Maschinelle Lernvorrichtung und maschinelles Lernverfahren zum Lernen eines optimalen Objekt-Greifwegs
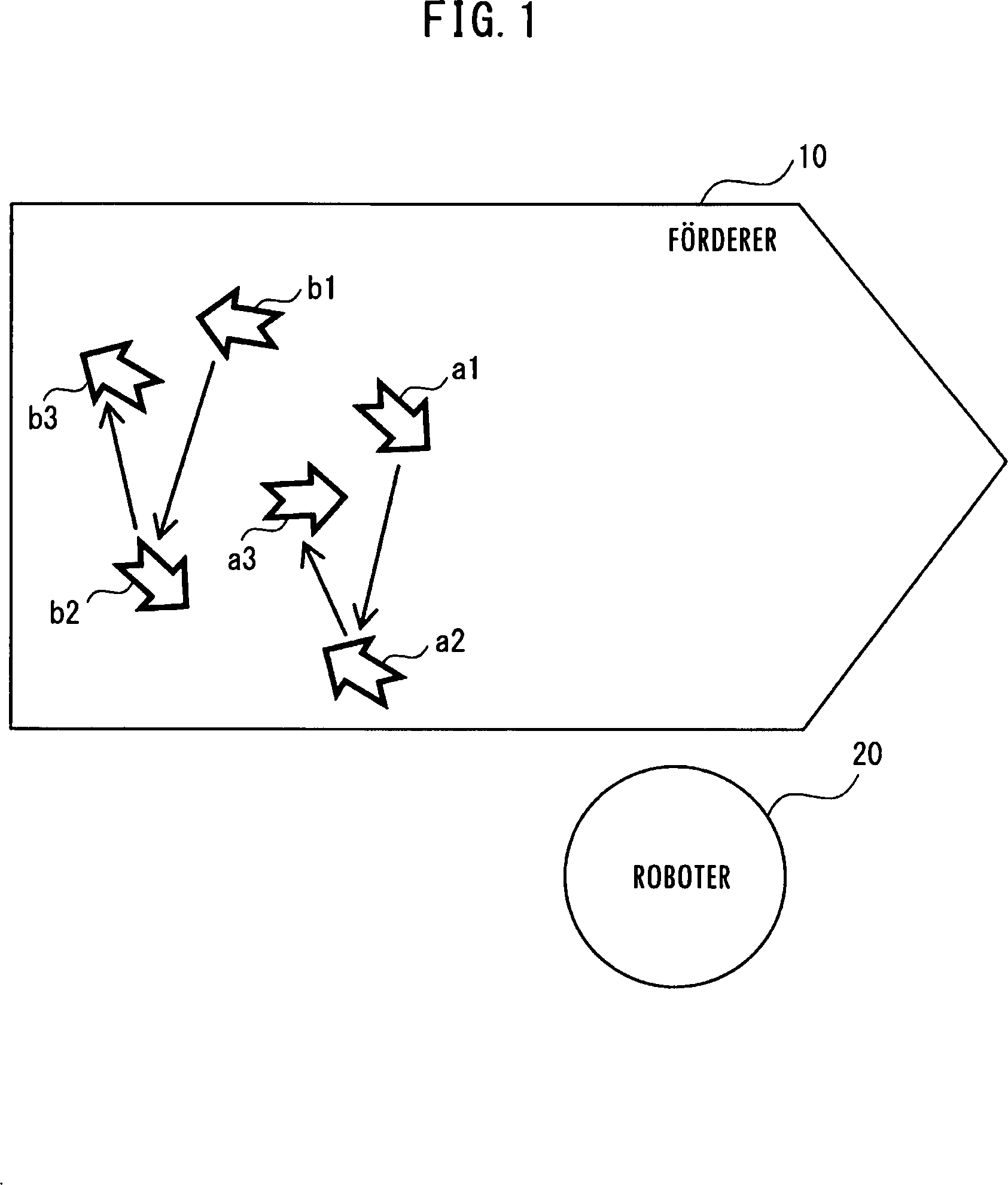
Die vorliegende Erfindung betrifft eine maschinelle Lernvorrichtung und ein maschinelles Lernverfahren und betrifft insbesondere eine maschinelle Lernvorrichtung und ein maschinelles Lernverfahren zum Lernen eines optimalen Objekt-Greifwegs, wenn ein Roboter auf einer Trägervorrichtung angeordnete Objekte greift. Objektträgersysteme, die eine Mehrzahl von auf einer Trägervorrichtung, d. h., einem Förderer, beförderte Objekte sequenziell eines nach dem anderen mit einer Hand (mehrfingriger Hand), die mehrere Objekte halten kann, greifen und die die Objekte in Behälter legen, die gleichermaßen durch einen anderen Förderer befördert werden, sind bekannt. Herkömmlicherweise werden die Objekte beim Greifen und Herausnehmen der Objekte grundsätzlich in der Reihenfolge gegriffen, in der sich die Objekte stromabwärts von dem Förderer befinden. Beispielsweise wird ein Verfahren vorgeschlagen, in dem ein Förderer entlang einer Förderrichtung von Objekten zweigeteilt ist, und die Objekte in der Reihenfolge, in der sich die Objekte stromabwärts von dem Förderer befinden, gegriffen und in Behälter gelegt werden (zum Beispiel die ungeprüfte Die Hand hat die Funktionen des Greifens von drei Objekten und des Ablegens der Objekte in einen Behälter. Wenn sich der Förderer 10 von der linken nach der rechten Seite von Da herkömmlicherweise die Objekte in der Reihenfolge gegriffen werden, in der sich die Objekte stromabwärts befinden, kann sich die Hand vor und zurück bewegen, wie durch die Pfeile in Da weiterhin die Stellungen der Objekte nicht berücksichtigt werden, kann sich die Hand des Roboters 20 beträchtlich drehen, wie in Das Verfahren von Patentdokument 1, wie oben beschrieben, greift Objekte in der Reihenfolge, in der sich die Objekte stromabwärts befinden, ohne die Positionen der Objekte in der Breitenrichtung des Förderers 10 und die Orientierungen der Objekte zu berücksichtigen. Daher variiert die Bewegungszeit der Hand stark, und in einigen Fällen kann es dem Roboter misslingen, die Objekte in einen Behälter zu legen, während der Behälter vor dem Roboter vorbeiläuft. Es ist denkbar, den Förderer für die Behälter jedes Mal zu stoppen, wenn der Roboter Objekte greift. Dies ist jedoch in aktuellen Produktionsstätten schwierig zu übernehmen, weil es Fälle gibt, in denen das Produktionsvolumen innerhalb einer bestimmten Zeitdauer vorbestimmt wird und das Fördern der Behälter aufgrund einer Beziehung zu nachfolgenden Schritten nicht gestoppt werden kann. Patentdokument 1 beschreibt ein Verfahren, in dem ein Bereich weiter in kleinere Teilbereiche aufgeteilt wird und das Greifen in jedem Teilbereich ausgeführt wird, um die Tragestrecke zu reduzieren. Wenn jedoch der Förderer breit ist, dürfte das Aufteilen des Bereichs wenig Auswirkung haben. Da weiterhin die Orientierungen (Stellungen) der Objekte nicht berücksichtigt werden, kann der Roboter ein Objekt greifen, das eine von einer zum Greifen günstigen Stellung völlig unterschiedliche Stellung aufweist. Weiterhin berücksichtigt das Verfahren von Patentdokument 1 die dem Roboter eigene Fähigkeit (zum Beispiel die Stärke eines Mechanismus und dergleichen) und den Unterschied der Tragfähigkeit aufgrund von Unterschieden der Stellen der Objekte auf dem Förderer nicht. Die vorliegende Erfindung zielt darauf ab, eine maschinelle Lernvorrichtung und ein maschinelles Lernverfahren zum Reduzieren der Last auf einen Roboter, der eine Hand aufweist, die die Funktion des Greifens einer Mehrzahl von Objekten hat, bereitzustellen, sowie die Zykluszeit zu minimieren, die die Zeit ist, die der Roboter benötigt, um die Objekte in einem Behälter zu verstauen. Eine maschinelle Lernvorrichtung gemäß einer Ausführungsform der vorliegenden Erfindung lernt einen Betriebszustand eines Roboters, der eine Mehrzahl von auf einer Trägervorrichtung angeordneten Objekten unter Verwendung einer Hand zum Greifen der Objekte in einem Behälter verstaut. Die maschinelle Lernvorrichtung umfasst eine Zustandsbeobachtungseinheit zum Beobachten, während des