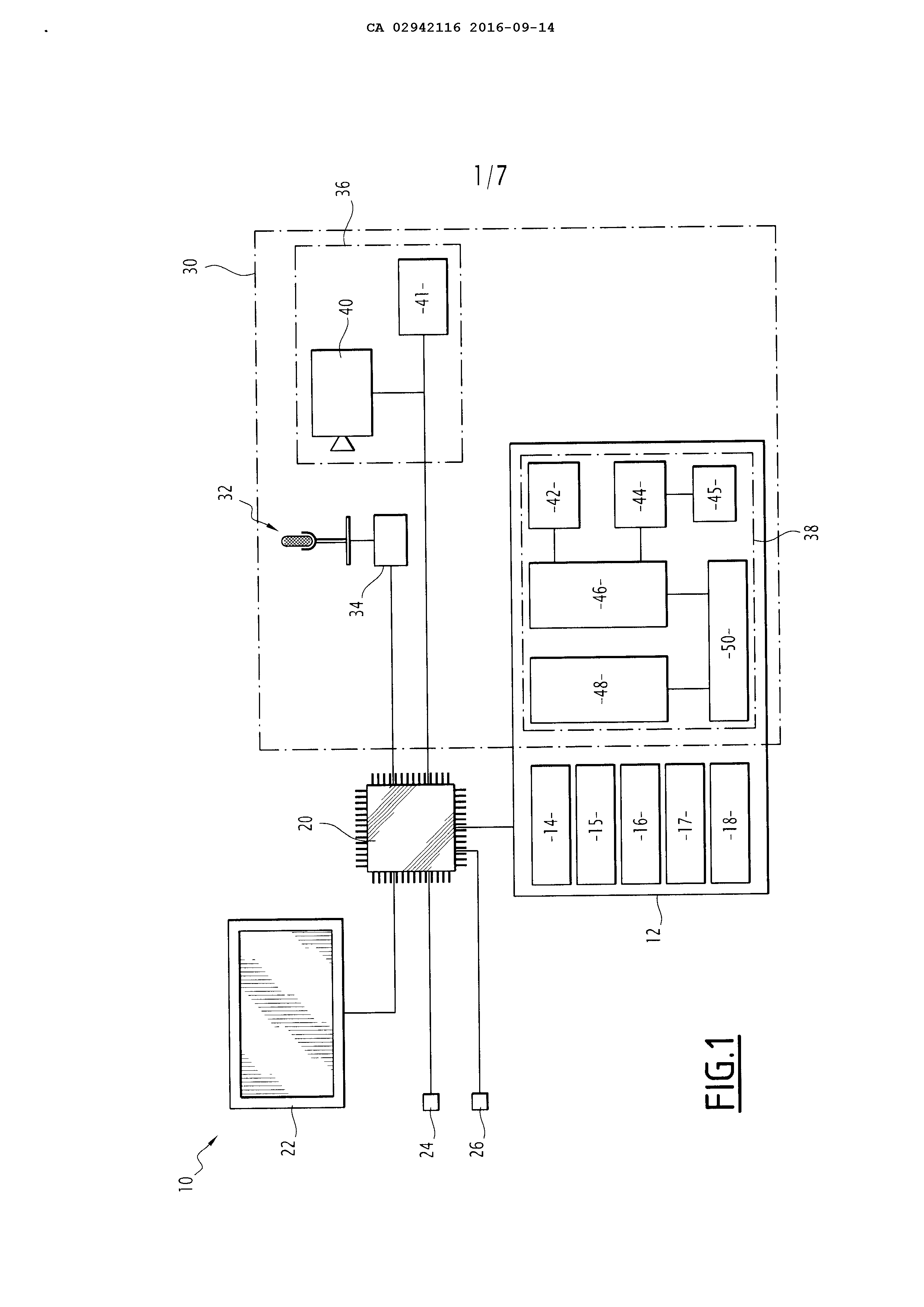
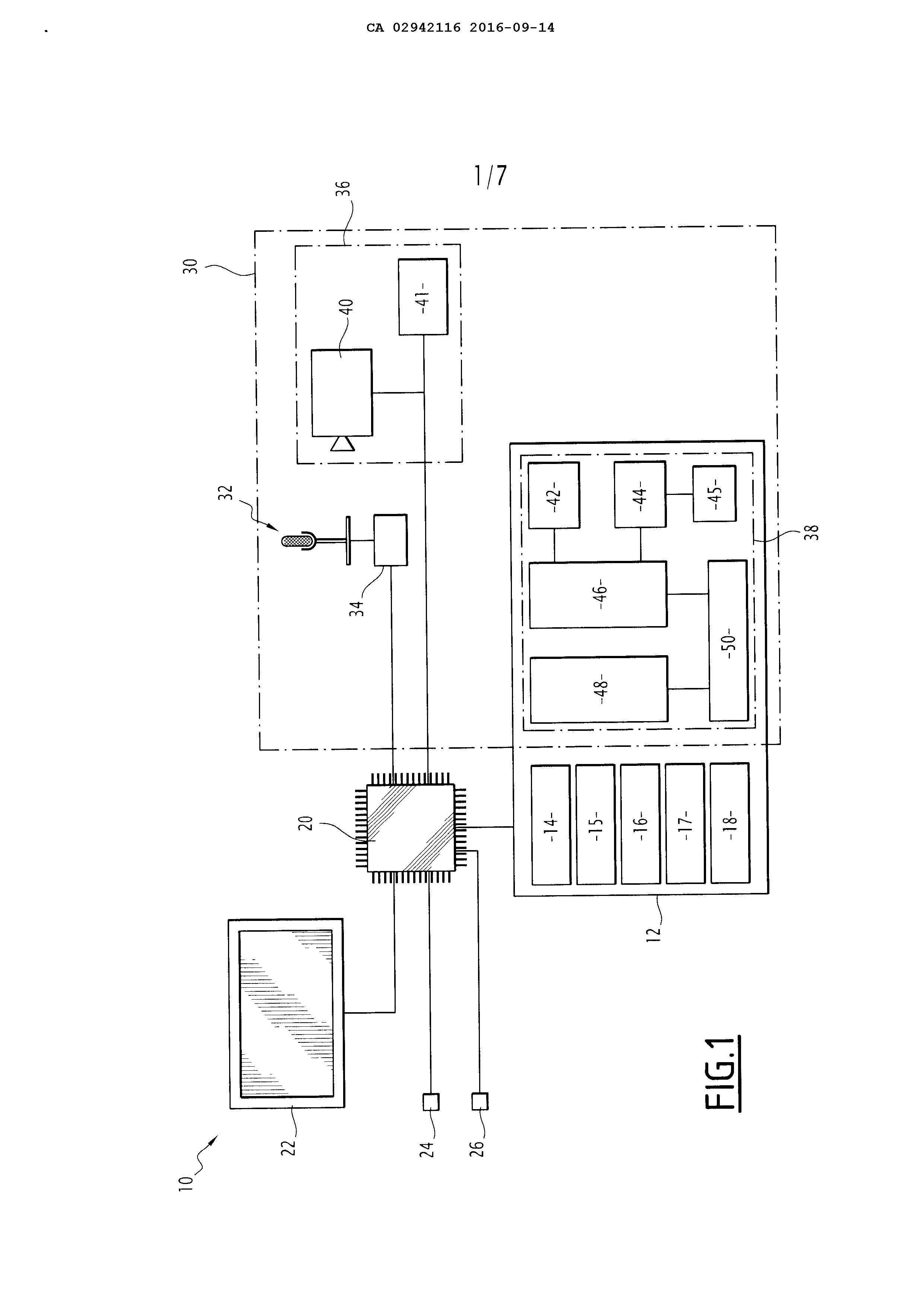
AUTOMATIC VOICE RECOGNITION WITH DETECTION OF AT LEAST ONE CONTEXTUAL ELEMENT, APPLICATION TO STEERING AND MAINTENANCE OF AN AIRCRAFT
Automatic speech recognition with detection of at least one contextual element, and applying piloting and maintenance of an aircraft The present invention relates to an automatic speech recognizer, of the type comprising an acquisition unit of an audio signal, a shaping member of the audio signal, the audio signal for cutting into frames, and a linguistic decoder for determining a spoken command corresponding to the audio signal, the decoder comprising language: at least one acoustic model defining a probability law acoustic for calculating, for each phoneme of a phoneme sequence, a probability for said acoustic phoneme and a corresponding frame of the audio signal match, and at least one template syntax defining a probability law syntax for computing, for each phoneme of a phoneme sequence analyzed using the acoustic model, a probability syntax for said phoneme follows the phoneme or phoneme group preceding said phoneme in the phoneme sequence. The invention also relates to a automatic voice recognition method implemented by a device of the aforementioned type. The information systems or control utilize increasingly voice interfaces for rendering the interaction with the user fast and intuitive. These speech interfaces devices employ automatic speech recognizer for recognizing the verbal instructions communicated to the information or control by the user. A problem encountered by designers of these devices for automatic speech recognition is to permit the use of a natural language while achieving a recognition rate be closest to 100%. Another problem is reaching a recognition rate be closest to 100% while for recognizing a large number of instructions. A solution for reconciling these objectives involves employing acoustic models very reliable for attaining a low error rate in the acoustic probability computation. This solution is typically the solution implemented in the automatic speech recognition devices modern PDAs and known in particular in the trade RSIS® and Cortana®. A disadvantage of this solution is that the acoustic models employed require the use of significant computational powers for the treatment of very large databases. This makes this solution hardly usable when moving about, in the absence of connection to a server having means for computing and memory necessary for the implementation of this solution, which may be the case in an aircraft. Another solution involves using automatic speech recognition devices with limited syntax, c'est to say for which the sentences recognizable lie in a predetermined set of capabilities. These recognition devices show a very good recognition rate even with acoustic models unreliable, and do not require powers is very important and big databases; they are thus very suitable for use when moving about. A disadvantage of these devices is however they do allow the recognition that a limited number of instructions. A third solution is disclosed in the document "DEYE/vocie task schedule interfaces (EVMPI)" (f in Hatfield, a.e. Jenkins and MW Robertson, December 1995). This solution is to modify the model syntax of the linguistic decoder of an automatic speech recognizer based on the gaze direction of the user. To this end, the automatic speech recognizer includes a detector for determining a gaze point set by the user is looking on a screen, and a fusion engine adapted to modify the probability distribution of the model syntax syntax based on information communicated by an application associated with the point set by the user is looking on the screen. This automatic speech recognizer thus recognize a large number of instructions, since it is capable of recognizing instructions associated with each of the applications displayed on the screen. This automatic speech recognizer allows at the same time good recognition rate, even with an acoustic model unreliable, since the model syntax employed at each instant to recognize the verbal instructions from the user's spoken has only a small vocabulary at single vocabulary of the application view by the user; there is thus low chance of confusion between two words to the pronunciation near. Recalculating the probability distribution and syntax in real time is however a complicated, difficult, slowed by the exchanges of information between the fusion engine and applications, and which prevents motor operation language while the recalculation is in progress. The result is an appreciable latency. Further, this solution is likely to cause significant error rate in the case where the user is not viewing in the direction of the relevant application by its instructions. A last solution is disclosed in the document FR's to-2 744,277. This solution is to modify the model syntax of the linguistic decoder of an automatic speech recognizer based on various parameters such as the parameters of the mobile carrier, the type and phase of the current mission or order history previously executed. This solution has the same disadvantages that the third solution described above. An object of the invention is thus allow automatic speech recognition of spoken commands on a large vocabulary, speech recognition reaching a recognition rate close to 100%, with low latency. Another object is that this voice recognition can be implemented autonomously by devices having a limited computational power while being very intuitive for the user and relevant on the operation plan. To this end, the invention relates to an automatic speech recognizer of the aforementioned type, wherein the voice recognition device comprises a detection device for detecting the state of at least one context, the syntactic patterns are at least two in number, and the linguistic decoder comprises: an algorithm for constructing oral instruction using the acoustic model and a plurality of individual active syntactic patterns among the syntactic patterns for constructing, for each active syntactic model, a phoneme sequence a candidate associated with said active syntactic model for which the probability of syntactic acoustic and different phonemes constituting said phoneme sequence candidate is maximum, a processor for selecting contextualization, depending on the state of the or each contextual detected by the detection device (36), at least one syntactic pattern selected from the plurality of active syntactic patterns, and a processor for determining the spoken command corresponding to the audio signal, to define the phoneme sequence a candidate associated with the model syntax selected or, in the case where several syntactic patterns are selected, the phoneme sequence, among the candidate phoneme sequence associated with the selected acoustic models, for which the probability of syntactic acoustic and different phonemes constituting said phoneme sequence is maximum, as constituting the spoken command corresponding to the audio signal. According to particular embodiments of the invention, the automatic voice recognition device also has one or more of the following characteristics, taken alone (O) (O) or in any