 특징으로 하는 음향 정보 녹음 장치. 제1항에 있어서, 상기 제어부는, 상기 음향 정보가 녹음되는 동안 상기 감지부의 감지 결과를 이용하여 사용자의 정서 상태를 판단하고, 상기 이미지 정보는, 상기 판단된 사용자의 정서 상태에 대응되는 그래픽 객체를 포함하는 것을 특징으로 하는 음향 정보 녹음 장치. 제1항에 있어서, 상기 제어부는, 음향 정보가 녹음되면 현재 위치를 감지하고, 상기 위치와 관련된 정보를 상기 키워드로 추출 및, 상기 감지된 위치에 대응되는 그래픽 객체를 포함하는 상기 태그 정보를 상기 녹음된 음향 정보에 대응되도록 표시하는 것을 특징으로 하는 음향 정보 녹음 장치. 제1항에 있어서, 상기 제어부는, 검색 정보가 입력되면, 입력된 검색 정보에 대응되는 부분을 포함하는 음향 정보를 검색하며, 상기 검색 정보는, 텍스트 정보, 녹음된 음향 정보, 사용자의 정서 상태, 현재의 위치 중 어느 하나임을 특징으로 하는 음향 정보 녹음 장치. 제17항에 있어서, 상기 검색 정보는, 사람 목소리의 개수에 대한 정보를 더 포함하며, 상기 제어부는, 복수의 사람 목소리를 포함하는 기 저장된 음향 정보들 중, 상기 검색 정보에 근거하여 특정 수의 사람 목소리만이 포함된 음향 정보들을 검색하는 것을 특징으로 하는 음향 정보 녹음 장치. 제1항에 있어서, 상기 이미지 정보는, 상기 음향 정보의 녹음 볼륨 레벨을 표시하기 위한 그래픽 객체를 포함하는 것을 특징으로 하는 음향 정보 녹음 장치. 음향 정보를 녹음하는 장치에 있어서, 음향 정보를 녹음하고, 상기 음향 정보 녹음 장치의 주변 환경 및 생체 신호를 적어도 하나 감지하는 단계; 상기 녹음된 음향 정보를 분석하여 키워드를 추출 및, 상기 음향 정보에 포함된 음향 신호의 발생 주체들을 인식하는 단계; 상기 감지된 주변 환경, 상기 감지된 생체 신호 및, 상기 인식된 음향 신호의 발생 주체들 중 적어도 하나를 이용하여 이미지 정보를 생성하는 단계; 상기 생성된 이미지 정보와 상기 추출된 키워드를 포함하는 태그 정보를 상기 녹음된 음향 정보에 대응되게 표시하는 단계; 및, 상기 태그 정보 중 어느 하나가 선택되면, 그에 대응되는 음향 정보를 출력하는 단계를 포함하며, 상기 음향 정보를 출력하는 단계는, 상기 인식된 음향 신호 발생 주체들 중 선택된 어느 하나에 대응되는 음향 신호를 상기 음향 정보로부터 추출하여 출력하는 단계를 포함하는 단계임을 특징으로 하는 음향 정보 녹음 장치의 제어 방법.