Betriebs des Roboters, der Positionen und Stellungen der Objekte und einer Zustandsvariablen, die mindestens eines von einer Zykluszeit zum Verstauen der Objekte in dem Behälter und eines Drehmoments und einer Vibration, die auftreten, wenn der Roboter die Objekte greift, umfasst; eine Bestimmungsdaten-Einholungseinheit zum Einholen von Bestimmungsdaten zum Bestimmen einer Spanne von jeweils der Zykluszeit, dem Drehmoment und der Vibration in Abhängigkeit von einem zulässigen Toleranzwert; und eine Lerneinheit zum Lernen des Betriebszustands des Roboters in Übereinstimmung mit einem Trainingsdatensatz, der aus einer Kombination aus der Zustandsvariablen und den Bestimmungsdaten gebildet wird. Eine maschinelle Lernvorrichtung gemäß einer Ausführungsform der vorliegenden Erfindung lernt einen Betriebszustand eines Roboters, der eine Mehrzahl von auf einer Trägervorrichtung angeordneten Objekten unter Verwendung einer Hand zum Greifen der Objekte in einem Behälter verstaut. Das maschinelle Lernverfahren umfasst die Schritte des Beobachtens, während des Betriebs des Roboters, der Positionen und Stellungen der Objekte und einer Zustandsvariablen, die mindestens eines von einer Zykluszeit zum Verstauen der Objekte in dem Behälter und eines Drehmoments und einer Vibration, die auftreten, wenn der Roboter die Objekte greift, umfasst; Einholen von Bestimmungsdaten zum Bestimmen einer Spanne von jeweils der Zykluszeit, dem Drehmoment und der Vibration in Abhängigkeit von einem zulässigen Toleranzwert; und Lernen des Betriebszustands des Roboters in Übereinstimmung mit einem Trainingsdatensatz, der aus einer Kombination aus der Zustandsvariablen und den Bestimmungsdaten gebildet wird. Die Aufgaben, Merkmale und Vorteile der vorliegenden Erfindung werden aus der folgenden ausführlichen Beschreibung von Ausführungsformen zusammen mit den beigefügten Zeichnungen ersichtlicher werden. In den beigefügten Zeichnungen: Eine maschinelle Lernvorrichtung und ein maschinelles Lernverfahren gemäß der vorliegenden Erfindung werden nachfolgend mit Bezug auf die Zeichnungen beschrieben. Eine maschinelle Lernvorrichtung gemäß einer ersten Ausführungsform wird mit Bezug auf die Zeichnungen beschrieben. Die maschinelle Lernvorrichtung 101 umfasst eine Zustandsbeobachtungseinheit 11, eine Bestimmungsdaten-Einholungseinheit 12 und eine Lerneinheit 13. Die Zustandsbeobachtungseinheit 11 beobachtet, während des Betriebs des Roboters 20, die Positionen und Stellungen der Objekte (p1 bis p6), und eine Zustandsvariable, die mindestens eines von einer Zykluszeit zum Verstauen der Objekte in dem Behälter und eines Drehmoments und einer Vibration, die auftreten, wenn der Roboter die Objekte greift, umfasst. Die Positionen und Stellungen der Objekte können basierend auf einem durch eine (nicht gezeigte) Kamera aufgenommenen Bild analysiert werden. In diesem Fall wird die Analyse der Positionen und Stellungen der Objekte bevorzugt zu dem Zeitpunkt abgeschlossen, wenn der Roboter 20 beginnt, die Objekte (p1 bis p6) zu greifen. Die Kamera befindet sich dabei bevorzugt stromaufwärts des Förderers 10 von dem Roboter 20. Es wird angemerkt, dass der Förderer 10 die Objekte von der linken Seite zur rechten Seite von Die Zykluszeit bezieht sich auf die Zeit, ab der der Roboter beginnt, eine vorgeschriebene Anzahl von Objekten in einem Behälter zu verstauen, bis der Roboter das Verstauen der Objekte in dem Behälter abschließt. Die vorgeschriebene Anzahl von Objekten bezieht sich auf Objekte, deren Greifreihenfolge (Weg) zu bestimmen ist, und auf in einem bestimmten Bereich 30 von Das Drehmoment tritt auf, wenn sich die Hand zu den Positionen der Objekte bewegt und wenn sich die Hand abhängig von den Stellungen der Objekte dreht. Das Drehmoment wird basierend auf durch Motoren zum Antreiben der Hand und eines (nicht gezeigten) Arms des Roboters 20 fließende Ströme berechnet. Der Roboter 20 weist bevorzugt Amperemeter zum Messen der durch die Motoren fließenden Ströme auf. Es wird angemerkt, dass nachdem die Hand ein Objekt gegriffen hat, sich die Hand dreht, während sie sich an eine unterschiedliche Position bewegt, um ein weiteres Objekt zu greifen. Mit