combination (O) (O) technically possible: - the contextualization processor is adapted to: o-assigning, based on the state of the detected contextual element, order number to each model syntactical active, o-searching, syntactic patterns among the active, syntactic patterns candidates are assigned are candidate phoneme sequence for which the probability of syntactic acoustic and different phonemes constituting said candidate phoneme sequence is greater than a predetermined threshold, and o-select the model (e) (e) syntax (e) candidate having the number of highest order; - at least one contextual element is independent of the audio signal; - the automatic speech recognizer comprises a gaze detector adapted to detect the direction of a view of a user or a pointing sensor adapted for sensing the position of a pointing member such as a slider; - the automatic speech recognizer comprises a display device displaying objects, each model being associated with a syntactic respective object among the objects displayed, the processor being adapted to assign contextualization its order number to each template syntax according to the distance between the gaze direction of the user or the position of the pointer and the displayed object which is associated with said model syntax; - the linguistic decoder includes a processor activation modules syntactic to activate, depending on the state of the detected contextual element, a plurality of syntactic patterns forming the active syntactic patterns; - the linguistic decoder includes a processor disabling syntactic modules for deactivating, depending on the state of the detected contextual element, at least one template syntax among active syntactic patterns; and - the processor contextualization is adapted to automatically select the or each selected syntactic model. The invention also relates to a system for assisting in steering or servicing of an aircraft, comprising an automatic speech recognizer as defined above, and a command execution unit for the execution of the spoken command corresponding to the audio signal. According to a particular embodiment of the invention, the system for assisting in steering also has the following feature: - the detection device comprises a detector of flight phase of the aircraft or with a system state of the aircraft. The invention also relates to a method for automatic speech recognition for the determination of a spoken command corresponding to an audio signal, the method being implemented by an automatic speech recognizer comprising: at least one acoustic model defining a probability law acoustic for calculating, for each phoneme of a phoneme sequence, a probability for said acoustic phoneme and a corresponding frame of the audio signal match, and at least one template syntax defining a probability law syntax for computing, for each phoneme of a phoneme sequence analyzed using the acoustic model, a probability syntax for said phoneme follows the phoneme or phoneme group preceding said phoneme in the phoneme sequence, the syntactic patterns being at least two in number, and the method comprising the following steps: acquisition of the audio signal, detecting the state of at least one contextual element, activating a plurality of syntactic patterns forming active syntactic patterns, shaping the audio signal, said shaping comprising stamping the audio signal into frames, constructing, for each active syntactic model, using the acoustic model and said model syntactical active, a phoneme sequence of a candidate associated with said active syntactic model for which the probability of syntactic acoustic and different phonemes constituting said phoneme sequence candidate is maximum, selecting, based on the state of the contextual element, at least a selected one of the syntactic model active syntactic patterns, and definition of the phoneme sequence a candidate associated with the model syntax selected or, in the case where several syntactic patterns are selected, the phoneme sequence, among the candidate phoneme sequence associated with the selected syntactic patterns, for which the probability of syntactic acoustic and different phonemes constituting said phoneme sequence is maximum, as constituting the spoken command corresponding to the audio signal. According to preferred embodiments of the invention, the automatic voice recognition method also has one or more of the following characteristics, taken alone (O) (O) or in any combination (O) (O) technically possible: - the selecting step comprises the following substeps: o assignment, depending on the state of the detected contextual element, order number to each model syntactical active, o searching, syntactic patterns among the active, of syntactic patterns candidates are assigned are candidate phoneme sequence for which the probability of syntactic acoustic and different phonemes constituting said candidate phoneme sequence is greater than a predetermined threshold, and o selection of the one or more model (e) (e) syntax (e) candidate having the number of highest order; - at least one contextual element is independent of the audio signal; the context includes - a direction of a face of a user or a position of a pointing member such as a slider; - objects are displayed on a display device, each template syntax being associated with a respective object among the objects displayed, and the sequence number is assigned to each template syntax according to the distance between the gaze direction of the user or the position of the pointing member and the displayed object which is associated with said model syntax; - the gaze direction of the user consists of a gaze direction of the user at the end of the acquisition of the audio signal; - activation syntactic patterns comprises the following substeps: o-designation, depending on the state of the contextual element, a plurality of syntactic patterns designated among the syntactic patterns, and o-activating syntactic patterns designated; - the method includes a step of disabling at least one syntactic patterns among the syntactic model assets in accordance with contextual condition of the component; and - the selected syntactic model selection is performed automatically. The invention also relates to a method for assisting the piloting or servicing of an aircraft, implemented by a system for assisting in steering or by a system which assists the maintenance of said aircraft, said method comprising the following steps: determining, using an automatic voice recognition method as defined above, of an oral instruction corresponding to a recorded audio signal, and executing, by the assistance system, of the spoken command. According to a particular embodiment of the invention, the method of steering aid also has the following feature: the element comprises a contextual - flight phase of the aircraft or a system state of the aircraft. Other features and advantages of the invention will appear upon reading the description below, given solely by way of example and made with reference to the accompanying drawings, in which: figure 1 is a schematic representation of a system for assisting the piloting of an aircraft according to the invention, figure 2 is a block diagram illustrating a method for assisting