anderen Worten, nachdem die Hand ein Objekt gegriffen hat, bewegt sich die Hand, während sie sich dreht, um einen geeigneten Winkel zum Greifen des nächsten Objekts zu haben. Vibration tritt auf, wenn sich die Hand zu Positionen des Objekts bewegt und stoppt, und wenn sich die Hand dreht und das Drehen abhängig von den Stellungen des Objekts stoppt. Um die Vibration zu messen, weist die Hand bevorzugt einen Beschleunigungssensor auf. Die Vibration wird basierend auf einer durch den Beschleunigungssensor detektierten Beschleunigung berechnet. Die Bestimmungsdaten-Einholungseinheit 12 holt Bestimmungsdaten zum Bestimmen einer Spanne von jeweils der Zykluszeit, dem Drehmoment und der Vibration in Abhängigkeit von deren zulässigem Toleranzwert ein. Die zulässigen Toleranzwerte der Zykluszeit, des Drehmoments und der Vibration können in einem (nicht gezeigten) Speicher gespeichert werden. Die Zykluszeit, das Drehmoment und die Vibration sind bevorzugt allesamt gleich oder kleiner als die zulässigen Toleranzwerte. Die Lerneinheit 13 lernt den Betriebszustand des Roboters in Übereinstimmung mit einem Trainingsdatensatz, der aus einer Kombination aus der Zustandsvariablen und den Bestimmungsdaten gebildet wird. Wenn die Zykluszeit, das Drehmoment und die Vibration allesamt gleich oder kleiner als die zulässigen Toleranzwerte sind, werden die Objekte bevorzugt in der Reihenfolge gegriffen, in der die Zykluszeit minimiert wird. Als Nächstes wird der Arbeitsgang des Greifens von Objekten mit einem Roboter durch die maschinelle Lernvorrichtung gemäß der ersten Ausführungsform der vorliegenden Erfindung mit Bezug auf das Ablaufdiagramm von Als Nächstes wird in Schritt S102 die Greifreihenfolge der Objekte basierend auf Lernergebnissen zugeordnet. Als Nächstes wird in Schritt S103 in Erwiderung einer Anfrage von dem Roboter 20 die Greifreihenfolge der Objekte von der maschinellen Lernvorrichtung 101 zum Roboter 20 gesendet. Im Vergleich zu dem Fall der in Die Hand greift drei Objekte in dieser Ausführungsform, ist jedoch nicht darauf beschränkt; die Anzahl der durch die Hand gegriffenen Objekte kann zwei oder vier oder mehr betragen. „Greifen” umfasst ein „Ansaugen” durch die Hand. Gemäß der vorliegenden Erfindung dreht sich die Hand, um das Objekt p3 zu greifen, nachdem das Objekt p1 gegriffen wurde, um einen kleineren Winkel als der Winkel, um den sich die Hand dreht, um das Objekt a2 zu greifen, nachdem das Objekt a1 gegriffen wurde, wie in der herkömmlichen Technik beschrieben (siehe Als Nächstes wird die Konfiguration der Lerneinheit 13 beschrieben. Wie in Die Lerneinheit 13 aktualisiert eine Aktionswerttabelle entsprechend der Greifreihgenfolge von Objekten basierend auf der Zustandsvariablen, die mindestens eines von der Zykluszeit, dem Drehmoment, der Vibration und der Belohnung umfasst. Die Lerneinheit 13 kann eine Aktionswerttabelle, die mindestens einem von der Zykluszeit, dem Drehmoment und der Vibration entspricht, wenn ein anderer Roboter mit derselben Konfiguration wie der Roboter 20 andere Objekte in einem Behälter verstaut, basierend auf der Zustandsvariablen und der Belohnung des anderen Roboters aktualisieren. Die Belohnungsberechnungseinheit 14 berechnet eine Belohnung basierend auf mindestens einem von der Zykluszeit, dem Drehmoment und der Vibration. Des Weiteren kann, wenn das Greifen eines Objekts misslingt, oder mit anderen Worten, wenn ein Greiffehler auftritt, die Belohnungsberechnungseinheit 14 eine negative Belohnung vorsehen. Die Lerneinheit 13 umfasst ferner bevorzugt eine Entscheidungsbestimmungseinheit 16, die die Greifreihenfolge von Objekten in Übereinstimmung mit Ergebnissen des Lernens in Übereinstimmung mit einem Trainingsdatensatz bestimmt. Als Nächstes wird ein Verfahren zum Berechnen einer Belohnung beschrieben. Als Nächstes bestimmt in Schritt S202 die Belohnungsberechnungseinheit 14, ob die Zykluszeit kürzer als ein Referenzwert ist oder nicht. Wenn die Zykluszeit kürzer als der Referenzwert ist, wird in Schritt S203 eine positive Belohnung vorgesehen. Wenn andererseits die Zykluszeit gleich groß oder länger als der Referenzwert ist, geht der Arbeitsgang weiter zu Schritt