the piloting of an aircraft implemented the system for assisting in steering of Figure 1, and figures 3 to 12 are examples of display on a display of the system of steering aid of Figure 1. Figures 3 to 12, the display screens are illustrative of a steering aid systems real aircraft, and are therefore in English language, according to the standard display in aircraft applications. Translation into French relevant indications are given in the description which follows. The assistance system 10, shown in Figure 1, is a system for assisting the piloting of an aircraft. It is typically integrated into the cockpit of an aircraft, or a ground station for remote monitoring of a drone. Alternatively (not shown), the assistance system 10 is a system for assisting the maintenance of an aircraft. In the assist system 10 comprises, in a known manner, a memory storing a plurality of applications 12 14, 15, 16, 17, 18, 20 a processor associated with the memory 12 for execution of applications 14, 15, 16, 17, 18, 22 and a display device for displaying information relating to the applications 14, 15, 16, 17, 18. the assistance system 10 also includes inlets and outlets 24 26 for exchanging data of the driver assistance system 10 with other equipment of the aircraft such as the motors, the flaps, the airbrakes, the probes, the radars, the geolocation system, andc. The applications 14, 15, 16, 17, 18 typically include: an application synoptic 14, adapted for retrieving information relating to the system state of the aircraft and present this information to the user in the form of diagrams displayed on the display device in a first window 22 (fig. 3) 14a when the application 14 is executed by the processor 20, an application speeds 15, adapted to control the speed of the aircraft and for displaying said rates on the display device in a second window 22 (fig. 3) 15a when the application 15 is performed by the processor 20, an application clock 16, adapted to manage the system clock 10 assistance and alarms programmed by the user when executed by the processor 20, but also for displaying said clock and said alarms on the display device 22 in a third window (fig. 6) 16a, 17 browsing application, adapted to retrieve information corresponding to the path followed by the aircraft and for displaying said information on the display device 22 in a fourth window 17a (fig. 10) when the application 17 is performed by the processor 20, and a management application display 18, adapted to manage the display of information on the display device 22 when executed by the processor 20. Optionally, the memory 12 also stores other applications (not shown) adapted to be executed by the processor 20 without displaying information on the display device 22 when executed by the processor 20. Addition execution of applications 14, 15, 16, 17, 18 mentioned, the processor 20 is also adapted to perform commands for the help system 10 and thus forms a control execution unit. The display device 22 is typically a screen. According to the invention, the assistance system 10 also includes an automatic speech recognizer 30 for the recognition of spoken commands for assistance system 10. This automatic speech recognizer unit 30 includes a 32 acquisition of an audio signal, a member 34 for shaping the audio signal, a device 36 for detecting the state of at least one contextual element, and a linguistic decoder 38. The acquisition unit 32 is adapted to generate an audio signal representative of a sound detected by the acquisition unit. To this end, the acquisition unit 32 is typically constituted by a microphone. The shaping member 34 is adapted to digitize the audio signal by sampling and cutting it into frames, overlapping or not, of the same duration or not. The shaping member 34 is typically formed by a programmable logic component or by a dedicated integrated circuit. The detection device 36 is adapted to detect the state of at least one contextual element, preferably a plurality of contextual elements. These contextual elements are elements which determine the context in which a spoken command is spoken by a user, and are in particular independent of the audio signal. These contextual elements typically include the direction of a user's gaze, the position of a pointing member on the display device 22, the flight phase of the aircraft or the system state of the aircraft. In the example illustrated, the detection device 36 thus includes a manhole 40 detector, adapted to detect the gaze direction of the user, and a phase detector 41 of flight of the aircraft. Alternatively or additionally, the sensor device 36 includes a detector (not shown) pointing, adapted to detect the position of a pointing member such as a cursor on the display device 22, and/or a status detector system of the aircraft (not shown). Each member is adapted to assume different contextual conditions associated with contextual element. A different state is thus associated: to the gaze direction of the user for each application window displayed on the display device 22 to which said viewing port can be oriented, and the viewing direction is assumed to be in this state when the gaze is directed toward said window; to the position of the pointing member for each application window displayed on the display device 22 that may point to the pointing member, and the position of the pointing member is assumed to be in said state when the pointing member tip toward said window; to the flight phase of the aircraft for each flight phase in which the aircraft may be, and the flight phase of the aircraft is assumed to be in said state when the aircraft is in said flight phase; and to the system state of the aircraft for each combination of conditions which may be present in the aircraft systems, and the system state of the aircraft is assumed to be in said state when the states aircraft systems form said combination. The linguistic decoder 38 42 includes an acoustic model, a plurality of syntactic patterns 44, an activation/deactivation 45 syntactic patterns 44, a construction algorithm 46 oral instruction, a processor and a processor 50 48 contextualization of determining a spoken command corresponding to the audio signal generated by the acquisition unit 32. The acoustic model 42 defines a probability law acoustic for calculating, for each phoneme of a phoneme sequence, a probability for said acoustic phoneme and a corresponding frame of the audio signal match. To this end, the acoustic model 42 includes a plurality of parameter vectors base, each said vector base parameter reflecting the respective phoneme acoustic fingerprint. Each model syntactical 44 defines a probability law syntax for computing, for each phoneme of a phoneme sequence analyzed using the acoustic model, a probability syntax for said phoneme follows the phoneme or phoneme group preceding said phoneme in the phoneme sequence. To this end, each model syntactical 44 includes a table associating to each phoneme probability thereof syntax according to different phoneme sequences, said probability syntactic typically being calculated using a statistical method called n-Grams, or a context-free defined by a set of rules described in the form called Backus-to-Naur (better known by the