S201, und es wird keine Belohnung vorgesehen. Der Referenzwert der Zykluszeit ist der Durchschnittswert der Zykluszeit, wenn der Roboter für eine bestimmte Zeitdauer in der Vergangenheit betrieben wurde. Des Weiteren kann der Referenzwert in Übereinstimmung mit Lernergebnissen angepasst werden, wobei der Durchschnittswert als ein Anfangswert verwendet wird. Als Nächstes bestimmt in Schritt S204 die Belohnungsberechnungseinheit 14, ob sich das Drehmoment erhöht hat oder nicht. Wenn das Drehmoment gleich oder kleiner als ein Referenzwert ist, geht der Arbeitsgang weiter zu Schritt S205 und es wird keine Belohnung vorgesehen. Wenn anderseits das Drehmoment größer als der Referenzwert ist, wird eine negative Belohnung in Schritt S207 vorgesehen. Der Referenzwert des Drehmoments ist der Durchschnittswert des Drehmoments, wenn der Roboter für eine bestimmte Zeitdauer betrieben wurde. Des Weiteren kann der Referenzwert in Übereinstimmung mit Lernergebnissen angepasst werden, wobei der Referenzwert als ein Anfangswert verwendet wird. Als Nächstes bestimmt die Belohnungsberechnungseinheit 14 in Schritt S206, ob sich der Vibrationsbetrag erhöht hat oder nicht. Wenn der Vibrationsbetrag gleich groß oder kleiner als ein Referenzwert ist, geht der Arbeitsgang weiter zu Schritt S205, und es wird keine Belohnung vorgesehen. Wenn andererseits der Vibrationsbetrag größer als der Referenzwert ist, wird eine negative Belohnung in Schritt S207 vorgesehen. Der Referenzwert des Vibrationsbetrags ist der Durchschnittswert des Vibrationsbetrags, wenn der Roboter für eine bestimmte Zeitdauer in der Vergangenheit betrieben wurde. Des Weiteren kann der Referenzwert in Übereinstimmung mit Lernergebnissen angepasst werden, wobei der Durchschnittswert als ein Anfangswert verwendet wird. Als Nächstes wird in Schritt S208 eine Belohnung berechnet. Wenn Rc eine Belohnung basierend auf der Zykluszeit darstellt, Rr eine Belohnung basierend auf dem Drehmoment darstellt und Rv eine Belohnung auf der Vibration darstellt wird der Gesamtwert R der Belohnungen durch R = αxRc + βxRr + γxRv berechnet, wobei vorgeschriebene Koeffizienten verwendet werden, die Gewichte definieren. Als Nächstes aktualisiert die Lerneinheit 13 in Schritt S209 eine Aktionswerttabelle, die der Greifreihenfolge von Objekten entspricht, basierend auf einer Zustandsvariablen von mindestens einem von der Zykluszeit, dem Drehmoment, der Vibration und der Belohnung. Die Lerneinheit 13 führt bevorzugt eine Berechnung einer durch die Zustandsbeobachtungseinheit 11 in einer mehrschichtigen Struktur beobachteten Zustandsvariablen durch und aktualisiert eine Aktionswerttabelle in Echtzeit. Als ein Verfahren zum Ausführen einer Berechnung einer Zustandsvariablen in einer mehrschichtigen Struktur kann beispielsweise ein mehrschichtiges neurales Netzwerk, wie in Die in Beim „überwachten Lernen” wird eine große Menge an Datenpaaren einer bestimmten Eingabe und ein Ergebnis (Label) einem Lernsystem bereitgestellt. Das Lernsystem lernt Merkmale aus dem Datensatz und erhält heuristisch ein Modell, um ein Ergebnis aus einer Eingabe, d. h. der Beziehung dazwischen, vorherzusagen. „Überwachtes Lernen” kann durch Verwenden eines Algorithmus, wie ein später beschriebenes neurales Netzwerk, verwirklicht werden. Beim „unüberwachten Lernen” wird nur eine große Menge von Eingabedaten dem Lernsystem bereitgestellt. Das Lernsystem lernt die Verteilung der Eingabedaten und wendet Komprimierung, Klassifizierung, Ausrichtung oder dergleichen auf die Eingabedaten an, ohne mit entsprechenden Ausgabedaten als Überwacher versorgt zu werden. Die Merkmale des Datensatzes können einem Clustern durch Analogie unterworfen werden. Mit Verwendung dieses Ergebnisses wird, während ein bestimmtes Kriterium bereitgestellt wird, eine Ausgabe zugeordnet, um das Kriterium zu optimieren, und dies erlaubt eine Vorhersage der Ausgabe. Es gibt ebenfalls ein als „teilüberwachtes Lernen” bezeichnetes Verfahren als eine Zwischenproblemlösung zwischen dem „überwachten Lernen” und dem „unüberwachten Lernen”, in dem ein Teil der Daten Paare einer Eingabe und einer Ausgabe umfassen, während der andere Teil nur Eingabedaten umfasst. In dieser Ausführungsform verwendet das unüberwachte Lernen Daten, die ohne aktuelles Betreiben des Roboters eingeholt werden können, um die Lerneffizienz zu verbessern. Probleme beim bestärkenden Lernen werden wie folgt bestimmt. Das „bestärkende Lernen” ist ein Verfahren zum Lernen von optimalen Aktionen basierend auf Interaktionen zwischen einer Aktion und einer Umgebung durch Lernen von Aktionen, sowie Bestimmen und Klassifizieren; mit anderen Worten, es ist ein Lernverfahren, um eine in der Zukunft erhaltene Gesamtbelohnung zu maximieren. In dieser Ausführungsform zeigt dies an, dass Aktionen, die eine Wirkung auf die Zukunft haben, eingeholt werden können. Die folgende Beschreibung nimmt Q-Lernen als ein Beispiel, ist jedoch nicht darauf beschränkt. Das Q-Lernen ist ein Verfahren zum Lernen eines Q(s, a)-Werts zum Wählen einer Aktion „a” in einem gewissen Umgebungszustand „s”. Mit anderen Worten, in einem gewissen Zustand „s” wird eine Aktion „a” mit dem höchsten Q(s, a)-Wert als eine optimale Aktion gewählt. Jedoch ist ein korrekter Q(s, a)-Wert bezüglich einer Kombination eines Zustands „s” und einer Aktion „a” zu Beginn überhaupt nicht bekannt. Daher wählt ein Agent verschiedene Aktionen „a” in einem gewissen Zustand „s”, und erhält eine Belohnung für jede Aktion „a”. Dadurch lernt der Agent eine bessere Aktion, d. h. einen korrekten Q(s, a)-Wert, zu wählen. Das Ziel ist, eine in der Zukunft zu erzielende Gesamtbelohnung zu maximieren, d. h., Q(s, a) = E[Σγtrt] als ein Ergebnis von Aktionen zu erzielen (es wird ein erwarteter Wert genommen, wenn sich ein Zustand in Übereinstimmung mit optimalen Aktionen ändert; die optimalen Aktionen sind selbstverständlich noch nicht bekannt und müssen somit während des Lernens gefunden werden). Beispielsweise wird eine Aktualisierungsgleichung für einen Q(s, a)-Wert wie folgt dargestellt: wobei st einen Umgebungszustand zum Zeitpunkt t darstellt und at eine Aktion zum Zeitpunkt t darstellt. Durch Ausführen der Aktion at ändert sich der Zustand zu st+1. „rt+1” stellt eine durch die Zustandsänderung bereitgestellte Belohnung dar. Ein Begriff „max” stellt das Produkt aus einem Q-Wert, wenn eine Aktion „a” mit dem zu diesem Zeitpunkt bekannten höchsten Wert Q in dem Zustand st+1 gewählt wird, und γ dar. „γ” ist ein Parameter im Bereich von 0 < γ ≤ 1 und wird Diskontierungsfaktor genannt. „α” ist eine Lernrate im Bereich von 0 < α ≤ 1. Diese Gleichung bezeichnet ein Verfahren zum Aktualisieren eines Q(st, at)-Werts einer Aktion at in einem Zustand st basierend auf einer Belohnung rt+1, die als ein Ergebnis der Aktion at zurückgesendet wurde. Diese Aktualisierungsgleichung zeigt an, dass, im Vergleich zu einem Q(st, at)-Wert einer Aktion „a” in einem Zustand „s”, wenn im nächsten Zustand ein von einer Belohnung rt+1 plus der Aktion „a” abgeleiteter Wert Q(st+1, max at+1) einer optimalen Aktion „max a” höher ist, Q(st, at) erhöht wird. Wenn nicht, wird Q(st, at) verringert. Mit anderen Worten, der Wert einer Aktion in einem bestimmten Zustand wird an einen optimalen Aktionswert im nächsten Zustand angenähert, der von einer sofort als ein Ergebnis der Aktion zurückkehrenden Belohnung und der Aktion selbst abgeleitet wird. Es gibt zwei Verfahren zum Darstellen von Q(s, a)-Werten in einem Computer, d. h. ein Verfahren, in dem Q-Werte von allen Zustands-Aktions-Paaren (s, a) in einer Tabelle (Aktionswerttabelle) gespeichert werden, und ein Verfahren, in dem eine Funktion zum Annähern von Q(s, a)-Werten erstellt wird. Bei letzterem Verfahren kann das oben beschriebene Aktualisierungsverfahren verwirklicht werden, indem ein Parameter für eine Näherungsfunktion mittels eines stochastischen Gradientenverfahrens oder dergleichen angepasst wird. Als die Näherungsfunktion kann ein wie später beschriebenes neurales Netzwerk verwendet werden. Als ein Näherungsalgorithmus für eine Wertefunktion im überwachten Lernen, dem unüberwachten Lernen und dem bestärkenden Lernen kann ein neurales Netzwerk verwendet werden. Das neurale Netzwerk besteht beispielsweise aus einer Arithmetik-Einheit, einem Speicher und dergleichen, die ein Modell eines Neurons imitieren, wie in Wie in