acronym BNF, English Backus-to-Naur eplerenone). Each model syntactical 44 is associated with a respective state of a contextual element or to a respective combination of conditions contextual elements. Each model syntactical 44 is also associated with a flight phase of the aircraft, to a system state of the aircraft, and/or application to 14, 15, 16, 17, 18. Activation/deactivation member 45 is adapted to activate certain syntactic patterns 44, the syntactic patterns forming activated active syntactic patterns, and to disable certain syntactic patterns active. Activation/deactivation member 45 is particularly adapted to activate the syntactic patterns 44 associated with the flight phase in which the aircraft is, to the system state of the aircraft, and/or applications 14, 15, 16, 17, 18 displayed on the display device 22, and to disable the syntactic patterns 44 associated with flight phases and conditions systems other than those in which the aircraft is, or associated with applications that are not displayed on the display 22. The algorithm for constructing spoken command 46 uses the acoustic model and the syntactic patterns active for constructing, for each active syntactic model, a phoneme sequence a candidate associated with said active syntactic model for which the probability of syntactic acoustic and different phonemes constituting said phoneme sequence candidate is maximum. To this end, the construction algorithm of oral instruction 46 is adapted to: associating with each frame a parameter vector that translates the acoustic information contained in the frame, for example by means of cepstral coefficients type MFCCs (abbreviation of the expression English "mel-Frequency Division detected cepstral coefficients"), searching, for each frame, using the probabilities syntax defined by the template syntax active, candidates phonemes associated with said frame, calculating, for each candidate phoneme, the distance of the vector of parameters associated with said candidate phoneme at 42 at the acoustic model parameter vector associated with the frame, so as to obtain the acoustic likelihood of the candidate phoneme, establishing sequences of candidate phonemes each formed of candidate phonemes associated with frames composing the acoustic signal, the order of the candidate phonemes in each sequence frames in sequence according to the acoustic signal, calculating, for each candidate sequence phonemes, a sequence probability equal to the product of the probabilities of different candidates syntactic and acoustic phoneme sequence component, and selecting the sequence of candidate phoneme sequence whose probability is maximum, said sequence of candidate phonemes constituting the phoneme sequence a candidate. The processor contextualization 48 is adapted to automatically select, c'est without specific operator action, depending on the state of the or each contextual detected by the detection device 40, the or each syntactic model which, among the plurality of active syntactic patterns, is assigned to the state or combination of states of the one or more member (e) (e) contextual (e) detected by the sensor 40. The at least one model (e) (e) syntactic form (s) a model (e) or (e) selected syntax (e). To this end, the processor contextualization is adapted to 48: allocating, based on the state of the detected contextual element, order number to each model syntactical active, searching, from among the active syntactic patterns, syntactic patterns candidates are assigned are candidate phoneme sequence whose sequence probability is above a predetermined threshold, and select the model (e) (e) syntax (e) candidate having the accession number of the highest order. Said sequence number is typically function, for the syntactic patterns 44 associated with gas 14, 15, 16, 17, of the distance between the eyes of a user or the position of the pointing member and the window 14 Α, Α 15, 16 Α, 17a of said application 14, 15, 16, 17, assigning sequence numbers for these syntactic patterns being performed to the inverse of the ranking distances windows 14 Α, Α 15, 16 Α, 17a to the viewing direction or the location of the pointer; in other words, the number of highest order is assigned at 44 syntactic model associated with the application 14, 15, 16, 17 whose window Α 14, 15 Α, Α 16, 17a is closest to the gaze direction of the user or the position of the pointing member, and the lowest order number is assigned to the syntactical model 44 associated with the application 14, 15, 16, 17 whose window 14 Α, 15a, 16 Α, 17a is furthest away from the gaze direction of the user or the position of the pointing member. The sequence number assigned to the model syntax 44 associated with the application 18 is preferably still the number of highest order. The determining processor 50 is adapted to define the phoneme sequence a candidate associated with the model syntax selected or, in the case where several syntactic patterns are selected, the phoneme sequence, among the candidate phoneme sequence associated with the selected acoustic models, for which the probability syntax is maximum, as constituting an oral instruction corresponding to the audio signal. This spoken command may be a word or phrase. It should be noted that, in the example embodiment of the invention, the linguistic decoder 38 is in the form of a software program stored in the memory 12 of the driver assistance system 10 and adapted to be executed by the processor 20. Alternatively, the linguistic decoder 38 is formed at least partially in the form of a programmable logic device, or as a dedicated integrated circuit, included in the assistance system 10. A method 100 for assisting the piloting of an aircraft, implemented by the assistance system 10, will now be described, with reference to Figures 2 to 4. In a first step 110, some applications 14, 15, 16, 17, 18 are displayed on the display device 22. this step is shown in Figure 3 by the display windows 14a and 15a associated with the applications 14 and 15. This step 110 typically continuation at system startup assistance 10, or a modification of the display of the display device 22 controlled by the user. Then the user says an oral instruction for assistance system 10. This oral instruction is, in the example shown, constituted by the order: "Changes the value va to 300 nodes". Simultaneously with the transmission of the spoken command, there is performed a step 120 for determining the spoken command by the automatic speech recognizer 30 of the driver assistance system 10. This determination step 120 comprises a first substep 122 of activating a plurality of syntactic patterns 44 by the activation/deactivation 45. Said step 122 occurs substantially concurrently with the displaying step 110. The first substep 122 typically comprises the following substeps: designating a plurality of syntactic patterns designated among the syntactic patterns, and activating syntactic patterns designated. The designation syntactic patterns is advantageously function applications 14, 15, 16, 17 displayed on the display device; the syntactic patterns are then designated the syntactic patterns associated with the displayed application. Optionally, the designation is also based on the state of at least one contextual elements, for example when the contextual element is a phase of flight of the aircraft or the system state of the aircraft; the syntactic patterns are then designated the syntactic patterns associated with the state of the object context. Optionally, syntactic patterns assets are also deactivated during the same step 122. The syntactic patterns are preferably disabled function applications 14, 15, 16, 17 displayed on the display device and, if necessary, of the state of at least one contextual elements, for example when the contextual element is a phase of flight of the aircraft or the system state of the aircraft. The syntactic patterns off are thus typically syntactic patterns associated with application previously displayed on the display device 22 and whose window was closed, or syntactic patterns are correlated with previous contextual elements, the contextual elements having changed its state. The first substep 122 thus comprises, in the example illustrated, the designation syntactic patterns associated with gas 14 and 15, the syntactic patterns associated with the application 15 comprising two syntactic patterns associated respectively with a left region and a right region 15b 15c 15a of the window, and activation of said designated patterns. The first substep 122 also includes the model designation syntax associated with the application 18. The determining step 120 then includes a second substep 124 acquisition of an audio signal corresponding to the spoken command issued by the user. This acquisition is performed by the acquisition unit 32, which senses a sound including the spoken command and transcribe this sound into an electrical signal. The second substep 124 is followed by a third substep 126 shaping of the audio signal, in which the audio signal is digitized and cut into frames by the shaping member 34. The determining step 120 also includes a substep 128 detection, by the sensor device 36, the state of at least one contextual element. The contextual element whereof is detected state is, in the example illustrated, the gaze direction of the user. The gaze direction of the user is, in known manner, would change state rapidly, and therefore switch to repeatedly state during the recitation of the spoken command by the user; should therefore define precisely the time at which the state of the eyes of a user is detected. This time is preferably the end time of the audio signal acquisition, corresponding to the end of the recitation of the spoken command by the user. In the example illustrated, the eyes of a user is directed, to the end of the acquisition of the audio signal, to the lower left corner of the display device 22. the condition sensed by the sensing device 36 is therefore "facing towards the left region of the window 15a 15b". The determining step 120 further includes a substep 130 construction phoneme sequence candidate by the algorithm for constructing spoken command 46 and a substep 132 of selecting a template syntax 44 by the processor contextualization 48. The constructing step 130 candidate phoneme sequence is performed automatically, c'est without user intervention, and substantially simultaneously to the step 124 of the audio signal acquisition. It comprises the following substeps, said substeps being repeated for each model syntactical active: associating, to each frame, a parameter vector that translates the acoustic information contained in the frame, for example by means of cepstral coefficients type MFCCs (abbreviation of the expression English "mel-Frequency Division detected cepstral coefficients"), searching, for each frame, using the probabilities syntax defined by the template syntax active, candidate phonemes associated with said frame, calculating, for each candidate phoneme, the distance of the vector of parameters associated with said candidate phoneme at 42 at the acoustic model parameter vector associated with the frame, so as to obtain the acoustic likelihood of the candidate phoneme, setting candidate phoneme sequences each formed of candidate phonemes associated with frames composing the acoustic signal, the order of the candidate phonemes in each sequence frames in sequence according to the acoustic signal, calculating, for each candidate sequence phonemes, a sequence probability equal to the product of the probabilities of different candidates syntactic and acoustic phoneme sequence component, and selecting the sequence of candidate phoneme sequence whose probability is maximum, said sequence of candidate phonemes constituting the phoneme sequence a candidate. The step of selecting a template syntax 132 is performed automatically, c'est without user intervention. It comprises the following substeps: allocating, based on the state of the detected contextual element, order number to each model syntactical active, searching, from among the active syntactic patterns, of syntactic patterns candidates are assigned are candidate phoneme sequence whose sequence probability is above a predetermined threshold, and selecting the one or more model (e) (e) syntax (e) candidate having the accession number of the highest order. Assigning sequence numbers is performed according to the logic described above. Thus, in the example illustrated, the syntactic patterns 44 associated with the application 18 and to the left region of the window 15a 15b being assigned a highest sequence number. The syntactic patterns associated with the application 14 and to the straight region 15c of the window are assigned sequence numbers smaller. The syntactic patterns associated with the right and left regions 15b 15c of the window 15a return a phoneme sequence candidate having the sequence probability is above the predetermined threshold: the phoneme sequence a candidate of the model syntax associated with the region left 15b is "changes the value va to 300 nodes", and the phoneme sequence a candidate of the model syntax associated with the straight region 15c is "changes the value of ve to 300 nodes". However, since the order number of the syntactical model associated with the region of the window right 15c 15a and lower than that of the model syntax associated with the region of the window left 15b 15a, only the latter model syntax is thus selected. Thus, although the speeds will and Ve have pronunciations in close proximity, the automatic speech recognizer 30 comes to discriminate between these two speeds by directing a user's gaze. The determining step 120 comprises a last substep 134 determining the spoken command corresponding to the audio signal. In since the model syntax selected is one of the syntactic patterns to which had been assigned the accession number of the highest order, the transition of the substep 132 136 with the substep is performed without user intervention. During this substep 134, the phoneme sequence associated with the model syntax selected or, in the case where several syntactic patterns are selected, the phoneme sequence which, among the candidate phoneme sequence associated with the selected syntactic patterns, has the maximum sequence probability, is defined as the spoken command corresponding to the audio signal. In the example represented, therefore the phoneme sequence a candidate