Als Nächstes wird ein dreischichtiges neurales Netzwerk mit Gewichten von drei Schichten, das aus einer Kombination von den oben beschriebenen Neuronen gebildet wird, mit Bezug auf Wie in Genauer gesagt werden die Eingaben x1 bis x3 in jede der drei Neuronen N11 bis N13 eingegeben, während sie entsprechend gewichtet werden. Die den Eingaben auferlegten Gewichte werden insgesamt als W1 bezeichnet. Die Neuronen N11 bis N13 geben die jeweiligen Vektoren Z11 bis Z13 aus. Die Vektoren Z11 bis Z13 werden insgesamt durch einen Merkmalsvektor Z1 bezeichnet, der als ein Vektor betrachtet wird, der einen Merkmalsbetrag aus dem Eingabevektor extrahiert. Der Merkmalsvektor Z1 ist ein Merkmalsfaktor zwischen dem Gewicht W1 und einem Gewicht W2. Die Vektoren Z11 bis Z13 werden in jede der zwei Neuronen eingegeben, während sie entsprechend gewichtet werden. Die den Merkmalsvektoren auferlegten Gewichte werden insgesamt als W2 bezeichnet. Die Neuronen N21 und N22 geben die j Vektoren Z21 beziehungsweise Z22 aus. Die Vektoren Z21 und Z22 werden insgesamt durch einen Merkmalsvektor Z2 bezeichnet. Der Merkmalsvektor Z2 ist ein Merkmalsvektor zwischen dem Gewicht W2 und einem Gewicht W3. Die Merkmalsvektoren Z21 und Z22 werden in jede der drei Neuronen N31 bis N33 eingegeben, während sie entsprechend gewichtet werden. Die den Merkmalsvektoren auferlegten Gewichte werden insgesamt als W3 bezeichnet. Zum Schluss geben die Neuronen N31 bis N33 die jeweiligen Ergebnisse y1 bis y3 aus. Das neurale Netzwerk besitzt einen Lernmodus und einen Wertvorhersagemodus. Im Lernmodus wird das Gewicht W unter Verwendung eines Lerndatensatzes gelernt. Im Wertvorhersagemodus wird die Aktion des Roboters unter Verwendung des in dem Lernmodus erhaltenen Parameters bestimmt (das Wort „Vorhersage” wird er Einfachheit halber verwendet, es können jedoch verschiedene Aufgaben ausgeführt werden, die Detektion, Klassifizierung, Schlussfolgerung und dergleichen umfassen). Im Wertvorhersagemodus können Daten, die durch einen tatsächlichen Betrieb des Roboters erhalten werden, sofort gelernt und in der nächsten Aktion wiedergegeben werden (Online-Lernen). Ferner kann das Lernen gemeinsam unter Verwendung einer vorab gesammelten Datengruppe ausgeführt werden, und ein Detektionsmodus kann danach unter Verwendung des Parameters ausgeführt werden (Batch-Lernen). Auf eine dazwischenliegende Weise kann der Lernmodus immer dann ausgeführt werden, wenn sich eine bestimmte Menge an Daten angesammelt hat. Die Gewichte W1 bis W3 können unter Verwendung eines Fehlerrückführungsalgorithmus (Rückführungsalgorithmus) gelernt werden. Informationen über einen Fehler treten von rechts ein und breiten sich nach links aus. Der Fehlerrückführungsalgorithmus ist ein Verfahren, in dem die Gewichte in Bezug auf jedes Neuron angepasst (gelernt) werden, um den Unterschied zwischen einer Ausgabe y und einer Ist-Ausgabe y (Überwacher) in Erwiderung einer Eingabe x zu minimieren. Ein solches neurales Netzwerk kann mehr als drei Schichten aufweisen (als Deep-Learning bezeichnet). Eine Arithmetik-Einheit, die eine Merkmalextraktion aus Eingaben in Stufen und der Regression von Ergebnissen ausführt, kann automatisch nur von Überwachungsdaten erfasst werden. Um demzufolge das oben beschriebene Q-Lernen auszuführen, wie in Wie in Die Lerneinheit 3 aktualisiert einen Aktionswert, der einer aktuellen Zustandsvariablen entspricht, und eine in der Aktionswertabelle zu ergreifenden Aktion basierend auf der Aktualisierungsgleichung und der Belohnung. In dem Beispiel von Es wird eine maschinelle Lernvorrichtung gemäß einer zweiten Ausführungsform der vorliegenden Erfindung beschrieben. Die maschinelle Lernvorrichtung 102 ist bevorzugt in einem Cloud-Server installiert. Es kann aufgrund einer hohen Verarbeitungslast für einen Roboter schwierig werden, ein Lernen während eines Hochgeschwindigkeitsbetriebs auszuführen. Gemäß der Konfiguration der maschinellen Lernvorrichtung der zweiten Ausführungsform der vorliegenden Erfindung wird das Lernen durch eine von der Robotersteuerung unterschiedlichen Vorrichtung ausgeführt, womit die Belastung für den Roboter reduziert wird. Es werden maschinelle