associated with the model syntax associated with the region of the window left 15b 15a which is thereby defined as the spoken command corresponding to the audio signal. This oral instruction is then encoded into a sequence of symbols understandable to the execution unit 20, and then transmitted to the execution unit 20, which executes the statement in a step 140. In the example illustrated, an instruction is fed to the motor thereby increasing the speed at left 300 nodes, and the display of the device 22 is updated to display, in the field will, the value 300 (see Figure 4). Other examples of implementation of the method 100 are given in Figures 4 to 12. The display is initially in the state represented in Figure 4, the windows 14a and 15a being displayed. The user says the spoken command then "closes the window speeds", looking at the end of the spoken command the bottom right corner of the display device 22. The syntactic patterns assets are then the syntactic patterns associated with gas 14 and 18, and the syntactic patterns associated with the left region and the right region 15b 15c 15a of the window. The state of the viewing direction detected by the detection device 36 is the state "facing towards the straight region of the window speeds". Only the syntactic model associated with the application 18 returning a phoneme sequence candidate having the sequence probability is above the predetermined threshold, it is thus the model syntax that is selected in step 132, and it is its phoneme sequence candidate that is defined as the spoken command corresponding to the audio signal. The spoken command is then transmitted to the execution unit 140, which controls the closing of the window 15a, that then the display device, as shown in Figure 5. at the same time, the syntactic patterns associated with the right and left regions 15b 15c 15a region are deactivated. The user says then a new oral instruction "opens the window of the clock", looking at the end of the spoken command the lower part of the display device 22. The syntactic patterns assets are then the syntactic patterns associated with gas 14 and 18. The state of the viewing direction detected by the detection device 36 is the state "facing towards a void region of the screen". Only the syntactic model associated with the application 18 returning a phoneme sequence candidate having the sequence probability is above the predetermined threshold, it is thus the model syntax that is selected in step 132, and it is its phoneme sequence candidate that is defined as the spoken command corresponding to the audio signal. The spoken command is then transmitted to the execution unit 140, which controls the opening of the window 16a, which now becomes visible on the display device, as shown in Figure 6. At the same time, the syntactic patterns associated with the application 16 are activated, said syntactic patterns comprising syntactic patterns associated with the window 16a as a whole and areas left and right 16c 16b 16a of the window, the region left 16b constituting a display region of the clock and the straight region 16c constituting a display region alarms programmed. The user says then a new oral instruction "program an alarm to 16:00 10", looking at the end of the spoken command the lower part of the display device 22. The syntactic patterns assets are then the syntactic patterns associated with gas 14, 16 and 18. The state of the viewing direction detected by the detection device 36 is the state "facing towards the window clock". Only the template syntax associated with the window 16a returning a phoneme sequence candidate having the sequence probability is above the predetermined threshold, it is thus the model syntax that is selected in step 132, and it is its phoneme sequence candidate that is defined as the spoken command corresponding to the audio signal. The spoken command is then transmitted to the execution unit 140, which controls the programming of the alarm, and updating the display to display, in the window 16a, the time of the alarm thus programmed, as shown in Figure 7. The user says then a new oral instruction "command opens the engine", looking at the end of the spoken command the lower left corner of the display device 22. The syntactic patterns assets are then the syntactic patterns associated with gas 14, 16 and 18. The state of the viewing direction detected by the detection device 36 is the state "facing towards the left side of the window clock". Only the syntactic model associated with the application 14 returning a phoneme sequence candidate having the sequence probability is above the predetermined threshold, it is thus the model syntax that is selected in step 132, while its order number is less than the order numbers syntactic patterns associated with the application 18 and to the region left 16b 16a of the window. Since the sequence number assigned to the selected syntactic model is not the number of the highest order, the speech recognizer 30 asks the user, in a step 136, confirm that its instruction corresponds well to the phoneme sequence a candidate of the syntactical model selected. If the command is confirmed, the phoneme sequence a candidate of the selected syntactic model (c'est to say, in the present example, the phoneme sequence a candidate of the model syntax associated with the application 14) is defined as the spoken command corresponding to the audio signal. See as well as it is possible to correct an error in the user's gaze. The spoken command is then transmitted to the execution unit 140, which controls the opening of a new tab in the window 14a. Displaying the 14a is thus modified, as shown in Figure 8. A new oral instruction "closes the window of synoptic" is then spoken by the user, the latter looking at the end of the spoken command the high part of the display device 22. The syntactic patterns assets are then the syntactic patterns associated with gas 14, 16 and 18. The state of the viewing direction detected by the detection device 36 is the state "facing towards the window of the synapse". Only the syntactic model associated with the application 18 returning a phoneme sequence candidate having the sequence probability is above the predetermined threshold, it is thus the model syntax that is selected in step 132, and it is its phoneme sequence candidate that is defined as the spoken command corresponding to the audio signal. The spoken command is then transmitted to the execution unit 140, which controls the closing of the window 14a, that then the display device, as shown in Figure 9. at the same time, the model syntax associated with the application 14 is deactivated. The user says then a new oral instruction "opens the browser window", looking at the end of the spoken command the high part of the display device 22. The syntactic patterns assets are then the syntactic patterns associated with gas 16 and 18. The state of the viewing direction detected by the detection device 36 is the state "facing towards a void region of the screen". Only the syntactic model associated with the application 18 returning a phoneme sequence candidate having the sequence probability is above the predetermined threshold, it is thus the model syntax that is selected in step 132, and it is its phoneme sequence candidate that is defined as the spoken command corresponding to the audio signal. The spoken command is then transmitted to the execution unit 140, which controls the opening of the window 17a, which now becomes visible on the display device, as shown in Figure 10. At the same time, the syntactic patterns associated with the application 17 are activated, said syntactic patterns including a template syntax associated with the window 17a as a whole, but also other syntactic patterns associated with different regions 17 Β, 17c, 17d, 17th, 17f, 17g of a map displayed in the window 17a. The user says then a new oral instruction "selects the waypoint KCVG", looking at the end of the spoken command the region 17b 17a of the window. The syntactic patterns assets are then the syntactic patterns associated with gas 16, 17 and 18. The state of the viewing direction detected by the detection device 36 is the state "opposite facing region b of the card". The syntactic patterns associated with the application 18, to the window 17a and to the region 17b to thus attributed the number of highest order, while the other syntactic patterns are assigned sequence numbers smaller. The syntactic patterns associated with the regions 17b and 17c return each a phoneme sequence candidate having the sequence probability is above the predetermined threshold: the phoneme sequence a candidate of the model syntax associated with the region 17b is "selects the waypoint KCVG", and the phoneme sequence a candidate model 17c syntax associated with the region is "selects the waypoint KCVJ". Since the model syntax associated with the region 17b has a number of higher order, it is this single model syntax that is selected in step 132, and it is therefore its phoneme sequence candidate that is defined as the spoken command corresponding to the audio signal. Thus, although the passing points KCVGKCVJ and have pronunciations in close proximity, the automatic speech recognizer 30 comes to discriminate between these two points by orienting the user's gaze. The spoken command is then transmitted to the execution unit 140, which controls the display of information relating to the passageway KCVG on the display 22. the window 17a then switches to full screen, as shown in Figure 11, while the window 16a disappears. At the same time, the syntactic patterns associated with the application 16 are deactivated. The user says finally a last instruction oral "zooms into the card", looking at the end of the spoken command the region 17b 17a of the window. The syntactic patterns assets are then the syntactic patterns associated with gas 17 and 18. The state of the viewing direction detected by the detection device 36 is the state "opposite facing region b of the card". The syntactic patterns associated with the application 18, to the window 17a and to the region 17b to thus attributed the number of highest order, while the other syntactic patterns are assigned sequence numbers smaller. Only the template syntax associated with the window 17a returning a phoneme sequence candidate having the sequence probability is above the predetermined threshold, it is thus the model syntax that is selected in step 132, and it is its phoneme sequence candidate that is defined as the spoken command corresponding to the audio signal. The spoken command is then transmitted to the execution unit 140, which controls a map zoom 17a displayed in the window. At the end of this zoom, only those regions of the 17th 17b and remain displayed; the syntactic patterns associated with the regions 17c, 17d, 17f and 17g will be deactivated. The above disclosed invention can thus be implemented autonomously by devices having a limited computational power, since are used only syntactic patterns may not recognize that small numbers of sentences, so that we can simply employ acoustic models not requiring considerable computing power. The juxtaposition of these syntactic patterns to each other yet enables the recognition of a large vocabulary, and the consideration of conditions enables contextual elements that discriminate necessary between the results returned by these different syntactic patterns. It is thus possible to reach a recognition rate close to 100% on a large vocabulary. Further, the invention can lower the error rate by allowing the consideration issued instructions in a wrong context. Finally, the latencies are very low since, due to the architecture of the linguistic decoder 38, determining candidate phoneme sequences can be performed substantially simultaneously with the acquisition of the audio signal, and that the final stage, which involves the selection of at least one template syntax for the determination of the spoken command corresponding to the audio signal, requires very little computation and is almost instantaneous. An automatic speech recognition with detection of at least one contextual element, and application to aircraft flying and maintenance are provided. The automatic speech recognition device comprises a unit for acquiring an audio signal, a device for detecting the state of at least one contextual element, and a language decoder for determining an oral instruction corresponding to the audio signal. The language decoder comprises at least one acoustic model defining an acoustic probability law and at least two syntax models each defining a syntax probability law. The language decoder also comprises an oral instruction construction algorithm implementing the acoustic model and a plurality of active syntax models taken from among the syntax models, a contextualization processor to select, based on the state of the order each contextual element detected by the detection device, at least one syntax model selected from among the plurality of active syntax models, and a processor for determining the oral instruction corresponding to the audio signal. 1, - automatic speech recognizer (30) comprising a unit (32) acquisition of an audio signal, means (34) for shaping the audio signal, the audio signal for cutting into frames, and a linguistic decoder (38) for determining a spoken command corresponding to the audio signal, the decoder (38) comprising linguistic: at least one acoustic model (42) defining a probability law acoustic for calculating, for each phoneme of a phoneme sequence, a probability for said acoustic phoneme and a corresponding frame of the audio signal match, and at least one template syntax (44) defining a probability law syntax for computing, for each phoneme of a phoneme sequence analyzed using the acoustic model (42), a syntactic probability for said phoneme follows the phoneme or phoneme group preceding said phoneme in the phoneme sequence, characterized in that the speech recognition device (30) comprises a detection device (36) for detecting the status of at least one contextual element, in that the syntactic patterns (44) are at least two in number, and that the linguistic decoder (38) comprises: an algorithm for constructing spoken command (46) using the acoustic model (42) and a plurality of individual active syntactic patterns among the syntactic patterns (44) for constructing, for each active syntactic model, a phoneme sequence a candidate associated with said active syntactic model for which the probability of syntactic acoustic and different phonemes constituting said phoneme sequence candidate is maximum, a processor (48) contextualization for selecting, based on the state of the or each contextual detected by the detection device (36), at least one syntactic pattern selected from the plurality of active syntactic patterns, and a processor (50) for determining the spoken command corresponding to the audio signal, to define the phoneme sequence a candidate associated with the model syntax selected or, in the case where several syntactic patterns are selected, the phoneme sequence, among the candidate phoneme sequence associated with the selected acoustic models, for which the probability of syntactic acoustic and different phonemes constituting said phoneme sequence is maximum, as constituting the spoken command corresponding to the audio signal. 