Lernvorrichtungen gemäß einer dritten Ausführungsform der vorliegenden Erfindung beschrieben. Eine erste maschinelle Lernvorrichtung 103-1 ist in einer ersten Robotersteuerung 201 zum Steuern eines ersten Roboters 21 vorgesehen. Eine zweite maschinelle Lernvorrichtung 103-2 ist in einer zweiten Robotersteuerung 202 zum Steuern eines zweiten Roboters 22 vorgesehen. Diese Struktur ermöglicht die gemeinsame Nutzung einer durch eine der maschinellen Lernvorrichtungen unter den maschinellen Lernvorrichtungen erstellte Aktionswerttabelle und verbessert somit die Effizienz des Lernens. Es wird eine maschinelle Lernvorrichtung gemäß einer vierten Ausführungsform der vorliegenden Erfindung beschrieben. Eine erste Robotersteuerung 201 steuert einen ersten Roboter 21, während eine zweite Robotersteuerung 202 einen zweiten Roboter 22 steuert. Die maschinelle Lernvorrichtung 104 ist außerhalb der ersten Robotersteuerung 201 und der zweiten Robotersteuerung 202 vorgesehen. Die maschinelle Lernvorrichtung 104 empfängt Daten („LOG”) über die Positionen und Stellungen der Objekte, die aus durch (nicht gezeigte) Kameras aufgenommenen Bildern eingeholt werden, wobei die Kameras jeweils in der Nähe von jeweils dem ersten Roboter 21 und dem zweiten Roboter 22 vorgesehen sind, und lernt die optimale Greifreihenfolge der Objekte. Die Lernergebnisse werden an die erste Robotersteuerung 201 und die zweite Robotersteuerung 202 gesendet, sodass der erste Roboter 21 und der zweite Roboter 22 die Objekte in der optimalen Reihenfolge greifen können. Gemäß der maschinellen Lernvorrichtung und dem maschinellen Lernverfahren der Ausführungsformen der vorliegenden Erfindung ist es möglich, sowohl die Belastung des Roboters zu reduzieren als auch die Zykluszeit zu minimieren, die die Zeit ist, die von dem Roboter benötigt wird, um die Mehrzahl von Objekten unter Verwendung der die Funktion des Greifens der Objekte aufweisenden Hand in Behältern zu verstauen. Diese Liste der vom Anmelder aufgeführten Dokumente wurde automatisiert erzeugt und ist ausschließlich zur besseren Information des Lesers aufgenommen. Die Liste ist nicht Bestandteil der deutschen Patent- bzw. Gebrauchsmusteranmeldung. Das DPMA übernimmt keinerlei Haftung für etwaige Fehler oder Auslassungen. Eine maschinelle Lernvorrichtung gemäß der vorliegenden Erfindung lernt einen Betriebszustand eines Roboters, der eine Mehrzahl von auf einer Trägervorrichtung angeordneten Objekten unter Verwendung einer Hand zum Greifen der Objekte in einem Behälter verstaut. Die maschinelle Lernvorrichtung umfasst eine Zustandsbeobachtungseinheit zum Beobachten der Position und Stellungen der Objekte und einer Zustandsvariablen, die mindestens eines von einer Zykluszeit zum Verstauen der Objekte in dem Behälter und einem Drehmoment und einer Vibration, die auftreten, wenn der Roboter die Objekte während des Betriebs des Roboters greift, umfasst; eine Bestimmungsdaten-Einholungseinheit zum Einholen von Bestimmungsdaten zum Bestimmen einer Spanne von jeweils der Zykluszeit, dem Drehmoment und der Vibration in Abhängigkeit von einem zulässigen Toleranzwert; und eine Lerneinheit zum Lernen des Betriebszustands des Roboters in Übereinstimmung mit einem Trainingsdatensatz, der aus einer Kombination aus der Zustandsvariablen und der Bestimmungsdaten gebildet wird. Maschinelle Lernvorrichtung zum Lernen eines Betriebszustands eines Roboters, der eine Mehrzahl von auf einer Trägervorrichtung angeordneten Objekten unter Verwendung einer Hand zum Greifen der Objekte in einem Behälter verstaut, wobei die maschinelle Lernvorrichtung umfasst: Maschinelle Lernvorrichtung nach Anspruch 1, wobei die Zykluszeit die Zeit ist, ab der der Roboter beginnt, eine vorgeschriebene Anzahl von Objekten in einem Behälter zu verstauen, bis der Roboter das Verstauen der Objekte in dem Behälter abschließt. Maschinelle Lernvorrichtung nach Anspruch 1 oder 2, wobei das Drehmoment basierend auf einem durch einen Motor zum Antreiben des Roboters fließenden Strom berechnet wird. Maschinelle Lernvorrichtung nach einem der Ansprüche 1 bis 3, wobei die Vibration basierend auf einer durch einen in der Hand vorgesehenen