2, - automatic speech recognition device (30) according to claim 1, wherein the processor (48) contextualization is adapted to: allocating, based on the state of the detected contextual element, order number to each model syntactical active, searching, from among the active syntactic patterns, syntactic patterns candidates are assigned are candidate phoneme sequence for which the probability of syntactic acoustic and different phonemes constituting said candidate phoneme sequence is greater than a predetermined threshold, and select the model (e) (e) syntax (e) candidate having the accession number of the highest order. 3, - automatic speech recognition device (30) according to claim 1 or 2, wherein at least one contextual element is independent of the audio signal. 4, - automatic speech recognition device (30) according to any one of claims 1 to 3, wherein the detection device (36) includes a sensor (40) facing adapted to detect the direction of a view of a user or a pointing sensor adapted for sensing the position of a pointing member such as a slider. 5, - automatic speech recognition device (30) according to claims 2 and 4 taken together, comprising a display device displaying objects (22), (44) syntactic each model being associated with a respective one of the objects displayed object, the processor (48) being contextualization adapted to assign its order number to each template syntax according to the distance between the gaze direction of the user or the position of the pointer and the displayed object which is associated with said model syntax (44). 6, (10) - system for assisting in steering or servicing of an aircraft, characterized in that it comprises an automatic speech recognizer (30) according to any one of claims 1 to 5, and a unit (20) control execution for execution of the spoken command corresponding to the audio signal. 7, - (10) assist system according to claim 6, wherein the detection device (36) includes a phase detector of flight of the aircraft or the system state of the aircraft (41). 8. - a method for automatic recognition (120) for determining a spoken command corresponding to an audio signal, the method being implemented by an automatic speech recognizer (30) comprising: at least one acoustic model (42) defining a probability law acoustic for calculating, for each phoneme of a phoneme sequence, a probability for said acoustic phoneme and a corresponding frame of the audio signal match, and at least one template syntax (44) defining a probability law syntax for computing, for each phoneme of a phoneme sequence analyzed using the acoustic model (42), a syntactic probability for said phoneme follows the phoneme or phoneme group preceding said phoneme in the phoneme sequence, characterized in that the syntactic patterns (44) are at least two in number, and in that the method (120) comprises the following steps: acquiring the audio signal (124), (128) sensing the state of at least one contextual element, (122) activating a plurality of syntactic patterns forming active syntactic patterns, shaping the audio signal (126), said shaping (126) comprising stamping the audio signal into frames, (130) constructing, for each active syntactic model, using the acoustic model and said model syntactical active, a phoneme sequence of a candidate associated with said active syntactic model for which the probability of syntactic acoustic and different phonemes constituting said phoneme sequence candidate is maximum, (132) selection, depending on the state of the contextual element, at least a selected one of the syntactic model active syntactic patterns, and (134) definition of the phoneme sequence a candidate associated with the model syntax selected or, in the case where several syntactic patterns are selected, the phoneme sequence, among the candidate phoneme sequence associated with the selected syntactic patterns, for which the probability of syntactic acoustic and different phonemes constituting said phoneme sequence is maximum, as constituting the spoken command corresponding to the audio signal. 9. - automatic voice recognition method (120) of claim 8, wherein the selecting step (132) comprises the following substeps: allocating, based on the state of the detected contextual element, order number to each model syntactical active, searching, from among the active syntactic patterns, of syntactic patterns candidates are assigned are candidate phoneme sequence for which the probability of syntactic acoustic and different phonemes constituting said candidate phoneme sequence is greater than a predetermined threshold, and selecting the one or more model (e) (e) syntax (e) candidate having the accession number of the highest order. 10, - automatic voice recognition method (120) of claim 8 or 9, wherein at least one contextual element is independent of the audio signal. 11, - automatic voice recognition method (120) according to any one of claims 8 to 10, wherein the context includes a direction of a view of a user or a position of a pointing member such as a slider. 12, - automatic voice recognition method according to claims 9 and 11 taken together, wherein objects are displayed on a display device (22), (44) syntactic each model being associated with a respective one of the objects displayed object, and the sequence number is assigned to each template syntax according to the distance between the gaze direction of the user or the position of the pointing member and the displayed object which is associated with said model syntax (44). 13, - automatic voice recognition method (120) of claim 11 or 12, wherein the gaze direction of the user consists of a gaze direction of the user at the end of the acquisition of the audio signal. 14, (100) - method for assisting in steering or servicing of an aircraft, implemented by a system for assisting in steering (10) or by a system which assists the maintenance of said aircraft, characterized in that it comprises the following steps: determining, by a method of automatic speech recognition (120) according to any one of claims 8 to 13, a spoken command corresponding to a recorded audio signal, and (140) executing, by the assistance system, of the spoken command. 15, - (100) assist method according to claim 14, wherein the context includes a flight phase of the aircraft or a system state of the aircraft.