Beschleunigungssensor detektierten Beschleunigung berechnet wird. Maschinelle Lernvorrichtung nach einem der Ansprüche 1 bis 4, wobei Maschinelle Lernvorrichtung nach Anspruch 5, wobei die Lerneinheit (13) eine Aktionswerttabelle, die der Greifreihenfolge der Objekte entspricht, basierend auf der Zustandsvariablen von mindestens einem von der Zykluszeit, dem Drehmoment und der Vibration und der Belohnung aktualisiert. Maschinelle Lernvorrichtung nach Anspruch 6, wobei die Lerneinheit (13) eine Aktionswerttabelle, die mindestens einem von der Zykluszeit, dem Drehmoment und der Vibration entspricht, wenn ein anderer Roboter mit derselben Konfiguration wie der Roboter andere Objekte in einem Behälter verstaut, basierend auf einer Zustandsvariablen des anderen Roboters und der Belohnung aktualisiert. Maschinelle Lernvorrichtung nach einem der Ansprüche 5 bis 7, wobei eine Belohnungsberechnungseinheit (14) die Belohnung basierend auf mindestens einem von der Zykluszeit, dem Drehmoment und der Vibration berechnet. Maschinelle Lernvorrichtung nach einem der Ansprüche 1 bis 8, ferner umfassend eine Entscheidungsbestimmungseinheit (16) zum Bestimmen der Greifreihenfolge der Objekte basierend auf einem Lernergebnis durch die Lerneinheit (13) in Übereinstimmung mit dem Trainingsdatensatz. Maschinelle Lernvorrichtung nach einem der Ansprüche 1 bis 9, wobei Maschinelle Lernvorrichtung nach einem der Ansprüche 1 bis 10, wobei die maschinelle Lernvorrichtung (102) in einem Cloud-Server installiert ist. Maschinelles Lernverfahren zum Lernen eines Betriebszustands eines Roboters, der eine Mehrzahl von auf einer Trägervorrichtung angeordneten Objekten in einem Behälter unter Verwendung einer Hand zum Greifen der Objekte verstaut, wobei das maschinelle Lernverfahren die Schritte umfasst: HINTERGRUND DER ERFINDUNG
1. Gebiet der Erfindung
2. Beschreibung des Standes der Technik
KURZDARSTELLUNG DER ERFINDUNG
KURZE BESCHREIBUNG DER ZEICHNUNGEN
AUSFÜHRLICHE BESCHREIBUNG DER ERFINDUNG
[Erste Ausführungsform]
[Zweite Ausführungsform]
[Dritte Ausführungsform]
[Vierte Ausführungsform]
ZITATE ENTHALTEN IN DER BESCHREIBUNG
Zitierte Patentliteratur
eine Zustandsbeobachtungseinheit (11) zum Beobachten, während des Betriebs des Roboters, der Positionen und Stellungen der Objekte und einer Zustandsvariablen, die mindestens eines von einer Zykluszeit zum Verstauen der Objekte in dem Behälter und eines Drehmoments und einer Vibration, die auftreten, wenn der Roboter die Objekte greift, umfasst;
eine Bestimmungsdaten-Einholungseinheit (12) zum Einholen von Bestimmungsdaten zum Bestimmen einer Spanne von jeweils der Zykluszeit, dem Drehmoment und der Vibration in Abhängigkeit von einem zulässigen Toleranzwert; und
eine Lerneinheit (13) zum Lernen des Betriebszustands des Roboters in Übereinstimmung mit einem Trainingsdatensatz, der aus einer Kombination aus der Zustandsvariablen und den Bestimmungsdaten gebildet wird.
die Lerneinheit (13) umfasst:
eine Belohnungsberechnungseinheit (14) zum Berechnen einer Belohnung basierend auf den Bestimmungsdaten; und
eine Wertfunktions-Aktualisierungseinheit (15) zum Aktualisieren einer Wertfunktion, die zum Schätzen der Greifreihenfolge der Objekte verwendet wird, um mindestens eines von der Zykluszeit, dem Drehmoment und der Vibration basierend auf der Belohnung zu reduzieren.
die maschinelle Lernvorrichtung (102) mit dem Roboter durch ein Netzwerk verbunden ist, und
die Zustandsbeobachtungseinheit (11) eine aktuelle Zustandsvariable durch das Netzwerk erhält.
Beobachten, während des Betriebs des Roboters, der Positionen und Stellungen der Objekte und einer Zustandsvariablen, die mindestens eines von einer Zykluszeit zum Verstauen der Objekte in dem Behälter und eines Drehmoments und einer Vibration, die auftreten, wenn der Roboter die Objekte greift, umfasst;
Einholen von Bestimmungsdaten zum Bestimmen einer Spanne von jeweils der Zykluszeit, dem Drehmoment und der Vibration in Abhängigkeit von einem zulässigen Toleranzwert; und Lernen des Betriebszustands des Roboters in Übereinstimmung mit einem Trainingsdatensatz, der aus einer Kombination aus der Zustandsvariablen und den Bestimmungsdaten gebildet wird.